

Saas દ્વારા AI અનલોક કરવું

એજ્યુકેશન ટેક્નોલોજીના ક્ષેત્રમાં, તમામ યુઝર માટે કોન્ટેન્ટને સુલભ અને સર્ચ યોગ્ય બનાવવાનું એક મહત્વપૂર્ણ કાર્ય છે. તે કરવા માટે, કંપનીઓ પ્રોડક્ટના એકંદર યુઝર અનુભવ સાથે સંરેખિત હોય તેવા સંબંધિત ટેગ સાથે કોન્ટેન્ટને ટેગ કરવા માટે માનવ ટીકાકારો અથવા વિષયના નિષ્ણાંતોને નિયુક્ત કરે છે.
Embibe ના નોલેજ ગ્રાફમાં 74,000+ નોડ્સ છે, જેમાં દરેક નોલેજના એક અલગ એકમનું પ્રતિનિધિત્વ કરે છે. વધુમાં, ત્યાં 1,89,380 ઇન્ટરકનેક્શન અને 2,15,062 કમ્પિટેન્સી છે. સેંકડો અભ્યાસક્રમમાં હજારો પરીક્ષાઓમાં કોન્ટેન્ટને વિસ્તારિત કરવામાં આવ્યો હોવાથી, ટેગિંગની પ્રક્રિયા વધુ ખર્ચાળ અને સમય માંગી લે તેવી બની જાય છે. વધુમાં, ત્યાં હંમેશા માનવીય પૂર્વગ્રહ હોય છે જે ડેટાસેટમાં મેન્યુઅલ ટેગિંગ થાય ત્યારે થાય છે જે ડેટાસેટના વિવિધ સબસેટ પર કામ કરતા બહુવિધ માનવ ટીકાકારો હોવાને કારણે થાય છે.
મેટાટેગ રેન્કર મેન્યુઅલ પ્રક્રિયાને લૂપ અર્ધ-સ્વચાલિત ટેગિંગ પ્રક્રિયામાં માનવ સાથે બદલીને માનવ ટેગિંગ સાથે સંકળાયેલ સમસ્યાઓને દૂર કરવાનો છે. મેટાટેગ રેન્કર એ વિષયના નિષ્ણાંતો માટે બનાવવામાં આવેલ એક સાધન છે, જે તેમને Embibe પ્લેટફોર્મ દ્વારા સમર્થિત તમામ લક્ષ્યો માટે વિષય, એકમ, પ્રકરણ, વિષય અને કોઈપણ આપેલ પ્રશ્નોના કોન્સેપ્ટને ટેગ કરવા માટે સૂચનો પ્રદાન કરે છે. વધુમાં, તે મુશ્કેલી સ્તર, આદર્શ સમય અને પ્રશ્નના બ્લુમ સ્તર માટે સૂચનો પણ પ્રદાન કરે છે.
ચાલો બે ઉદાહરણો સાથે તે કેવી રીતે કાર્ય કરે છે તે સમજીએ.
