

Saas દ્વારા AI અનલોક કરવું

પ્રેરણા
સમગ્ર દેશમાં લાખો વિદ્યાર્થીઓ વધુ શીખવા, સખત પ્રેક્ટિસ કરવા અને લર્નિંગ આઉટકમ મેળવવા માટે પોતાની જાતને ચકાસવા માટે નિયમિતપણે Embibe નો ઉપયોગ કરે છે. આ સમગ્ર સફર દરમિયાન, તે પ્રશ્નો અથવા શંકાઓના સમૂહ પર ઠોકર ખાશે તેવી અપેક્ષા છે. તેથી વિદ્યાર્થીઓ પ્રશ્ન પ્રત્યે હંમેશા પ્રોત્સાહિત રહે તે સુનિશ્ચિત કરવા માટે અમારી પાસે શંકા નિવારણ પ્રોડક્ટ છે.
નામ સૂચવે છે તેમ, આ એક પ્લેટફોર્મ છે જેનો હેતુ વિદ્યાર્થીઓની શંકાઓને ઉકેલવામાં મદદ કરવાનો છે. જ્યારે આ મદદ વિષયના નિષ્ણાંતો દ્વારા ઓફર કરી શકાય છે, ત્યારે વાસ્તવિક સમયમાં એકસાથે આવતી શંકાઓનું પ્રમાણ અને પહોળાઈ આ નિષ્ણાંતો માટે દરેક શંકાને જાતે જ ઉકેલવામાં ખૂબ જ મુશ્કેલ બનાવી શકે છે. આના બદલામાં, લાંબા સમય સુધી રાહ જોવાનો સમય અને ઉપ-શ્રેષ્ઠ યુઝર અનુભવ રજૂ કરી શકે છે.
તકનો ઉપયોગ કરવો
મોટાભાગના શૈક્ષણિક કોન્ટેન્ટમાં છબીઓ, સમીકરણો અને સંજ્ઞામાં છુપાયેલી માહિતીનો સમાવેશ થાય છે. છબીઓ અને ગ્રંથોમાંથી અર્થપૂર્ણ માહિતી કાઢવી એ હજી પણ એક ડોમેન-આશ્રિત અને મુશ્કેલ કાર્ય છે જેમાં મોટા ડેટાસેટ, કાર્યક્ષેત્ર સ્પેસિફિક જ્ઞાન અને પ્રાકૃતિક ભાષા અને દ્રષ્ટિ માટે અદ્યતન ગહન શિક્ષણ અભિગમોની જરૂર છે.
મોટાભાગના શંકા-નિવારણ પ્રોડક્ટનો સમાન પ્રશ્નો પુરા પાડવા અથવા પ્રશ્નની આસપાસના ઉપલબ્ધ સંદર્ભના આધારે પ્રશ્નોના જવાબ આપવા સક્ષમ સિસ્ટમ બનાવવા માટે કોન્ટેન્ટના હાલના નિયમનો ઉપયોગ કરે છે. Embibe પર, અમારી પ્રશ્ન બેંકમાં લાખો પ્રશ્નો છે. અમે અમારા શૈક્ષણિક લખાણમાં અદ્યતન મોડલનો ઉપયોગ કરીએ છીએ જે પ્રશ્નમાં હાજર ડાયાગ્રામ અથવા આકૃતિઓમાંથી પ્રશ્નના ટેક્સ્ટમાંથી સંદર્ભિત માહિતી મેળવે છે.
શંકા નિવારણ પ્રોડક્ટ સાથે, 93% પ્રશ્નોના કોઈપણ માનવ ઈન્ટરવેશનની જરૂર વગર આપમેળે જવાબ આપી શકાય છે.
