
When it comes to assessing students, test paper-based evaluation remains the most popular method across the world. A test paper aims to evaluate a large population, judge them on their academic ability and classify them into different ability bands. Hence, the test paper must incorporate questions with various discrimination factors, syllabus coverage, and difficulty variations. In the absence of any commercial application to generate high-quality tests automatically that match the level of the exam being tested for, test generation has primarily remained a manual and tedious process.
Automatically generating a test paper that matches the pattern of the actual real-world exam, its complexity, and other attributes is an NP-hard combinatorics problem. It is essentially a complex discrete optimisation problem wherein we choose test questions, typically less than 100, from the search space of a few hundred questions to satisfy a number of constraints like distributions of difficulty level and time-to-solve at the question level, syllabus coverage at the test level, distribution of important concepts that are likely to be tested in the exam, exploration of concepts not previously tested in the exam, distribution of skills required to solve the questions, previous year exam questions patterns, etc.
Embibe has developed an in-house machine learning-based stack that uses genetic algorithms and simulated annealing with greedy intermediate steps to auto-generate test papers that can closely match actual real-world test papers of the last N years for any given exam. We have also defined a novel way of measuring test paper quality to measure the quality of any auto-generated paper. Details of these algorithms are beyond the scope of this paper.
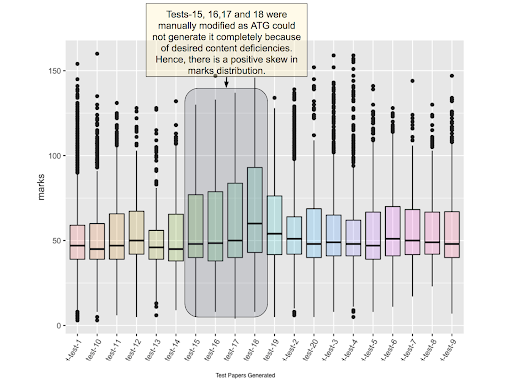
Case Study: Figure 1 shows results from a case study of test papers generated by Embibe’s Automated Test Generation System. We used the system to generate 20 test papers and administered these tests to a random sample of ~8000 students on our platform. Figure 1 shows the distribution of marks obtained by the students as box plots, one box plot for each test paper.
We can observe that the marks distribution is similar across all tests, except for four tests, test-15, test-16, test-17 and test-18, all of which have a positive skew in their marks distribution. This was because in-house faculty manually modified the set of questions in these test papers, which caused a skew in mark distribution over it. These results indicate that Embibe’s Automated Test Generation System can consistently generate identical tests when measured using the metric of averaged student performance.




















