

Auto Generation Of Tests
One of the major product calls is to surface the search results with the student’s goal, and the exam is given top priority along with the related grades/exams in the relevance and ranking of the results. Students likely want to learn related concepts as well from different grades. This is a handy feature for the aspirants of competitive exams. The Embibe Knowledge graph is leveraged for this purpose.
The other major feature is showing different search facets like all results, videos, books, etc. One of the challenges is merging the results in all sections.
Cross-grade search also helps in surfacing the search result based on the exploring vs. exploit philosophy. On the one hand, where it exploits the student’s current grade information to provide relevant results, it also gives students a choice to explore the related concepts from different grades. This is especially helpful for new students joining Embibe, for whom we have very little information from profile and preference.
Embibe data stored in Content Grail are learning objects with various metadata such as goal, exam, subject, unit, chapter, topic, etc. The indexing of these data points with appropriate schema in elastic search required to surface the results to end-user. Each of the learning objects is a catalog section where a specific product is available and hence is indexed separately.
However, one index must serve data for autocomplete features and have data from multiple learning objects such as books, questions, concepts, etc.
Also, the multiple languages are supported by indexing different language learning objects’ metadata in different indexes with a language identification module at the start of the algorithm pipeline.
The general architecture of search includes following key building blocks in Ingestion side and user query processing side.
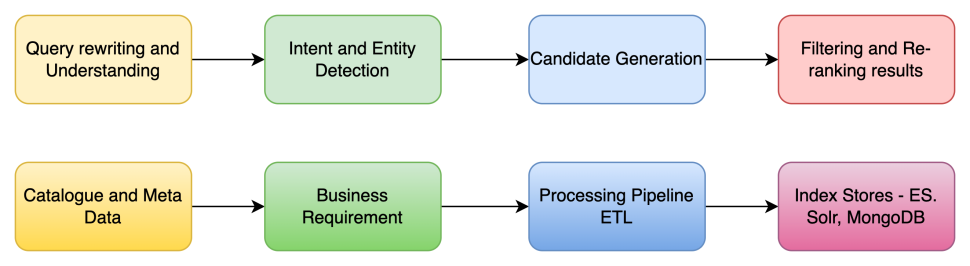
The architecture of this is similar to EMBIBE – The most powerful AI-powered learning platform with additional modules like identifying language, translation and transliteration module, autocomplete API, and ranking module to merge the results of various indexes. The data ingestion pipeline is shown in right side diagram below.
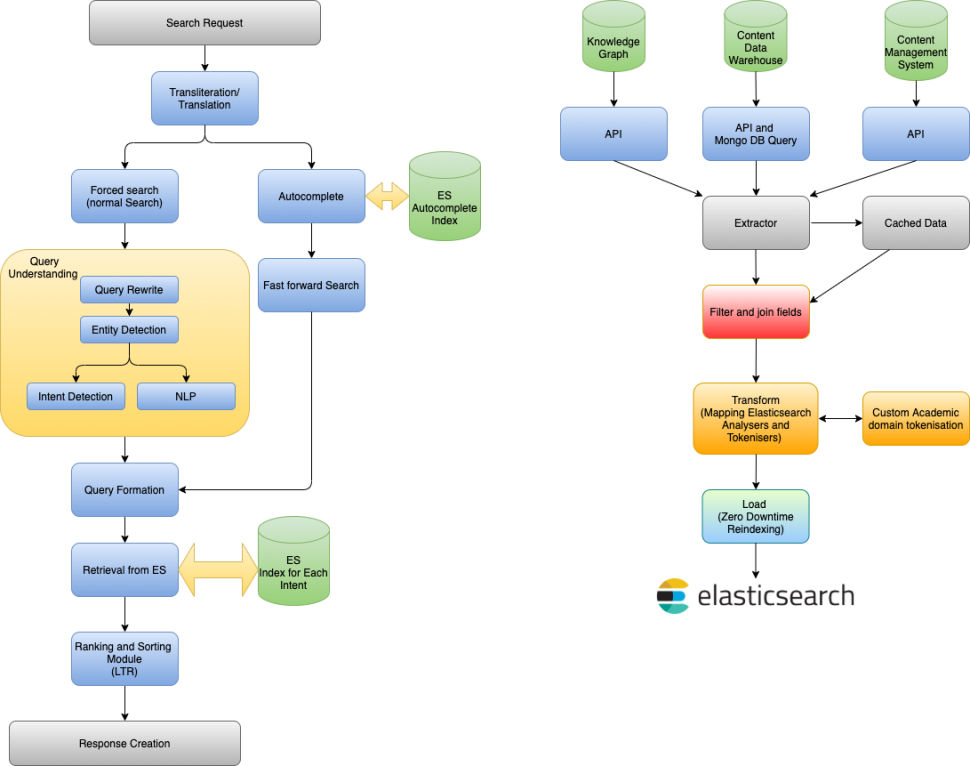
This is one key module to boost the precision and recall of the search. We use Solr based entity tagger to get various type of entities as shown in the diagram. The data source for these are various preprocessing modules working on Embibe’ content data and meta data.

