Ellipse: Do you know the orbit of planets, moon, comets, and other heavenly bodies are elliptical? Mathematics defines an ellipse as a plane curve surrounding...
Last Modified 14-04-2025

Harvest Smarter Results!
Celebrate Baisakhi with smarter learning and steady progress.
Unlock discounts on all plans and grow your way to success!

Ellipse: Definition, Properties, Applications, Equation, Formulas
April 14, 2025
Altitude of a Triangle: Definition & Applications
April 14, 2025
Manufacturing of Sulphuric Acid by Contact Process
April 13, 2025
Refining or Purification of Impure Metals
April 13, 2025
Pollination and Outbreeding Devices: Definition, Types, Pollen Pistil Interaction
April 13, 2025
Acid Rain: Causes, Effects
April 10, 2025
Congruence of Triangles: Definition, Properties, Rules for Congruence
April 8, 2025
Complementary and Supplementary Angles: Definition, Examples
April 8, 2025
Nitro Compounds: Types, Synthesis, Properties and Uses
April 8, 2025
Bond Linking Monomers in Polymers: Biomolecules, Diagrams
April 8, 2025
Further Partition Values: The partition values have a wide range of applications in government policies to eradicate poverty and unemployment issues. Partition values are statistical measures for dividing a total number of distribution observations into a specified number of equal pieces. Quartiles, deciles, and percentiles are common partition values.
It is imperative to remember that the data should be sorted in ascending or descending order before the partition values are calculated. Quartiles divide data into four equal parts, deciles into \(10\) equal parts, and percentiles into one hundred equal parts. These partition values break down a more extensive distribution into smaller sections that are easier to measure, analyse, and understand.

The general definition of partition values is the magnitudes of those elements in an array that divide the number of items into some given number of equal pieces is known as partition values. These are the values of the items that divide the series into several pieces. Quartiles, quintiles, octiles, deciles, and percentiles are some such partition values in Statistics. These partition values give an overview of how the series is formed and are used to calculate dispersion and skewness.
Thus, partition values are the variate values dividing the total number of observations into equal parts. Whenever we have an observation that we want to divide, we can do so in a variety of ways.
We use the median when a single observation is divided into two equal portions. Quartiles are values that divide a particular set of observations into four equal parts using quartiles.
The data is divided into four equal parts by three quartiles.
Each component contains one-fourth of the data values. The first quartile \((Q_1)\) second quartile \((Q_2)\), and third quartile \((Q_3)\) are called the lower quartile, middle quartile (or median), and upper quartiles, respectively.
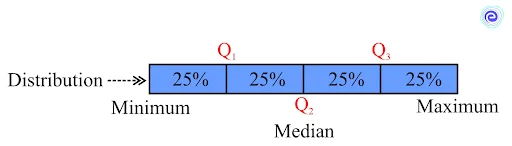
The first quartile \((Q_1)\) distinguishes the first one-fourth of the data from the upper three-fourths of the data, i.e., \(25\%\) of the data will fall below \((Q_1)\) and \(75\%\) will fall above it. The mathematical formula for \((Q_1)\) is given below, where N is the total number of observations in the data set.
\({Q_1} = 1 \times {\left( {\frac{{N + 1}}{4}} \right)^{th}}\) observation
The data is divided into two equal sections by the second quartile \((Q_2)\). It divides the initial half of the data from the second half of the data. \(50\%\) of the data falling below \((Q_2)\) and the other \(50\%\) falling above it. The median of the data is sometimes known as the second quartile \((Q_2)\).
\({Q_2} = 2 \times {\left( {\frac{{N + 1}}{4}} \right)^{th}}\) observation
The third quartile \((Q_3)\) divides the first three-quarters of the data from the last quarter. \(75\%\) of the data falling below \((Q_3)\) and \(25\%\) falling above it.
\({Q_3} = 3 \times {\left( {\frac{{N + 1}}{4}} \right)^{th}}\) observation
Steps to Calculate
The first quartile \((Q_1)\) of a distribution is equal to the median of the first half of the data set. The third quartile \((Q_3)\) is equal to the median of the second half of the data set; the second quartile \((Q_2)\) of a distribution is equal to the median of the given data set.

The interquartile range (IQR) measures the middle \(50\%\) of the data. It is the smallest of all statistical measures of dispersion and is calculated as the difference between the upper and lower quartiles.