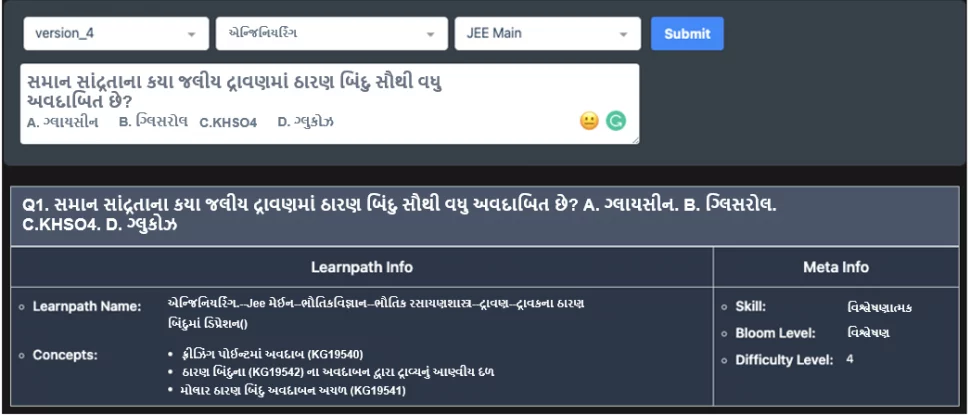
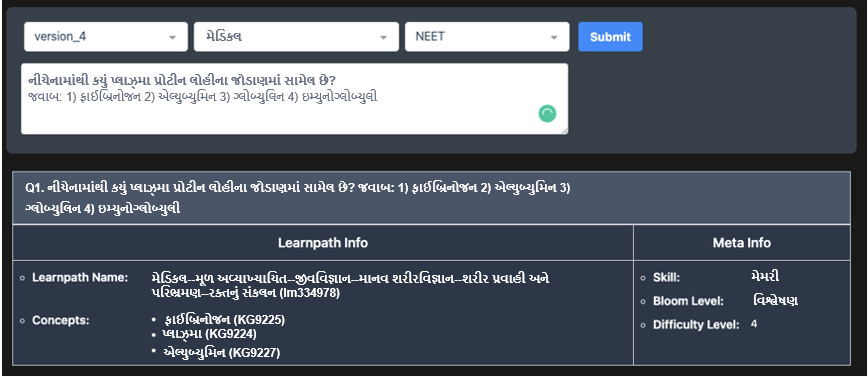
મેટાટેગ રેન્કર એક્સ્ટ્રીમ મલ્ટીક્લાસ ક્લાસિફિકેશન પ્રોબ્લેમ (XMC)[1][2] પર આધારિત છે. Embibe માટે, આપેલ કોઈપણ પ્રશ્ન માટે 74,000+ શ્રેણી અથવા કોન્સેપ્ટ છે. શ્રેણી પરસ્પર વિશિષ્ટ નથી એટલે કે, કોન્સેપ્ટ અર્થપૂર્ણ રીતે પ્રકૃતિમાં ઓવરલેપ થતી હોય છે. XMC માટેનો બીજો પડકાર ડેટાસેટનું વિતરણ છે. તમામ શ્રેણી અથવા કોન્સેપ્ટમાં પર્યાપ્ત સંખ્યામાં ડેટાપોઈન્ટ હોતા નથી એટલે કે, કેટલીક શ્રેણીમાં ઘણા બધા ડેટા પોઈન્ટ હોય છે જ્યારે અન્યમાં બહુ ઓછા હોય છે જે મોડલ અનુમાન દ્વારા અવગણવામાં આવતા થોડા ડેટા પોઈન્ટ સાથેની શ્રેણી તરફ દોરી જાય છે. મેટાટેગ રેન્કર પ્રાકૃતિક ભાષાની સમજ માટે અદ્યતન ડીપ લર્નિંગ તકનીકોનો લાભ લે છે. તે જ્ઞાનતંતુના મોડલને તાલીમ આપવામાં નોલેજ ગ્રાફનો પણ ઉપયોગ કરે છે [3]. મોડલ દ્વારા સમજાવી શકાય તેવી અને અર્થઘટન કરી શકાય તેવા અનુમાન પ્રોડક્શન સેટિંગમાં આ ક્ષમતાને જમાવવામાં વિશ્વાસપાત્ર શિક્ષણવિદોને મદદ કરે છે [4][5]. આવા સમૃદ્ધ કોન્ટેન્ટ ઓટો ટેસ્ટ જનરેશન [5][7] અને લર્નિંગ આઉટકમ [6] પહોંચાડવાની ક્ષમતાને સશક્ત બનાવે છે.
મેટા ટેગ જનરેટરે બુક, પ્રશ્નો અને લર્નિંગ વિડિયો માટે AI સાથે મેન્યુઅલ ટેગ જનરેશન પ્રક્રિયાના હજારો કલાકો બચાવ્યા. આનાથી વિવિધ ધોરણ અને વિષયો માટે વિષયની નિપુણતાની આવશ્યકતા પણ ઘટી ગઈ. Embibe વિડિયો અને 3D એસેટ ક્રિએશન માટે સ્પીચ મેટાટેગ પણ વિકસાવી રહી છે.
