
পাতনি:
Embibeৰ জ্ঞান লেখ হৈছে 75,000+ সংযোগস্থলৰে গঠিত এটা পাঠ্যক্ৰম-অজ্ঞানমূলক বহুমাত্ৰিক গ্ৰাফ, প্ৰত্যেকেই একাডেমিক জ্ঞানৰ এটা ভিন্ন এককক প্ৰতিনিধিত্ব কৰে, যাক ধাৰণা বুলিও কোৱা হয়, আৰু ধাৰণাসমূহ যিয়ে ইহঁতৰ মাজত লাখ লাখ আন্তঃসংযোগ দেখুৱাইছে ইয়াৰ পৰিৱৰ্তে অন্যান্য ধাৰণাসমূহৰ সৈতে জড়িত।
Embibeত ইয়াৰ সমল সম্প্ৰসাৰিত কৰাৰ লগে লগে, জ্ঞান লেখো নিৰন্তৰ বিকশিত হৈ আছে। ঐতিহাসিকভাৱে, ইয়াক লেখৰ কিছু অংশ নিহিত কৰিবলৈ বুদ্ধিময় স্বয়ংক্ৰিয়তাৰ সৈতে বিশেষজ্ঞ অনুষদৰ মানৱ প্ৰচেষ্টা ব্যৱহাৰ কৰি নিৰ্মাণ কৰা হৈছে। অৱশ্যে, Embibeে গৱেষণাত বিনিয়োগ কৰি আছে যাৰ উদ্দেশ্য হৈছে লেখৰ নতুন নোডবোৰ স্বয়ংক্ৰিয়ভাৱে আৱিষ্কাৰ কৰা আৰু শৈক্ষিক জ্ঞান বৰ্ণালীৰ আনকি অধিক অংশ সামৰি লোৱাৰ বাবে লেখ সম্প্ৰসাৰিত কৰা। একাডেমিকভাৱে পৃথক কৰা বাক্যাংশ এক্সট্ৰেক্টৰে আমাক লেবেল যুক্ত তথ্য সংহতি আৰু BERT আধাৰিত আৰ্হি ব্যৱহাৰ কৰি জ্ঞান লেখত নতুন নোড আৱিষ্কাৰ কৰিবলৈ আৰু আমাক সেই বাক্যাংশবোৰৰ বাক্যাংশ আৰু প্ৰাসংগিকতাৰ স্তৰ প্ৰদান কৰিবলৈ সক্ষম কৰে।
শৈক্ষিকভাৱে পৃথক বাক্যাংশ এক্সট্ৰেক্টৰ:
একাডেমিকভাৱে প্ৰভেদিত ব্যাক্যাংশ এক্সট্ৰেক্টৰ (এ.ডি.পি.ই.), হৈছে এক একাডেমিক কিতাপ এখনৰ পৰা পাঠৰ গুৰুত্বপূৰ্ণ তাল বোৰৰ এক স্বয়ংক্ৰিয় নিম্নৰেখিত, কিতাপখন পঢ়াৰ সময়ত এজন শিক্ষাৰ্থীয়ে কেনেদৰে গুৰুত্বপূৰ্ণ ধাৰণাবোৰ ৰেখাঙ্কিত কৰে তাৰ সৈতে সাদৃশ্যপূৰ্ণ। ইয়াৰ প্ৰাথমিক লক্ষ্য হৈছে অসংগঠিত পাঠৰ পৰা ধাৰণাবোৰ আহৰণ কৰা, এই ধাৰণাটোৰ দ্বাৰা চালিত যে বেছিভাগ ধাৰণাকিতাপ পাঠৰ উপ-তাল হিচাপে চিনাক্ত কৰিব পাৰি।
মূল ব্যাক্যাংশ এক্সট্ৰেক্টৰ আৰু নামযুক্ত সত্তা চিনাক্তকৰণৰ ওপৰত বিস্তৃত কাৰ্য আছে। অৱশ্যে, একাডেমিক কিতাপ এখনৰ পৰা ধাৰণাবোৰ স্বয়ংক্ৰিয়ভাৱে আহৰণ কৰাটো এক প্ৰত্যাহ্বানমূলক কাম যিয়ে সীমিত পৰিধি দেখিছে। সংজ্ঞা অনুসৰি ধাৰণা আহৰণ, সম্পূৰ্ণ প্ৰকৃতিৰ, অৰ্থাৎ। সকলো ধাৰণা আহৰণ কৰিব লাগিব, যিবোৰ অধ্যায়ৰ ধাৰণা