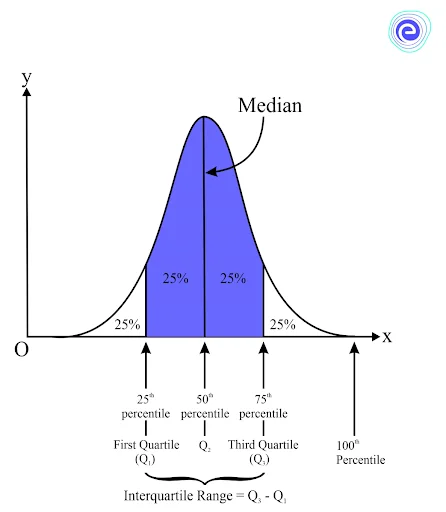
Interquartile range \(= Q_3 – Q_1\)
Where,
The formula to calculate the \(i^{th}\) quartile is given below:
\({Q_i} = l + \left( {\frac{{\frac{{in}}{4} – {c^i}}}{f}} \right)h\)
Where,
How to Calculate?
Following are the steps to calculate,
The partition values dividing data collection into \(10\) equal parts are called deciles. The first, second, third, ….. and ninth deciles are marked as \({{\text{D}}_1},\;{{\text{D}}_2},\;{{\text{D}}_3},\;{{\text{D}}_4},\; \ldots ..\;{{\text{D}}_9}\) and are referred to as \(1^{st}\) decile, \(2^{nd}\) decile, \(3^{rd}\) decile…., and \(9^{th}\) decile, respectively. For decile calculation, the data should be in ascending or descending order of magnitude.

The \(m^{th}\) decile for a grouped data is calculated by using the formula:
\({D_m} = l + \left( {\frac{{\frac{{mn}}{{10}} – {c^m}}}{f}} \right)h\)
Where,
Percentiles divide a distribution into \(100\) equal portions, dividing the entire data set into \(100\) groups. Each percentile consists of \(1\%\) of data. The total of \(99\) percentiles are denoted by the letters \({{\text{P}}_1},\;{{\text{P}}_2},\;{{\text{P}}_3},\;{{\text{P}}_4},\; \ldots \ldots \ldots {{\text{P}}{99}}\) and are referred to as the \(1^{st}\) percentile, \(2^{nd}\) percentile,…., \(99^{th}\) percentile.
It should be mentioned that before calculating percentiles, the data should be sorted in ascending or descending order of magnitude.
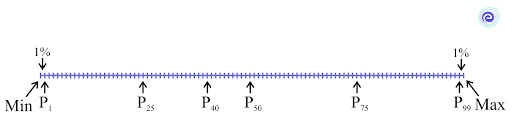
The \(k^{th}\) percentile in a data collection is the value that divides the data into two parts:
The median of the data, which divides the series into two equal portions, is equivalent to the \(50^{th}\) percentile. The formula for the \(i^{th}\) percentile \(P_i\) in mathematics is as follows:
\({P_i} = i \times {\left( {\frac{{N + 1}}{{100}}} \right)^{th}}\) observation
The \(k^{th}\) percentile for a groped data is calculated by using the formula:
\({P_k} = l + \left( {\frac{{\frac{{kn}}{{100}} – {c^k}}}{f}} \right)h\)
Where,
Below are a few solved examples that can help in getting a better idea.
Q.1. The marks of the Siva Ramakrishna in Mathematics examination is as follows:
\(70,\;66,\;48,\;64,\;59,\;74,\;51,\;40,\;62,\;77,\;60,\;33\)
Find the median marks by using the quartiles.
