
Embibe helps students improve their learning outcomes, and the main method of finding the content they need is using Embibe’s personalized search engine rather than a menu-driven navigation system. With the advancement in web search, users today expect personalized education through the very first page of search results to contain the exact information they seek.
The amount of content on Embibe is humongous and includes study material, videos, practice questions, tests, articles and news items across exams, subjects, units, chapters, and concepts. Search results are presented in widget sets to expose users to as much actionable content as possible. Each widget represents a collection of results retrieved from search results, grouped together by related actionable links and associated Knowledge Graph nodes for personalized learning in education.
All content on Embibe has different widget types associated with them, and along with cohort-level user characteristics, this expands our search space to a combination of ~120 million documents to be selected from and ranked before being returned to the user. Trend analysis of historical user interaction with search results on Embibe shows that users expect the most relevant information in top widget positions on the first page itself. Hence, the order of result widgets plays an important role in making Search more engaging for our users through a personalized learning model and in improving the quality of our search results.
Learning-to-Rank [1] is a supervised machine learning problem that can be used to construct a ranking model for search results automatically. For each query, all associated documents are collected. The relevance of these documents is usually provided as training data in the form of human assessments or judgments for personalized instruction. This document relevance is then used to train the Learning-to-Rank model to optimise the difference between the ranking results and relevance judgment, averaged over all queries.
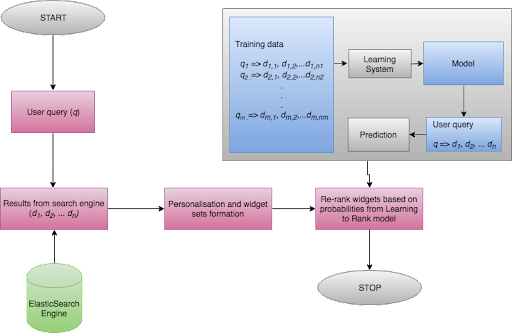
Figure 1: Learning-to-Rank, which we intend to incorporate in semantic search soon, in the context of Embibe’s personalized content discovery engine for customized teaching.
A user makes a query to the personalised content discovery engine on Embibe. The results are retrieved from an Elasticsearch cluster and are passed on to a post-processing layer that constructs widget sets from the results. The user personalization layer uses the Learning-to-Rank model to re-rank the widget sets based on user, query and widget features. The Learning-to-Rank model is a supervised machine learning model that casts the widget ranking problem as that of predicting user clicks on result widgets for a customized education. The model is trained using historical user clicks on widgets against queries made by the user.
Since the results on Embibe are grouped into widgets, which are expanded from first-order results to the query, the ranking function needs to be applied to the widgets. Hence, in our use case, any pre-existing search engine which provides built-in Learning-to-Rank functionality, as in Elasticsearch v6.0 upwards, would not be able to provide the solution. Our personalized search engine that serves content based on user queries ranks first-order results based on user cohort assignments, historical search trends, content consumption patterns, exam-based content importance and past user interaction, among 25 such weighting factors.
While this approach works well based on past user click data on search results, it does not consider query-based user interaction, representing query-document, or, specifically in our use-case, query-widget pairs into high dimensional space and projecting their relevance to user queries. The Learning-to-Rank framework addresses this shortcoming by representing the result set against a query in n-dimensional space and learning the ranking by converting the problem into a machine learning problem such as regression or classification or by optimizing the evaluation metrics.
Usually, Learning-to-Rank algorithms work on query-document pairs or lists for customized teaching. Since each query would produce different sets of widget types and we would also like to personalize the ranking for users, we have considered three categories of features: user, query and widget. We represent our data against each query made by a user using features from the combination of the user profile, query information and the top widgets retrieved from the results.
Features for widgets for personalized learning in education include the type of widget, widget vertical, historical browse popularity, whether query terms matched the widget name, etc. Features for the query include whether specific intent was detected, the query’s length, the query’s term frequency-inverse document frequency features, etc. To account for user personalisation, we also include useful features like user engagement cohort, user performance cohort, the primary goal of the user, etc. Redundant features are eliminated using exploratory data analysis, studying the correlation matrix, mutual information score [2] and dimensionality reduction.
We reduced Learning-to-Rank to a prediction problem wherein we predict user click probability on a particular widget, given the user, query and widget features. Using historical user queries and subsequent click interaction data, we consider widgets at the clicked position and above. This gives us a relatively balanced data set distribution, as historically, users tend to click on higher-up widgets. Using a classification algorithm, we can predict the probability of a click on a widget, and this approach provides a good baseline to start with where the results can be easily interpreted for further iterations. We, therefore, chose logistic regression [3] as our first choice for this approach.
For our experiments, the task was to predict whether a widget at a given position would be clicked or not for some combination of user and query for the personal mode of learning. We started by using only numerical features such as browse popularity, exam weight, query length, etc. and use this as the baseline performance. Adding categorical data, like widget type, user cohort, query goals, and so on, to the enhanced feature set resulted in an improvement of ~6% in accuracy and precision on the click prediction task.
We then added the top 1,500 TF-IDF features extracted from the queries, which improved the model’s accuracy by ~1%, indicating that other text features may need to be extracted from the queries for better performance. The performance of this approach would be used as a baseline for further research iterations on Learning-to-Rank for Embibe’s personalised content discovery engine for customized learning.
References
- Liu T., “Learning to rank for information retrieval.”, Foundations and Trends® in Information Retrieval 3.3 (2009): 225-331.
- Kraskov A., Stögbauer K. and Grassberger P., “Estimating mutual information.”, Physical review E 69.6 (2004): 066138
- Cox D. R., “The regression analysis of binary sequences.”, Journal of the Royal Statistical Society. Series B (Methodological) (1958): 215-242.




