পদানুক্ৰমৰ অংশ, অধ্যায়টোৰ সন্দৰ্ভত তেওঁলোকৰ সহ-ঘটনা আৰু প্ৰাসংগিকতা বৰ্ণনা কৰে। ই মুখ্য-বাক্যাংশ আহৰণৰ পৰা পৃথক কিয়নো পিছৰটোৱে এটা প্ৰবন্ধ বৰ্ণনা কৰা শীৰ্ষ-এন কীৱৰ্ডৰ ওপৰত গুৰুত্ব দিয়ে, প্ৰাসংগিকতাৰ কোনো অৰ্থপূৰ্ণ শ্ৰেণীবিন্যাসত নহয়। তদুপৰি, ই নামযুক্ত সত্তা নিষ্কাশনৰ পৰাও পৃথক কিয়নো পিছৰ কামটোৱে পূৰ্ব-নিৰ্ধাৰিত শ্ৰেণীৰ (যেনে: অৱস্থান, ব্যক্তি, অৰ্গ) সত্তাবোৰৰ ব্যক্তিগত উদাহৰণ বোৰ সাধাৰণতে চুটি পাঠযেনে বাক্যৰ পৰা আহৰণ কৰাৰ ওপৰত গুৰুত্ব দিয়ে, যিটো আমাৰ অনন্য, সম্পৰ্কিত ধাৰণাবোৰ আহৰণ কৰাৰ লক্ষ্যৰ বিপৰীতে অৰ্থগত পদানুক্ৰম গঠন কৰাটো প্ৰয়োজনীয় নহয়। আমি ধ্ৰুপদী যন্ত্ৰ শিক্ষণ আৰু গভীৰ শিক্ষণ-আধাৰিত তত্বাৱধান/নিৰীক্ষণ নকৰা কৌশল ব্যৱহাৰ কৰি এনে কাৰ্য্য গঠনৰ দ্বাৰা অনুপ্ৰাণিত তত্ত্ববিদ্যা-আধাৰিত ধাৰণা আহৰণৰ বাবে পদ্ধতি উপস্থাপন কৰোঁ।
গৱেষণা পদ্ধতি:
আমাৰ পৰীক্ষাবোৰে ADPE. তথ্যসংহতিত প্ৰদৰ্শন উন্নত কৰাৰ বাবে অত্যাধুনিক গভীৰ শিক্ষণ কৌশলবোৰ ব্যৱহাৰ কৰে, যেনে BERT (ট্ৰেন্সফৰ্মাৰৰ পৰা দ্বিমুখী এনকোডাৰ উপস্থাপন), LSTM (দীৰ্ঘম্যাদী স্মৃতি), CNN (আৱৰ্তিত স্নায়ৱিক নেটৱৰ্ক) দুটা প্ৰাথমিক শ্ৰেণীবিভাজন প্ৰস্তুতিত। প্ৰথমটো হ’ল নামযুক্ত সত্তা চিনাক্তকৰণৰ বাবে ক্ৰম টেগিং আৰু দ্বিতীয়টো হৈছে পৰিসাংখ্যিক, অৰ্থগত, প্ৰাকৃতিক ভাষা প্ৰক্ৰিয়াকৰণ, পাঠ সুবিধাৰ সৈতে প্ৰাৰ্থী এন-গ্ৰাম সৃষ্টি কৰিবলৈ এন-গ্ৰাম শ্ৰেণীবিভাজন আৰু গভীৰ স্নায়ৱিক নেটৱৰ্ক ব্যৱহাৰ কৰি সেইবোৰৰ শ্ৰেণীবিভাজন কৰা।
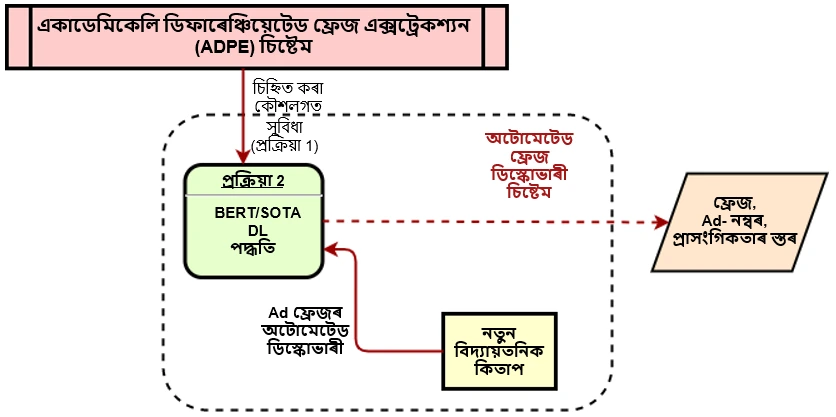
আমি BERT অনাৱদ্ধ আৰ্হিটো বৰ্ধিত শব্দৰ সৈতে ব্যৱহাৰ কৰোঁ আৰু বৈজ্ঞানিক আলোচনী আৰু কিতাপ অধ্যায়ত সূক্ষ্ম ভাৱে সমন্বিত কৰোঁ। তদুপৰি, নিৱেশিত পাঠৰ পৰা ধাৰণাবোৰ আৱিষ্কাৰ কৰিবলৈ সকলো এনকোডাৰ স্তৰ উপস্থাপনক এক সীমাবদ্ধ-পৰিৱৰ্তন (BOI এনক’ডিং) চি.আৰ.এফ. (চৰ্ত সাপেক্ষ যাদৃচ্ছিক ক্ষেত্ৰ) ক্ৰমিক টেগাৰত প্ৰদান কৰা হয়।
কিয় CRF (চৰ্তসাপেক্ষ যাদৃচ্ছিক ক্ষেত্ৰ):