શંકા ઉકેલ સિસ્ટમની રચના
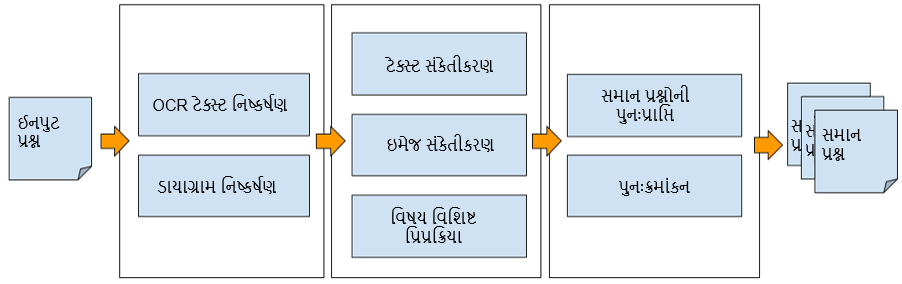
ડાયાગ્રામ નિષ્કર્ષણ:

હાથમાં રહેલી શંકાને ઉકેલવામાં મદદ કરવા માટે, અમારા માટે પ્રશ્નની આસપાસ પૂરી પાડવામાં આવેલ તમામ વિગતોને ધ્યાનમાં લેવી મહત્વપૂર્ણ છે. આથી, અમે એક ડાયાગ્રામ નિષ્કર્ષણ સ્તર રજૂ કરીએ છીએ તેની ખાતરી કરવા માટે કે નિષ્કર્ષિત ડાયાગ્રામને સિમેન્ટીક સમાનતાની ગણતરીમાં પણ ધ્યાનમાં લેવામાં આવે છે. OCR મોડ્યુલના ઇનપુટમાં ડાયાગ્રામની હાજરી તેને મૂંઝવણમાં મૂકી શકે છે, તેથી અમે ડાયાગ્રામ બાઉન્ડિંગ બોક્સને દૂર કરવા માટે ઇમેજ પર પ્રક્રિયા કરીએ છીએ, જે તેને OCR પ્રોસેસિંગ માટે સરળ બનાવે છે. શૈક્ષણિક-ડોમેન માટે અમારું મૂળ રીતે બનાવેલ આકૃતિ નિષ્કર્ષણ મોડેલ સમાન સચોટતા હાંસલ કરીને વિલંબમાં YOLOv5 જેવા જટિલ મોડલને નોંધપાત્ર રીતે આગળ કરે છે.
ઓપ્ટિકલ કેરેક્ટર રેકગ્નિશન (OCR):

અમે ઇમેજમાં હાજર આકૃતિઓ એક્સ્ટ્રેક્ટ કર્યા પછી, અમે પછીના તબક્કે ઉપયોગમાં લેવા માટે ઇમેજની અંદર હાજર ટેક્સ્ટને કાઢવા અને પાર્સ કરવા માટે OCR લેયરનો ઉપયોગ કરીએ છીએ. OCR પરફોર્મન્સને બહેતર બનાવવા માટે ત્રાંસી સુધારણા, આભાસને દૂર કરવા, રિઝોલ્યુશન વધારવા અને અસ્પષ્ટતા શોધવા જેવા પ્રી-પ્રોસેસિંગ પગલાંઓ કરવામાં આવે છે.
ઈમેજ એન્કોડિંગ:
અમે સ્ટેટ ઓફ ધ આર્ટ કોમ્પ્યુટર વિઝન મોડલ જેમ કે ResNet, અને EfficientNet નો ઉપયોગ કરીએ છીએ આંકડાઓને ગાઢ વેક્ટરમાં એન્કોડ કરવા માટે કે જે ઇમેજમાં હાજર સિમેન્ટીક માહિતીને કેપ્ચર કરે છે જેથી સિમેન્ટીકલી સમાન ઇમેજ કેટલીક અલગ અલગ ઇમેજ કરતાં એકબીજાની નજીક હશે.
અમે અમારા શૈક્ષણિક કોર્પોરા પર મોડેલને તાલીમ આપીને ટ્રિપલેસ લોસ અને પરસ્પર માહિતી મહત્તમીકરણ જેવી તકનીકોનો લાભ લઈને ગાઢ વેક્ટર પ્રતિનિધિત્વ શીખીએ છીએ, જેમાં પ્રશ્ન ટેક્સ્ટ, જવાબો અને તેમના વિગતવાર ખુલાસાનો સમાવેશ થાય છે. અમે BERT, અને T5 જેવા પ્રી-તાલીમબંધ ભાષા મોડલનો લાભ લઈએ છીએ. પછી અમે આ એન્કોડર મોડલનો ઉપયોગ OCR એક્સટ્રેક્ટ કરેલા ટેક્સ્ટને ડેન્સ વેક્ટરમાં રૂપાંતરિત કરવા માટે કરીએ છીએ, જેનો ઉપયોગ સિમેન્ટીકલી સમાન પ્રશ્નોને પુનઃપ્રાપ્ત કરવા માટે થાય છે.
સમાન પ્રશ્નો પુનઃપ્રાપ્ત કરવા:
અમે અમારી પ્રશ્ન બેંકમાં હાજર તમામ પ્રશ્નો સાથે એન્કોડ કરેલ ઈમેજ અને ટેક્સ્ટની તુલના કરીએ છીએ અને ટોપ-કે સમાન પ્રશ્નો પુનઃપ્રાપ્ત કરીએ છીએ. જો પ્રશ્નમાં ઈમેજના મહત્વના આધારે ટેક્સ્ટ અને ઈમેજ બંને હાજર હોય તો અમે ભારિત સમાનતા મેળવવા માટેની તકનીકોનો પણ ઉપયોગ કરીએ છીએ. લાખો રેકોર્ડ્સ પર ડેન્સ વેક્ટરની કોસાઇન સમાનતા કરવી ખર્ચાળ છે. આથી, અમે અમારી સિસ્ટમને ઓછી-લેટેન્ટ અને કાર્યક્ષમ બનાવવા માટે શાર્ડિંગ, બકેટિંગ અને ક્લસ્ટરિંગ અભિગમોનો ઉપયોગ કરીએ છીએ.
