
Introduction
Embibe’s Knowledge Graph is a curriculum-agnostic multi-dimensional graph consisting of more than 75,000+ nodes, each representing a discrete unit of academic knowledge, also called concepts and the hundreds of thousands of interconnections between them showing how concepts are not independent but are instead related to other concepts.
As Embibe expands its content, the Knowledge diagram is also constantly evolving. Historically, it has been built using expert faculties’ manual effort and smart automation to curate portions of the graph. However, Embibe is investing in research that aims to automatically discover new nodes of the graph and extend the graph to cover even more parts of the academic knowledge spectrum.
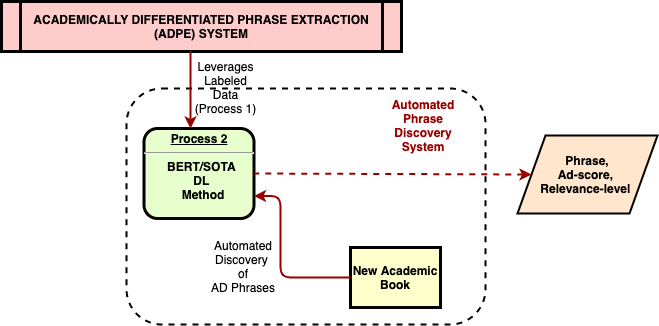
The Academically Differentiated Phrase Extractor enables us to discover new nodes in a Knowledge Graph by using a labelled data set and a BERT-based model. It gives us phrases and the relevance levels of those phrases.
Academically Differentiated Phrase Extractor
Academically Differentiated Phrase Extractor (ADPE), is an automated underlining of important spans of text from an academic book, analogous to how a student underlines important concepts while reading the book. Its primary aim is to extract concepts from unstructured text, driven by the hypothesis that most concepts can be identified as a subspace of the book text.
There is extensive work on key-phrase extraction and named entity recognition. However, automatic extraction of the concepts from an academic book is a challenging task that has seen limited coverage. Concept extraction, by definition, is exhaustive in nature, i.e. all concepts that need to be extracted, which are part of a chapter’s concept hierarchy, describing their co-occurrence and relevance in the context of the chapter. It differs from key-phrase extraction because the latter focuses on top-n keywords describing an article in the knowledge graph, not necessarily in any meaningful hierarchy of relevance.
Moreover, it also differs from named entity extraction as the latter task focuses on extracting individual instances of entities belonging to pre-specified classes (e.g., LOCATION, PERSON, ORG) from generally shorter texts like sentences not necessarily constituting a semantic hierarchy as opposed to our goal to extract unique, related concepts. We present approaches for ontology-based concept extraction motivated by such task formulations using classical machine learning and deep learning-based supervised/unsupervised techniques.
Research Approaches
Our experiments leverage state-of-the-art deep learning techniques to improve performance on ADPE datasets, such as BERT (Bidirectional Encoder Representations from Transformers), LSTM (Long Short-Term Memory), CNNs (Convolutional Neural Network) in two primary classification formulations.
First is Sequence Tagging for Named Entity Recognition. The second is n-gram classification to generate candidate n-grams with statistical, semantic, natural language processing, and text features and classify them using Deep Neural Network.
We leverage BERT uncased model with augmented vocab and fine-tuned on scientific journals and book chapters. Furthermore, all encoder layer representations are fed into a constrained-transition (BIO encoding) CRF (Conditional random field) sequential tagger to discover concepts from the input text.
Why CRF (Conditional Random Field)
- CRF maximizes the log-likelihood of the sequence and produces the Maximum Likelihood Estimate of the sequence tags.
- CRF constraints ensure that only valid multigram sequence labels are generated as ordained by the label encoding – (e.g., BIO encoding guarantees entity segmentation in a sequence but has some grammar rules which must be fulfilled).
- CRF sequential log-likelihood is used as loss which better optimizes the network’s (if left unfrozen) output logits than an ordinary linear layer, as can be confirmed by comparing the output of an ordinary linear layer with CRF fine-tuned linear layer.
Summary
The Knowledge Graph is the backbone for all Embibe’s products. So knowledge graph completion is our primary task. This work helped us to maintain the Knowledge graph and extend it rapidly with minimal manual interventions.
In this exercise, the model is trained using BERT and other techniques for data processing, modelling and validation. Academically Differentiated Phrase Extractor is being used for underlining the important academic words from the raw academic text. Thus, we have automated the process of concept finding from a given textual data from different sources.
References
[1] Devlin Jacob, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805 (2018).
[2] Zhiheng Huang, Wei Xu, Kai Yu. Bidirectional LSTM-CRF Models for Sequence Tagging. arXiv preprint arXiv:1508.01991 (2015)
[3] William Cavnar and John Trenkle. N-Gram-Based Text Categorization. In Proceedings of SDAIR-94, 3rd Annual Symposium on Document Analysis and Information Retrieval (Las Vegas, US, 1994), pp. 161–175.
[4] Gaur, Manas, Keyur Faldu, and Amit Sheth. “Semantics of the Black-Box: Can knowledge graphs help make deep learning systems more interpretable and explainable?.” IEEE Internet Computing 25, no. 1 (2021): 51-59.




