Related entities is used to give user more options to read and explore the Embibe content verse. Knowledge graphs are extensively used to expand the entities. However converting a query into a standard entity is always a challenge and handled by semantically Embedded similar entities.
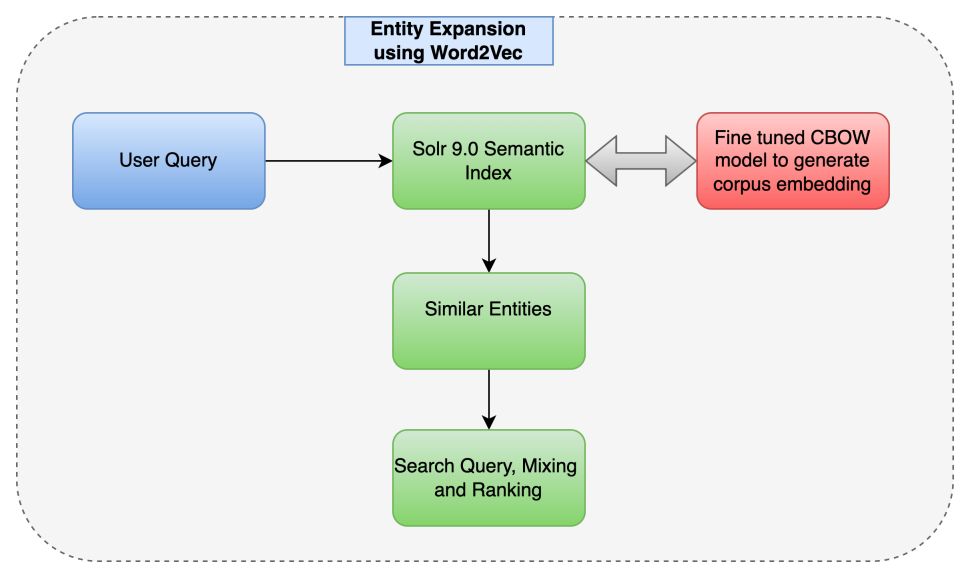
Example of extended entities
| Entity | Related entities |
|---|---|
| Bronchus | [‘Bronchus’, ‘Bronchi’, ‘Primary Bronchi’, ‘Anatomy of Bronchus’, ‘Role of Bronchus in Respiratory System’, ‘Porzo Bronchus in Birds’, ‘Ventro Bronchus in Birds’, ‘Primary Bronchus in Birds’, ‘Ureter’, ‘Ureters’] |
The most challenging part of the Indic language search is mixed language entity detection as any of following 4 cases can occur,
| Script/ Language | En | Indic |
|---|---|---|
| En | Speed of Light | Prakash ki Gati/ speed |
| Indic | प्रकाश की स्पीड/लाइट की स्पीड | प्रकाश की चाल/ गति/ वेग |
To handle these case, special translation and transliteration tags are created in Solr which produce perfect translation/ transliteration to understand the text




















