Auto Generation Of Tests
Doubt Resolution Product, as the name suggests, is the platform that aims to help solve the doubts of a user. While this help can be offered by the Subject Matter Experts, the volume and the breadth of doubts coming in parallel can make it very hard for these experts to get back to every doubt manually. This can in turn introduce longer wait time and add to a bad user experience.
We hence introduce the Machine Learning algorithms to assist and filter the number of questions that the human experts have to answer.
The 2 main challenges while solving this are capturing context from the user’s doubt and identifying contextually similar questions from the huge pool of questions.
Most doubt-resolution products utilize existing corpora of content to provide similar questions or build a system capable of answering questions based on the available context around the question.
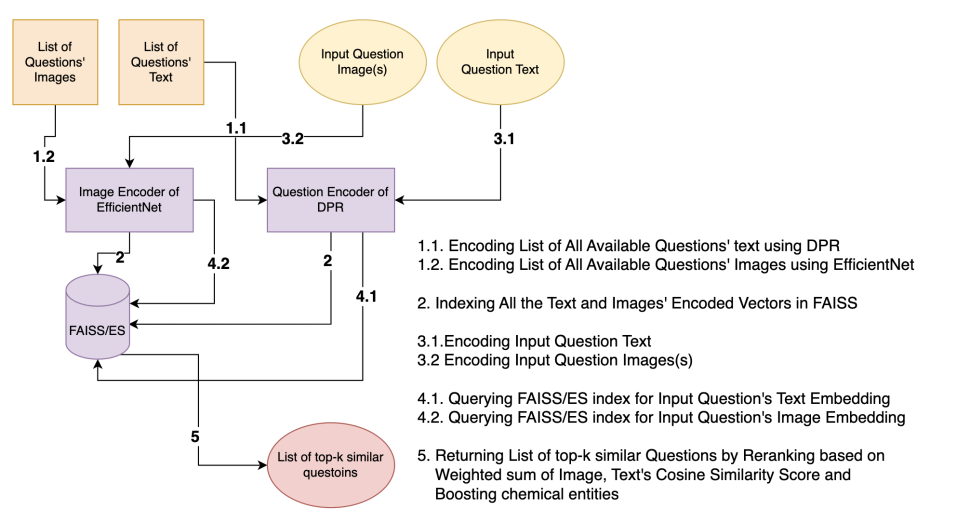
We at Embibe have millions of questions in our question bank. We use state-of-the-art models finetuned on our academic corpora to get the contextual information from the question text and diagrams or figures present in the question. We encode this information into high dimensional vector space and retrieve the answer with step by step solution if it is present in our question bank; else, we display contextually similar questions with a step-by-step solution on which the user can practice.
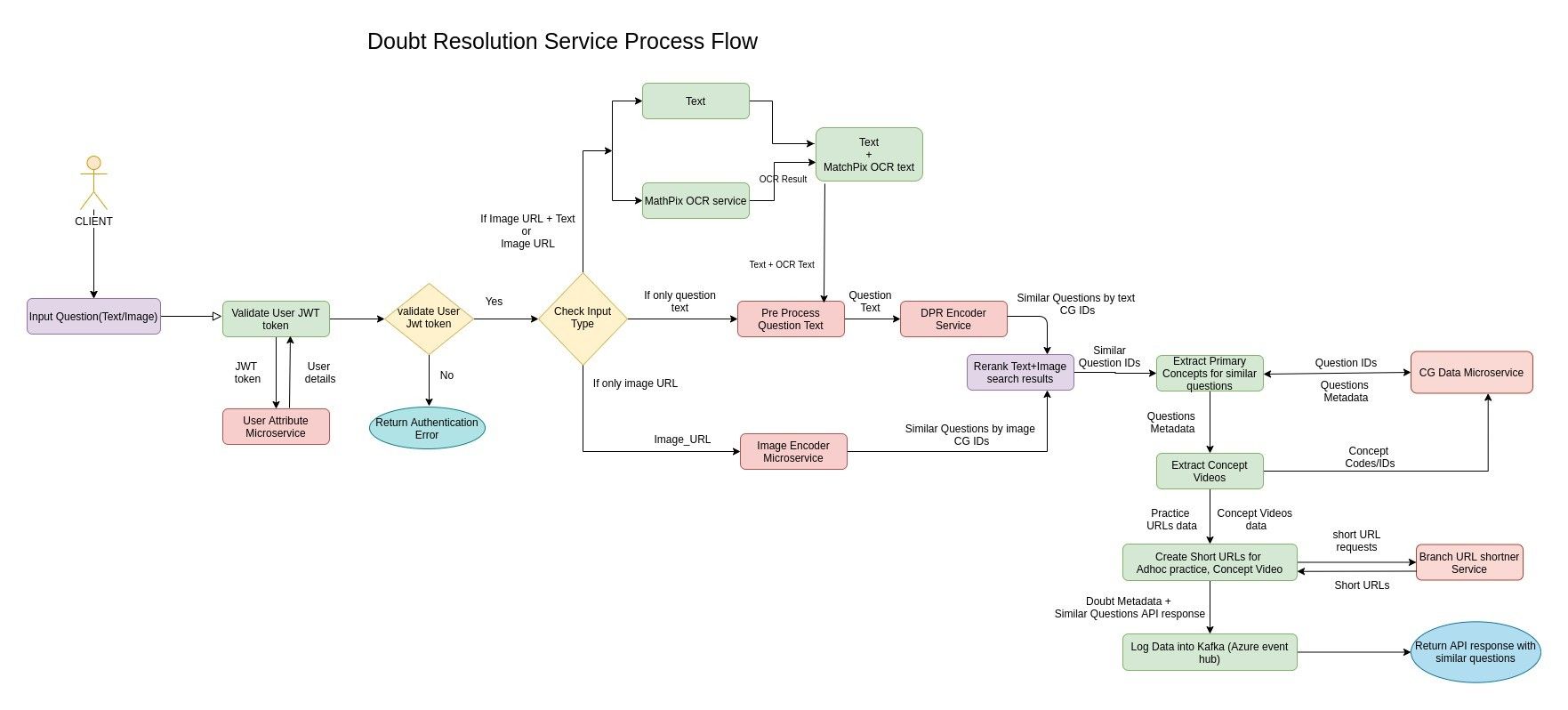

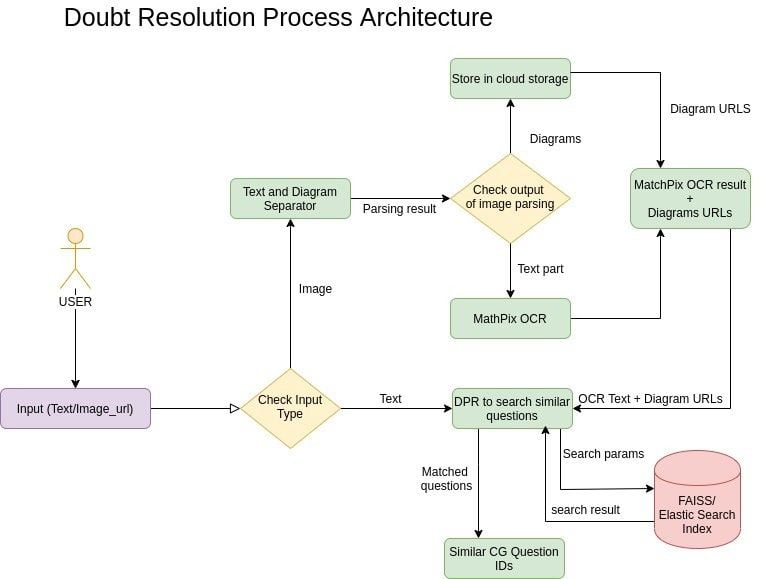
This pipeline mainly contains three sequential stages, if the input is in the image form:
In the case of text input, stage-3 can directly be executed.
To be able to help solve the doubt at hand, it is important for us to capture all the details provided around the question, by the user. Nearly 10% of the time, this is in the form of figures, diagrams, graphs, chemical equations, etc. It was also observed that the performance of the OCR layer at