
1PL বস্তুৰ সঁহাৰি তত্ত্বৰ সৈতে মানক পৰীক্ষাত শিক্ষাৰ্থীৰ নম্বৰ পূৰ্বানুমান কৰা
Embibeত, আমি শিক্ষাৰ্থীসকলক মানক পৰীক্ষাত তেওঁলোকৰ নম্বৰ উন্নত কৰাত সহায় কৰোঁ, শিক্ষা তত্ত্ব আৰু শিক্ষাগত গৱেষণাৰ পৰা অন্তৰ্দৃষ্টি আৰু আৰ্হি অন্তৰ্ভুক্ত কৰি।
বস্তুৰ সঁহাৰি তত্ত্বৰ [1, 2] নামৰ এনে এক বহুল ভাৱে ব্যৱহৃত আৰ্হিয়ে শিক্ষাৰ্থী গৰাকীৰ দক্ষতা বা সামৰ্থ্যৰ স্তৰ আৰু লগতে প্ৰশ্নটোৰ কঠিনতাৰ স্তৰ অনুমান কৰি এগৰাকী শিক্ষাৰ্থীৰ প্ৰশ্নৰ সঠিক উত্তৰ দিয়াৰ সম্ভাৱনাৰ পূৰ্বানুমান কৰে। ইয়াক প্ৰথমবাৰৰ বাবে 1960-ৰ দশকত প্ৰস্তাৱ কৰা হৈছিল আৰু ইয়াৰ বহুতো প্ৰকাৰ আজিও বিদ্যমান, যেনে 1PL আৰ্হি[2, 3] আৰু 2PL আৰ্হিl[2]।
1PL বস্তুৰ সঁহাৰি তত্ত্ব
1PL বা 1 স্থিতিমাপ বস্তুৰ সঁহাৰি তত্ত্ব আৰ্হি, যাক ৰাচ্ছ আৰ্হি বুলিও কোৱা হয়[3] নিম্নলিখিত ধৰণে বৰ্ণনা কৰা হৈছে।
ধৰি লোৱা i হৈছে এগৰাকী শিক্ষাৰ্থী, j হৈছে এটা প্ৰশ্ন। ধৰি লোৱা θi হৈছে শিক্ষাৰ্থীগৰাকীৰ ক্ষমতা আৰু βj হৈছে প্ৰশ্নটোৰ কঠিনতা স্তৰ। তেন্তে 1PL আৰ্হি অনুযায়ী iতম শিক্ষাৰ্থীয়ে jতম প্ৰশ্ন শুদ্ধকৈ উত্তৰ দিয়াৰ সম্ভাৱিতা Pij হ’ব logit(Pij) = i – j, য’ত logit ফাংচনটো logit(x) =(1+(-x))-1 ৰ দ্বাৰা দিয়া হয়।
1PL বস্তুৰ সঁহাৰি তত্ত্ব আৰ্হি ব্যৱহাৰ কৰি, আমি শিক্ষাৰ্থী এজনৰ ক্ষমতাৰ স্তৰ θi পূৰ্বানুমান কৰিব পাৰোঁ, যদি প্ৰতিটো চেষ্টা কৰা প্ৰশ্নৰ প্ৰতি শিক্ষাৰ্থীগৰাকীৰ প্ৰতিক্ৰিয়াৰ তথ্য দিয়া থাকে।
1PL বস্তুৰ সঁহাৰি তত্ত্বৰ বাবে এক গভীৰ শিক্ষা গাঁথনি
আমি দেখিবলৈ পাওঁ যে এক ড’মেইন-নিৰ্দিষ্ট পেৰামেট্ৰাইজেচনৰ সৈতে, 1PL আৰ্হিটো সঁচাকৈয়ে ল’জিষ্টিক প্ৰত্যাক্ৰমণ, ফলস্বৰূপে, আমি যিকোনো গভীৰ শিক্ষণ গাঁথনি ব্যৱহাৰ কৰি এনে আৰ্হি উপলব্ধি কৰিব পাৰোঁ। 1PL আৰ্হিৰ বাবে গভীৰ শিক্ষা গাঁথনি তলত চিত্ৰ 1ত দেখুৱা হৈছে।
