
Introduction
Embibe’s Knowledge Graph (KG) is a curriculum-agnostic multi-dimensional graph that consists of 75,000+ nodes. Each node represents a discrete unit of academic knowledge, also called concepts. The Knowledge Graph also has hundreds of thousands of interconnections (relations) between the nodes showing how concepts are not independent but are instead related to other concepts.
The interconnections between nodes are assigned a type based on the kind of relationship that exists between them. Incomplete knowledge graphs and missing relationships have been one of known problems among researchers. However, as Embibe expands its content, there is a need to automate the process. Given the availability of interactions data on the KG concepts for millions of students over the last 8 years, and by leveraging techniques from graph theory and Natural language understanding, it is possible to auto-classify the relationships into one of N classes.
Types of Relationships
In the Embibe knowledge graph, we have 16 different relations between concepts. A prerequisite relation is one of these relations. All the prerequisites to learn before learning a particular concept are given in our knowledge graph nodes by this relationship. Generally, a student learns prerequisites first before learning any concept. It helps them to understand the concept better. We analyze billions of practice and test attempts from millions of students, to derive the patterns of concept mastery and the learning paths. These patterns are used to establish empirical causations between concepts. This hidden trait of the data helped us to find the common learning path followed by the student in achieving their goal. We used these common learning paths to find the prerequisite concepts based on a scoring method.
Research Approaches
We extend state-of-the-art techniques of deep knowledge tracing with the knowledge infusion from knowledge graphs to predict concept mastery for students. We also handle the cold start problem by populating conditional concept masteries based on historical priors. Embibe is uniquely positioned through semantic integration because of the behavioural calibration of students and its reflection on the knowledge graph concepts. These behavioural traits of concepts are also leveraged in classifying the relationship between concepts.
Extending Knowledge Graphs
We already have many relationships among knowledge graph node concepts. Whenever a graph introduces a new concept, we need to define its relationships to other concepts. This becomes a very important exercise because of the complexity of the task. Any wrong relationship tagging can result in redirecting users in the wrong direction.
At Embibe, we want to launch our product in different languages and for different curriculums. We need to extend our KG for these new concepts. To date, we were fully dependent on Faculties for new concept discovery and their relationship finding with other concepts and existing relationship validation. These tasks are very tedious as well as slow. Since the scale of the data has been increasing exponentially, this becomes very challenging for us. Also, there is a human bias in the whole data preparation process.
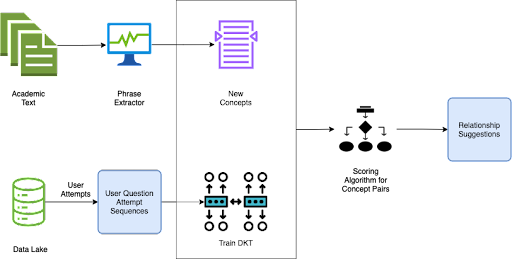
We have seen before learning any concept, students learn the corresponding prerequisites. So students’ attempt sequence (Attempted Question Sequence) will have the concepts after their prerequisite concepts. We are finding an attempted question sequence pattern to get the common trait of the student that is impacting the student’s improvement in accuracy using a knowledge graph example.
To solve this effectively, DKT (Deep Knowledge Tracing) (LSTM) is being used with User Attempt Data and accuracy to see which concepts/attempt pattern has more effect on accuracy, as a sequence classification problem. Finally, the trained DKT model has been used for relationship ranking for new concepts. Later this ranking is used for new relationship suggestions between Knowledge Graph nodes.
Summary
Knowledge Graph is the backbone for all Embibe’s products. So knowledge graph completion is our primary task. This work helped us maintain the Knowledge graph and extend it rapidly with minimal manual interventions.
Finally, This is an open problem for us to explore new latent relationships among concepts through semantic technology. We have automated the process of concept finding from a given textual data from different sources. Later we find the relations of these newly found concepts with the existing concepts using this technique. This method also can be extended for Knowledge Graph validation.
References
- Chris Piech, Jonathan Spencer, Jonathan Huang, Surya Ganguli, Mehran Sahami, Leonidas J. Guibas, andJascha Sohl-Dickstein. Deep knowledge tracing.CoRR, abs/1506.05908, 2015. URLhttp://arxiv.org/abs/1506.05908.
- K. Greff, R. K. Srivastava, J. Koutník, B. R. Steunebrink and J. Schmidhuber, “LSTM: A Search Space Odyssey,” in IEEE Transactions on Neural Networks and Learning Systems, vol. 28, no. 10, pp. 2222-2232, Oct. 2017, doi: 10.1109/TNNLS.2016.2582924.
- Faldu, Keyur, Amit Sheth, Prashant Kikani, and Hemang Akabari. “KI-BERT: Infusing Knowledge Context for Better Language and Domain Understanding.” arXiv preprint arXiv:2104.08145 (2021).
- Sheth, Amit, Manas Gaur, Kaushik Roy, and Keyur Faldu. “Knowledge-intensive Language Understanding for Explainable AI.” IEEE Internet Computing 25, no. 5 (2021): 19-24.




