સંદર્ભ:
[1] ચાંગ, વેઈ-ચેંગ, હસિઆંગ-ફૂ યુ, કાઈ ઝોંગ, યિમિંગ યાંગ અને ઈન્દ્રજીત એસ. ધિલ્લો. “આત્યંતિક મલ્ટી-લેબલ ટેક્સ્ટ વર્ગીકરણ માટે પ્રીટ્રેઇન્ડ ટ્રાન્સફોર્મર્સ ટેમિંગ.” નોલેજ ડિસ્કવરી એન્ડ ડેટા માઇનિંગ પર 26મી ACM SIGKDD ઇન્ટરનેશનલ કોન્ફરન્સની કાર્યવાહીમાં, પૃષ્ઠ 3163-3171. 2020.
[2] દહિયા, કુણાલ, દીપક સૈની, અંશુલ મિત્તલ, અંકુશ શો, કુશલ દવે, અક્ષય સોની, હિમાંશુ જૈન, સુમીત અગ્રવાલ, અને માણિક વર્મા. “DeepXML: ડીપ એક્સ્ટ્રીમ મલ્ટી-લેબલ લર્નિંગ ફ્રેમવર્ક ટૂંકા લખાણ દસ્તાવેજો પર લાગુ થાય છે.” વેબ સર્ચ અને ડેટા માઇનિંગ પર 14મી ACM ઇન્ટરનેશનલ કોન્ફરન્સની કાર્યવાહીમાં, પૃષ્ઠ 31-39. 2021.[arXiv]
[3] ફાલદુ, કેયુર, અમિત શેઠ, પ્રશાંત કિકાણી અને હેમાંગ અકબરી. “KI-BERT: વધુ સારી ભાષા અને ડોમેન સમજણ માટે નોલેજ સંદર્ભનો સમાવેશ.” arXiv preprint arXiv:2104.08145 (2021).
[4] ગૌર, માનસ, કેયુર ફાલદુ અને અમિત શેઠ. “બ્લેક-બોક્સના અર્થશાસ્ત્ર: શું નોલેજ ગ્રાફ ડીપ લર્નિંગ સિસ્ટમને વધુ અર્થઘટન અને સમજાવી શકાય તેવું બનાવવામાં મદદ કરી શકે છે?.” IEEE ઇન્ટરનેટ કમ્પ્યુટિંગ 25, નં. 1 (2021): 51-59.
[5] ધવલ, સોમા, ચિરાગ ભાટિયા, જોય બોઝ, કેયુર ફાલદુ અને અદિતિ અવસ્થી. “ડાયગ્નોસ્ટિક એસેસમેન્ટ અને તેમની ગુણવત્તા મૂલ્યાંકનનું સ્વતઃ નિર્માણ. “ઇન્ટરનેશનલ એજ્યુકેશનલ ડેટા માઇનિંગ સોસાયટી (2020).
[6] ફાલદુ, કેયુર, અદિતિ અવસ્થી અને અચિંત થોમસ. “સ્કોરના સુધારણા અને તેના ભાગો માટે અનુકૂલનશીલ લર્નિંગ મશીન.” યુ.એસ. પેટન્ટ 10,854,099, 1 ડિસેમ્બર, 2020 ના રોજ જારી.
[7] દેસાઈ, નિશિત, કેયુર ફાલદુ, અચિંત થોમસ અને અદિતિ અવસ્થી. “એસેસમેન્ટ પેપર બનાવવા અને તેની ગુણવત્તા માપવા માટેની સિસ્ટમ અને પદ્ધતિ.” યુ.એસ. પેટન્ટ એપ્લિકેશન 16/684,434, ઑક્ટોબર 1, 2020 ના રોજ ફાઇલ કરવામાં આવી.
← AI હોમ પર પાછા જાઓ


