চিত্ৰ 1: 1PL IRT আৰ্হি স্থিতিমাপ অনুমানৰ বাবে নিউৰেল নেটৱৰ্ক গাঁথনি
আমাৰ আৰ্হিটো কেৰাচত এক গভীৰ নিউৰেল নেটৱৰ্ক হিচাপে ৰূপায়ণ কৰা হয়। নিউৰেল নেটৱৰ্ক হিচাপে সমস্যাটো আৰ্হিকৰণ কৰাৰ সুবিধাবোৰ হৈছে:
● ইনপুটত হেৰুওৱা মানসমূহ নিয়ন্ত্ৰণ কৰাৰ সামৰ্থ্য – প্ৰতিজন ব্যৱহাৰকাৰীয়ে প্ৰতিটো প্ৰশ্ন চেষ্টা কৰাৰ প্ৰয়োজন নাই
● বৃহৎ সংখ্যাৰ উপভোক্তা আৰু সামগ্ৰীলৈ বিস্তাৰ হোৱাৰ ক্ষমতা
● গাঁথনিটো 2PL, 3PL, আৰু আন অধিক স্থিতিমাপ থকা বস্তুৰ সঁহাৰি তত্ত্ব আৰ্হিলৈ বিস্তাৰ কৰাৰ ক্ষমতা
আমি এই আৰ্হিক 1PL গভীৰ বস্তুৰ সঁহাৰি তত্ত্ব আৰ্হি বুলি প্ৰসঙ্গ কৰোঁ।
সত্যাপন
আৰ্হি নিৰ্মাণ কৌশল পৰীক্ষা আৰু সত্যাপন কৰাৰ বাবে, আমি এইদৰে অনুকাৰ তথ্য সৃষ্টি কৰোঁ :
● i N(0,1) :গড় 0 আৰু মানক বিচ্যুতি 1 ৰ সৈতে স্বাভাৱিক বিতৰণ ব্যৱহাৰ কৰি শিক্ষাৰ্থীৰ ক্ষমতা সৃষ্টি কৰা হয়
● j U(-1,1) : প্ৰশ্নৰ কঠিনতা মান -1 আৰু 1-ৰ মাজত সমানভাৱে সৃষ্টি কৰা হয়
● Pij= i – j : উপভোক্তাৰ ক্ষমতা আৰু সামগ্ৰী কঠিনতা ব্যৱহাৰ কৰি শুদ্ধ প্ৰতিক্ৰিয়া সম্ভাৱিতা গণনা কৰা হয় (1PL বস্তুৰ সঁহাৰি তত্ত্ব সমীকৰণ ব্যৱহাৰ কৰি)
● yijk Bern(Pij): দ্বিমূল প্ৰতিক্ৰিয়া (শুদ্ধ, ভুল) নমুনাকৰণ কৰা হয় বাৰ্ণ’লিৰ বিতৰণৰ পৰা সফলতা সম্ভাৱিতা Pij হৈছে, য’ত প্ৰতি সামগ্ৰী প্ৰতি শিক্ষাৰ্থী প্ৰতিক্ৰিয়াৰ সংখ্যা সলনি কৰিব পৰা যায়।
আমি 100টা প্ৰশ্ন, 100জন শিক্ষাৰ্থী অনুকাৰ কৰিছোঁ, এটা প্ৰতিক্ৰিয়া প্ৰতিজন শিক্ষাৰ্থীৰ, প্ৰতিটো প্ৰশ্নৰ বাবে।