- CRF.-এ ক্ৰমটোৰ লগ সম্ভাৱনা সৰ্বাধিক কৰে আৰু ক্ৰম টেগবোৰৰ সৰ্বাধিক সম্ভাৱনা অনুমান প্ৰস্তুত কৰে।
- CRF সীমাবদ্ধতাই নিশ্চিত কৰে যে কেৱল বৈধ মাল্টিগ্ৰাম ক্ৰম লেবেলবোৰ লেবেল এনক’ডিঙৰ দ্বাৰা নিৰ্ধাৰিত অনুসৰি সৃষ্টি কৰা হয় – (যেনে: বি.ও.আই. এনক’ডিঙে এটা ক্ৰমত সত্তা বিভাজনৰ গেৰাণ্টি দিয়ে কিন্তু কিছুমান ব্যাকৰণ নিয়ম আছে যাক পূৰণ কৰিব লাগিব)।
- CRF ক্ৰমিক লগ সম্ভাৱনা লোকচান হিচাপে ব্যৱহাৰ কৰা হয় যি সাধাৰণ ৰৈখিক স্তৰৰ তুলনাত নেটৱৰ্কৰ (যদি হিমায়িত নোহোৱাকৈ ৰখা হয়) আৱেশিত লগইটবোৰ ভালদৰে অপ্টিমাইজ কৰে যিটো CRF সূক্ষ্ম টিউন কৰা ৰৈখিক স্তৰৰ সৈতে সাধাৰণ ৰৈখিক স্তৰৰ আৱেশ তুলনা কৰি নিশ্চিত কৰিব পাৰি।
সাৰাংশ:
জ্ঞান লেখ হৈছে Embibeৰ সকলো সামগ্ৰীৰ মেৰুদণ্ড। গতিকে জ্ঞান লেখ সম্পূৰ্ণ কৰাটো আমাৰ প্ৰাথমিক কাম। এই কামটোৱে আমাক জ্ঞানৰ লেখ বজাই ৰখাত আৰু অতি নিম্নতম মানৱ হস্তক্ষেপৰ সৈতে ইয়াক দ্ৰুতগতিত সম্প্ৰসাৰিত কৰাত সহায় কৰিছিল।
এই অনুশীলনী BERT ব্যৱহাৰ কৰি প্ৰশিক্ষণ দিয়া হয় আৰু তথ্য প্ৰক্ৰিয়াকৰণ, আৰ্হিকৰণ আৰু বৈধকৰণৰ বাবে অন্যান্য কৌশল ব্যৱহাৰ কৰা হয়। কেঁচা শৈক্ষিক পাঠৰ পৰা গুৰুত্বপূৰ্ণ একাডেমিক শব্দবোৰ আৱিষ্কাৰ কৰাৰ বাবে একাডেমিকভাৱে পৃথকীকৃত বিশুদ্ধ এক্সট্ৰেক্টৰ ব্যৱহাৰ কৰা হৈছে আৰু সেয়েহে, আমি বিভিন্ন উৎসৰ পৰা প্ৰদান কৰা পাঠ্য তথ্যৰ পৰা ধাৰণা অনুসন্ধানৰ প্ৰক্ৰিয়াটো স্বয়ংক্ৰিয় কৰিছোঁ।
তথ্যসূত্ৰ:
[1] Devlin Jacob, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805 (2018).(2018).
[2] Zhiheng Huang, Wei Xu, Kai Yu. Bidirectional LSTM-CRF Models for Sequence Tagging. arXiv preprint arXiv:1508.01991 (2015)
[3] William Cavnar and John Trenkle. N-Gram-Based Text Categorization. In Proceedings of SDAIR-94, 3rd Annual Symposium on Document Analysis and Information Retrieval (Las Vegas, US, 1994), pp. 161–175.




