Ans:
Ascending order: \(33,\;40,\;48,\;51,\;59,\;60,\;62,\;64,\;66,\;70,\;74,\;77\)
\(\therefore\) Number of observations \((N) = 12\)
\({Q_1} = 2 \times {\left( {\frac{{N + 1}}{4}} \right)^{th}}\)
\({Q_2} = 2 \times {\left( {\frac{{12 + 1}}{4}} \right)^{th}} = {6.5^{th}}\) observation
\({Q_2} = {6^{th}}\) observation \(+ 0.5 \times {(}7^{th}\) observation – \(6^{th}\) observation\({)}\)
\(\therefore \,{Q_2} = 60 + 0.5 \times \left( {62 – 60} \right) = 61\)
Q.2. Find the \({6^{th}}\) decile for the data given below:
\(11,\;25,\;20,\;15,\;24,\;28,\;19,\;21\)
Ans:
Arrange the given data in ascending order as follows:
\(11,\;15,\;19,\;20,\;21,\;24,\;25,\;28\)
The formula to calculate the \({6^{th}}\) decile is given by
\({D_6} = 6 \times {\frac{{\left( {N + 1} \right)}}{{10}}^{th}}\) observation
\({D_6} = 6 \times {\frac{{\left( {8 + 1} \right)}}{{10}}^{th}}\) observation
\({D_6} = 6 \times {0.9^{th}} = {5.4^{th}}\) observation
\({D_6} = {5^{th}}\) observation \(+ 0.4 \times {(} {6^{th}}\) observation \(- {5^{th}}\) observation\({)}\)
\({D_6} = 21 + 0.4 \times \left( {24 – 21} \right)\)
\( = 21 + 0.4 \times 3 = 21 + 1.2\)
\(\therefore \,{D_6} = 22.2\)
Q.3. The following is the monthly income (in \(1000\)) of \(8\) factory workers. Find out how much \(P_{30}\) is worth.
\(10,\;14,\;36,\;25,\;15,\;21,\;29,\;17\)
Ans:
Ascending order: \(10,\;14,\;15,\;17,\;21,\;25,\;29,\;36\)
Number of observations \((N) = 8\)
The formula to calculate \(P_{30}\) is given by
\({P_{30}} = 30 \times {\left( {\frac{{N + 1}}{{100}}} \right)^{th}}\) observation
\({P_{30}} = 30 \times {\left( {\frac{{9 + 1}}{{100}}} \right)^{th}}\) observation
\({P_{30}} = {2.7^{th}}\) observation
\({P_{30}} = {2^{nd}}\) observation \(+ 0.7 \times {(} 3^{rd}\) observation \(- 2^{nd}\) observation\({)}\)
\({P_{30}} = 14 + 0.7 \times \left( {15 – 14} \right)\)
\({P_{30}} = 14 + 0.7\)
\(\therefore \,{P_{30}} = 14.7\)
Q.4. Compute \(Q_3\) for the wages in the given data.
| Wages | \(30 – 32\) | \(32 – 34\) | \(34 – 36\) | \(36 – 38\) | \(38 – 40\) | \(40 – 42\) | \(42 – 44\) |
| Labourers | \(12\) | \(18\) | \(16\) | \(14\) | \(12\) | \(8\) | \(6\) |
Ans:
| Wages | Labourers \(f\) | Cumulative frequency \((cf)\) |
| \(30 – 32\) | \(12\) | \(12\) |
| \(32 – 34\) | \(18\) | \(30\) |
| \(34 – 36\) | \(16\) | \(46\) |
| \(36 – 38\) | \(14\) | \(60\) |
| \(38 – 40\) | \(12\) | \(72\) |
| \(40 – 42\) | \(8\) | \(80\) |
| \(42 – 44\) | \(6\) | \(86\) |
From the data, \(n = 86\)
\(\frac{{n3}}{4} = \frac{{86 \times 3}}{4} = 64.5\)
The class \(38 – 40\) has a cumulative frequency \(72\), which is greater than \(\frac{{n3}}{4} = 64.5\)
The \(3^{rd}\) quartile class is \(38 – 40\)
So,
\(l = 38\)
\(h = 2\)
\(f = 12\)
\(cf = 60\)
So, \({Q_i} = l + \left( {\frac{{\frac{{in}}{4} – {c^i}}}{f}} \right)h\)
\({Q_3} = l + \left( {\frac{{\frac{{3n}}{4} – cf}}{f}} \right)h\)
\({Q_3} = 38 + \left( {\frac{{64.5 – 60}}{{12}}} \right) \times 2\)
\({Q_3} = 38 + 0.75 = 38.75\)
Q.5. Calculate \(D_5\) for the given data
| Income in thousands | \(0 – 4\) | \(4 – 8\) | \(8 – 12\) | \(12 – 16\) | \(16 – 20\) | \(20 – 24\) | \(24 – 28\) | \(28 – 32\) |
| Number of persons | \(10\) | \(12\) | \(8\) | \(7\) | \(5\) | \(8\) | \(4\) | \(6\) |
Ans:
| Income | Persons \((f)\) | Cumulative frequency \((cf)\) |
| \(0 – 4\) | \(10\) | \(10\) |
| \(4 – 8\) | \(12\) | \(22\) |
| \(8 – 12\) | \(8\) | \(30\) |
| \(12 – 16\) | \(7\) | \(37\) |
| \(16 – 20\) | \(5\) | \(42\) |
| \(20 – 24\) | \(8\) | \(50\) |
| \(24 – 28\) | \(4\) | \(54\) |
| \(28 – 32\) | \(6\) | \(60\) |
From the data, \(n = 60\)
\(\frac{{n5}}{{10}} = \frac{{60 \times 5}}{{10}} = 30\)
The class \(38 – 40\) has a cumulative frequency \(30\), equal to \(\frac{{n5}}{{10}} = 30\).
