
Embibe is all about the personalisation of education, and our technology is very good at serving the right piece of content, to the right student, at the right time. It is for this reason having access to a large dataset of usable content, especially questions, is very important to us. Historically, human data entry operators prepared Embibe’s dataset of questions. They would source questions from various freely available question sets online or via tie-ups with our partner institutions.
The core motivation of the auto-generation of questions is to reduce the dependency of students on their teachers/mentors. To truly scale education to millions of students, they should be able to practice concepts/topics and measure their progress independently without any external help. Access to unlimited questions empowers intelligent assessment creation[3], diagnosing students [4] or serving personalised content for delivering learning outcomes [5][6]. Natural text generation of questions and allowing students to practice and evaluate their progress is a step towards that.
However, to ensure that students on our platform always have questions on all topics they need to improve, Embibe is investing in AI that automatically generates new questions and their related answers. This work involves borrowing ideas from content clustering, topic modelling, cutting edge Natural Language Generation(NLG) and solver technology.
Objective
We at Embibe propose a framework of learning through practising and mastering the concepts by answering the questions, an indirect way to remember and understand the concepts. Automatic Question Generation is the process that takes the learning text as input and generates questions on which students can apply their knowledge to practice and learn.
Automatic Question Generation is part of Natural Language Processing (NLP). It is an area of research where many researchers have presented their work. It is yet to achieve higher accuracy. Many researchers have worked in Automatic Question Generation through NLP, and numerous techniques and models have been developed to generate the different types of questions automatically via NLG Natural Language Generation.
Approach
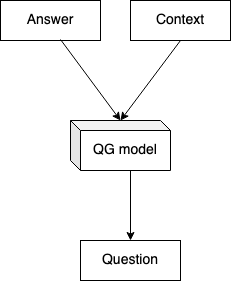
The diagram in Fig 1 shows a very high-level approach to the architecture of Auto Question Generation. The Auto Question Generation uses the transformer models’ cutting-edge variants and NLP techniques. It also leverages the research work being done on syntactic and semantic understanding of the text to enhance the quality and complexity of the generated questions.

The Automatic Question Generation as a pipeline includes many components like text processing, feature extraction and engineering, model building and training, model evaluation, annotation, and some standard ML techniques.
We have used 20+ different open-source datasets like ARC, DROP, QASC, SciQ, SciTail, SQuAD, Google NQ, and Embibe-owned datasets to train our QA model. We have also used different types of questions like boolean, span-based, fill-in-the-blanks, multiple choice questions etc. Question difficulty is derived based on the syntactic formation of a question; multi-hop reasoning is needed to derive the answer and complexity of the underlying concept. We also use knowledge graphs to infuse relevant knowledge into QG models inspired by KI-BERT[1]. We leverage natively built Natural Language Understanding techniques to improve the performance of question generation.
To generate text, we can use generative models like T5[2], which can generate the question from a given context and answer. We use the T5 model to generate subjective questions from a given text input (Doc2Query in search). Doc2query model does not need an answer as input. It only needs text, and it will generate all possible queries. Our model not only generates queries for a text but can also generate a title for the text paragraph. Also, it can generate paraphrases for a given query. Here’s what the flow would look like.
Outcome
Embibe AI platform leverages this work to generate as many questions as possible for students from textbooks. Considering all the grades, goals, exams, and state boards, till now, we have generated ~125k questions from NCERT books of grades 6 to 12. We have the capability to natural language generation for questions from any free-form learning text.
This system can be leveraged to any domain and target to achieve life and learning outcomes in real-world scenarios. We are on a path to make the model and system more cutting-edge in the area of advanced NLP and make it domain specific.
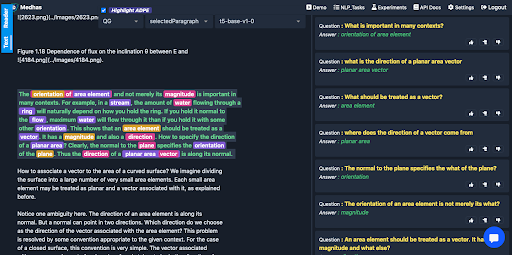
Here, we have provided some examples of the domain-specific input given and set of generated questions.
Academic Text

Generated Questions
References
[3] Desai, Nishit, Keyur Faldu, Achint Thomas, and Aditi Avasthi. “System and method for generating an assessment paper and measuring the quality thereof.” U.S. Patent Application 16/684,434, filed October 1, 2020.
[4] “Autogeneration of Diagnostic Test and Their Quality Evaluation – EDM:2020”, EDM 2020 presentation, Jul 2020, https://www.youtube.com/watch?v=7wZz0ckqWFs
[5] Thomas, Achint, Keyur Faldu, and Aditi Avasthi. “System and method for personalized retrieval of academic content in a hierarchical manner.” U.S. Patent Application 16/740,223, filed October 1, 2020.
[6] Faldu, Keyur, Achint Thomas, and Aditi Avasthi. “System and method for recommending personalized content using contextualized knowledge base.” U.S. Patent Application 16/586,512, filed October 1, 2020.




