আমি 1PL গভীৰ বস্তুৰ সঁহাৰি তত্ত্ব আৰ্হি অনুকাৰ তথ্য গোটৰ সৈতে খাপ খায়। নিউৰেল নেটৱৰ্কৰ প্ৰৱেশ হৈছে উপভোক্তা ভেক্টৰ (এক-তপত আৱদ্ধ) আৰু প্ৰশ্ন ভেক্টৰ (এয়াও এক-তপত আৱদ্ধ) আৰু ফলাফল হৈছে বস্তুৰ সঁহাৰি তত্ত্ব আৰ্হিৰ স্থিতিমাপ, যেনে সামগ্ৰীৰ কঠিনতা, শিক্ষাৰ্থীৰ ক্ষমতা আৰু শিক্ষাৰ্থীগৰাকীয়ে উত্তৰ শুদ্ধকৈ দিব নে নাই তাৰ অনুমান। নিউৰেল নেটৱৰ্কটো সম্পূৰ্ণ সংযুক্ত। ইয়াৰ দুটা প্ৰৱেশ স্তৰ, কঠিনতা আৰু ক্ষমতাৰ বাবে মধ্যম স্তৰ, আৰু অনুমানৰ বাবে এটা ফলাফল স্তৰ আছে।
নিউৰেল নেটৱৰ্কৰ ফলাফলৰ পৰা অনুকাৰ তথ্যৰ প্ৰকৃত ফলাফলৰ সৈতে আমি 1PL গভীৰ বস্তুৰ সঁহাৰি তত্ত্ব তুলনা কৰো।
ৰূপায়ণ
আৰ্হি: 1PL বস্তুৰ সঁহাৰি তত্ত্বৰ গাঁথনি ব্যাখ্যা কৰা হয় NNৰ গঠনতা ব্যৱহাৰ কৰি, কেৰাচ কাৰ্যকৰি API ব্যৱহাৰ কৰি। সামগ্ৰিক আৰ্হিটো গঠন কৰা হয় ঘন স্তৰ দ’ম কৰি, ইয়াত 1PL আৰ্হিৰ বাবে 2টা ঘন স্তৰ, প্ৰতিটো এটা উপভোক্তা বা সামগ্ৰী স্থিতিমাপ প্ৰতিনিধিত্ব কৰা যি এগৰাকী উপভোক্তাই (i) এটা সামগ্ৰীৰ (j) প্ৰতি প্ৰতিক্ৰিয়া কৰাৰ সম্ভাৱনা (Pij) প্ৰভাৱিত কৰাৰ বাবে গুৰুত্বপূৰ্ণ।
অধি স্থিতিমাপ: তলত দিয়া ডিফল্ট স্থিতি ব্যৱহাৰ কৰা হয় প্ৰতিটো ঘন স্তৰত
● কাৰ্নেল আৰু বায়াচ ইনিচিয়েলাইজাৰ: Normal (0,1)
● l1/l2 ৰেগুলাৰাইজেচন: l_1=0, l_2=0
● ক্ৰিয়া ৰেগুলাৰাইজাৰ: l_1=0, l_2=0
ওপৰৰ স্থিতি ডেভেল’পাৰ এগৰাকীয়ে সলনি কৰিব পাৰে বা শ্ৰেষ্ঠ গঠন অৰ্জন কৰিব পাৰে স্থিতিৰ স্থানত সন্ধান কৰি। তেন্তে তথ্য এক আগন্তুক ব্ল’গত থাকিব। এই নিৰ্ধাৰিত আৰ্হি যথেষ্ট নমনীয় হয় নিজৰ ব্যৱহাৰ দুটা বা তিনিটা স্থিতিমাপলৈ বিস্তাৰ কৰিব পৰাকৈ, যেনে ভেদাভেদ আৰু অনুমান ক্ষমতা, আৰু ইয়াৰ ফলত, নিউৰেল গাঁথনি সন্ধান ক্ষমতাৰ সৈতে এক বিস্তৃত আৰ্হি সীমিত কৰিব পৰা যায় এক বা দুই PL আৰ্হি হিচাপে কাম কৰিবলৈ।
পৰীক্ষাগত ফলাফল
তলত দিয়া লেখে সহ-সম্পৰ্ক প্ৰদৰ্শন কৰে ইয়াৰ মাজত:
● আনুমানিক কঠিনতা বনাম প্ৰকৃত কঠিনতা স্তৰ, 0.9857 পিয়াৰচন সহ-সম্পৰ্ক সহগ সৈতে।
● আনুমানিক ক্ষমতা বনাম প্ৰকৃত ক্ষমতা স্তৰ, 0.9954 পিয়াৰচন সহ-সম্পৰ্ক সহগ সৈতে।