The \(5^{th}\) decile class is \(8 – 12\).
So,
\(l = 8\)
\(h = 4\)
\(f = 8\)
\(cf = 22\)
So, \({D_i} = l + \left( {\frac{{\frac{{in}}{{10}} – {c^i}}}{f}} \right)h\)
\({D_5} = 8 + \left( {\frac{{30 – 22}}{8}} \right) \times 4\)
\({Q_3} = 8 + 4 = 12\)
Q.6. Compute \(P_{61}\) for the data that hows the height of trees in a garden.
| Heights (in \(cm\)) | \(0 – 5\) | \(5 – 10\) | \(10 – 15\) | \(15 – 20\) | \(20 – 25\) | \(25 – 30\) |
| Number of plants | \(18\) | \(20\) | \(36\) | \(40\) | \(26\) | \(16\) |
Ans:
| Height | Plants\((f)\) | Cumulative frequency \((cf)\) |
| \(0 – 5\) | \(18\) | \(18\) |
| \(5 – 10\) | \(20\) | \(38\) |
| \(10 – 15\) | \(36\) | \(74\) |
| \(15 – 20\) | \(40\) | \(114\) |
| \(20 – 25\) | \(26\) | \(140\) |
| \(25 – 30\) | \(16\) | \(156\) |
Here, \(n = 156\)
\(\frac{{n61}}{{100}} = \frac{{156 \times 61}}{{100}} = 95.16\)
Class \(15 – 20\) has a cumulative frequency of \(114\), greater than \(95.16\).
The \(61^{st}\) percentile class is \(15 – 20\).
So,
\(l = 15\)
\(h = 5\)
\(f = 40\)
\(cf = 74\)
So, \({P_i} = l + \left( {\frac{{\frac{{in}}{{100}} – {c^i}}}{f}} \right)h\)
\({P_{61}} = 15 + \left( {\frac{{95.16 – 74}}{{40}}} \right) \times 5\)
\({P_{61}} = 15 + \frac{{21.16}}{{40}} \times 5\)
\({P_{61}} = 17.645\)
Statistics uses Partition Values to divide the total number of observations from distribution into a specific number of equal parts. The Partition values are the measures used to divide the total number of observations from distribution into a certain number of equal parts. Quartiles, Deciles, and Percentiles are some of the most often used partition values.
Partition values divide the series into the median, quadrant, pentant, octant, decadent and centatant, respectively, or \(2,\;4,\;5,\;8,\;10\) and \(100\) parts respectively. Any given observation is divided into \(100\) equal parts by a centile or a percentile. Deciles are the values that split any collection of observations into a total of \(10\) equal parts. Quartiles divide the data set into four points.

Students might be having many questions with respect to Further Partition Values. Here are a few commonly asked questions and answers.
Q.1. What are partition values?
Ans: The magnitudes of those elements in an array that divide the number of items into some given numbers of equal pieces are known as partition values.
Q.2. What are general partition values?
Ans: The are three general partition values.
Q.3. What will be the partition values in the case of a percentile?
Ans: In percentile, basically known as centile, the data will be divided into \(100\) equal parts. Each part will be equal to \(1\%\) of the data.
Q.4. What are partition values?
Ans: Partition Values are statistical measurements for dividing a total number of data points of distribution into a specified number of equal parts.
Q.5. What are quartiles?
Ans: A quartile divides data into four equal parts, such as lower quartile \((Q_1)\), an upper quartile \((Q_3)\) and a median \((Q_2)\).
We hope this information about the Further Partition Values has been helpful. If you have any doubts, comment in the section below, and we will get back to you.