વિષય વિશિષ્ટ પોસ્ટ પ્રોસેસિંગ:
અમે વિષય વિશિષ્ટ પોસ્ટ પ્રોસેસિંગ તકનીકોનો ઉપયોગ કરીએ છીએ, જેમ કે રાસાયણિક સમીકરણો, ટેક્સ્ટમાં હાજર ગણિતના પદનું સંચાલન કરવું. લખાણમાં હાજર રાસાયણિક સમીકરણો અને રાસાયણિક એન્ટિટી સિમેન્ટીકલી સમાન પ્રશ્નોને પુનઃપ્રાપ્ત કરવા માટે મહત્વપૂર્ણ ભૂમિકા ભજવે છે.
સંદર્ભ:
[1] રાફેલ, કોલિન, નોઆમ શાઝીર, એડમ રોબર્ટ્સ, કેથરીન લી, શરણ નારંગ, માઈકલ માટેના, યાન્કી ઝોઉ, વેઈ લી અને પીટર જે. લિયુ. “એક યુનિફાઇડ ટેક્સ્ટ-ટુ-ટેક્સ્ટ ટ્રાન્સફોર્મર સાથે ટ્રાન્સફર લર્નિંગની મર્યાદાઓનું અન્વેષણ કરવું.” arXiv પ્રીપ્રિન્ટ arXiv:1910.10683 (2019).
[2] ડેવલિન, જેકબ, મિંગ-વેઇ ચાંગ, કેન્ટન લી અને ક્રિસ્ટીના ટૌટાનોવા. “બર્ટ: ભાષાની સમજણ માટે ડીપ દ્વિપક્ષીય ટ્રાન્સફોર્મર્સની પૂર્વ-તાલીમ.” arXiv પ્રીપ્રિન્ટ arXiv:1810.04805 (2018).
[3] ટેન, મિંગક્સિંગ અને ક્વોક લે. “એફિશિયન્ટનેટ: કન્વોલ્યુશનલ ન્યુરલ નેટવર્ક માટે મોડલ સ્કેલિંગ પર પુનર્વિચાર કરવો.” મશીન લર્નિંગ પર ઇન્ટરનેશનલ કોન્ફરન્સમાં, પૃષ્ઠ 6105-6114. PMLR, 20
[4] ફાલદુ, કેયુર, અમિત શેઠ, પ્રશાંત કિકાણી અને હેમાંગ અકબરી. “KI-BERT: વધુ સારી ભાષા અને ડોમેન સમજણ માટે જ્ઞાન સંદર્ભનો સમાવેશ.” arXiv પ્રીપ્રિન્ટ arXiv:2104.08145 (2021).
[5] ગૌર, માનસ, કેયુર ફાલદુ અને અમિત શેઠ. “બ્લેક-બોક્સના અર્થશાસ્ત્ર: શું જ્ઞાન ગ્રાફ ડીપ લર્નિંગ સિસ્ટમ્સને વધુ અર્થઘટન અને સમજાવી શકાય તેવું બનાવવામાં મદદ કરી શકે છે?.” IEEE ઇન્ટરનેટ કમ્પ્યુટિંગ 25, નં. 1 (2021): 51-59.
[6] ગૌર, માનસ, અંકિત દેસાઈ, કેયુર ફાલદુ અને અમિત શેઠ. “નોલેજ ગ્રાફ્સનો ઉપયોગ કરીને સમજાવી શકાય તેવું AI.” ACM CoDS-COMAD કોન્ફરન્સમાં. 2020.
[7] શેઠ, અમિત, માનસ ગૌર, કૌશિક રોય અને કેયુર ફાલદુ. “સમજવાપાત્ર AI માટે જ્ઞાન-સઘન ભાષા સમજણ.” IEEE ઇન્ટરનેટ કમ્પ્યુટિંગ 25, નં. 5 (2021): 19-24.
[8] “#RAISE2020 – Embibe – વ્યક્તિગત શિક્ષણ માટે AI-સંચાલિત શિક્ષણ પરિણામોનું પ્લેટફોર્મ”, MyGov India, ઓક્ટોબર 2020, https://www.youtube.com/watch?v=kuwFtHgN3qU
[9] ફાલદુ, કેયુર, અદિતિ અવસ્થી અને અચિંત થોમસ. “સ્કોરના સુધારણા અને તેના ભાગો માટે અનુકૂલનશીલ શિક્ષણ મશીન.” યુ.એસ. પેટન્ટ 10,854,099, 1 ડિસેમ્બર, 2020 ના રોજ જારી.
← AI હોમ પર પાછા જાઓ


