● আনুমানিক সম্ভাৱিতা প্ৰতিটো প্ৰশ্ন শুদ্ধকৈ উত্তৰ দিয়া বনাম প্ৰকৃত সম্ভাৱিতা, 0.9926 পিয়াৰচন সহ-সম্পৰ্ক সহগ সৈতে।
গভীৰ বস্তুৰ সঁহাৰি তত্ত্ব আৰ্হিৰ পৰা যি 1PL তথ্যৰ ওপৰত প্ৰশিক্ষিত, 1PL DIRT আৰ্হিৰ log সম্ভাৱনা হৈছে 0.587।
আমি দেখা পাইছোঁ, যে তিনিওটা ক্ষেত্ৰত আমি এক ভাল সহ-সম্পৰ্ক পাইছোঁ, যি উল্লেখ কৰে যে আমাৰ 1PL গভীৰ বস্তুৰ সঁহাৰি তত্ত্ব আৰ্হিৰ সফল হৈছে ভাল সঠিকতাৰ সৈতে কঠিনতা, ক্ষমতা আৰু টেষ্ট স্ক’ৰ অনুমান কৰাত।
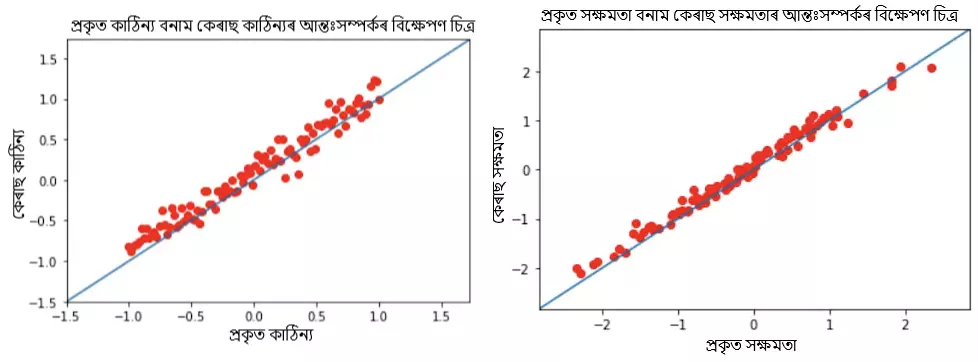
চিত্ৰ 1: প্ৰকৃত বনাম লব্ধ কেৰাছ নমুনাৰ কাঠিন্য আৰু সক্ষমতাৰ আন্তঃসম্পৰ্কৰ বিক্ষেপণ চিত্ৰ
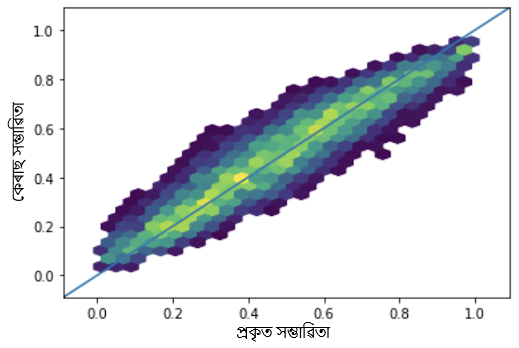
চিত্ৰ 2: প্ৰশ্নবোৰৰ সঠিক উত্তৰ দিয়াৰ প্ৰকৃত সম্ভাৱনা বনাম আমাৰ প্ৰশিক্ষিত কেৰাছ নমুনাৰ পৰা প্ৰাপ্ত সম্ভাৱনাৰ হেক্সবিন লেখচিত্ৰ
সামৰণি
আমি দেখুৱাইছোঁ যে অনুকাৰৰ ভিত্তিত, 1PL বস্তুৰ সঁহাৰি তত্ত্ব আৰ্হি ৰূপায়ণ কৰিব পাৰি এক গভীৰ শিক্ষা আৰ্হিৰ যোগেদি। বস্তুৰ সঁহাৰি তত্ত্ব স্থিতিমাপ ব্যৱহাৰ কৰি, আমি শিক্ষাৰ্থীৰ ক্ষমতা আৰু প্ৰশ্নৰ কঠিনতা স্তৰৰ এক ভাল অনুমান পাব পাৰোঁ আমাৰ 1PL বস্তুৰ সঁহাৰি তত্ত্ব ভিত্তিক আৰ্হি ব্যৱহাৰ কৰি। এই অনুমানবোৰক, আগলৈ, ব্যৱহাৰ কৰিব পাৰি অভিযোজী পৰীক্ষা সৃষ্টি, লক্ষ্য নিৰ্ধাৰণ আৰু আন তল শাৰীৰ প্ৰক্ৰিয়াত।
প্ৰসঙ্গ
- Frank B. Baker. “The basics of item response theory.” ERIC, USA, 2001
- Wikipedia. Item Response Theory https://en.wikipedia.org/wiki/Item_response_theory
- Georg Rasch. “Studies in mathematical psychology: I. Probabilistic models for some intelligence and attainment tests.” 1960.
- Keras Deep Learning framework: Keras




