Stage-2, is affected by the presence of a figure in the input image. We hence introduce a diagram detection layer to ensure both, that the diagrams also play an important role when searching for similar questions, and that the presence of a diagram in the input image does not affect the OCR performance.
This layer inputs the image with only text and no diagrams, to extract the text content and further fetch similar questions based on the same. It is known that, in order to pass a text-heavy image through OCR, it needs to have high resolution, while many of the academic doubt images(~42% of the user images) that’re uploaded on the platform might not only have low resolution but might also introduce shadow, rotation, unintended text, etc. Preprocessing steps like skew correction, removing shadow, enhancing resolution, and detecting blur, hence would add to ensuring a good OCR performance.
Dense Passage Retrieval (DPR) is a set of tools and models for state-of-the-art open-domain Q&A research. Open-domain question answering relies on efficient passage retrieval to select candidate contexts, where traditional sparse vector space models, such as TF-IDF or BM25, are the de facto method. In DPR, retrieval can be practically implemented using dense representations alone, where embeddings are learned from a small number of questions and passages by a simple dual-encoder framework. When evaluated on a wide range of open-domain QA datasets, DPR outperforms a strong Lucene-BM25 system largely by 9%-19% absolute in terms of top-20 passage retrieval accuracy and helps our end-to-end QA system establish new state-of-the-art on multiple open-domain QA benchmarks.
We leverage the pre-trained DPR model and finetune it on our academic corpora consisting of Question Texts, Answers, and their detailed Explanations to make DPR domain-specific. Then we use the Question Encoder part of the DPR to encode the Questions to retrieve contextually similar questions.