
ನವೀನ ಶಕ್ತಿಯಾಗಿ ದತ್ತಾಂಶ
Embibe ದತ್ತಾಂಶದ ಮೇಲೆ ತುಂಬಾ ಅಭಿಮಾನವನ್ನು ಬೆಳೆಸಿಕೊಂಡಿದ್ದು, ಅದರ ಪರಿಕರಣೆ, ಮಾಪನ, ಸಂಗ್ರಹಣ, ಉತ್ಖನನ ಮತ್ತು ದಾಖಲು ಮಾಡುತ್ತದೆ. Embibe ಗೆ ತನ್ನದೇ ಆದ ಸ್ವಂತ ದತ್ತಾಂಶವಿದೆ. ನಮ್ಮ IP ಅದನ್ನು ಅವಲಂಬಿಸಿದೆ. Embibeನಲ್ಲಿ ನಮ್ಮ ಬಳಕೆದಾರರು ನಮ್ಮ ಉತ್ಪನ್ನಗಳೊಂದಿಗೆ ಹೇಗೆ ಸಂವಹನ ನಡೆಸುತ್ತಾರೆ ಎಂಬುದನ್ನು ಅಳೆಯಲು, ಸಾಕಷ್ಟು ಸಲಕರಣೆ ಇರುವವರೆಗೂ ದತ್ತಾಂಶವನ್ನು ಬಿಡುಗಡೆ ಮಾಡಲು ವಿಳಂಬಿಸುತ್ತೇವೆ. ಅದೂ ಅಲ್ಲದೇ ನಿಖರ ಫಲಿತಾಂಶಕ್ಕೆ ಯಾವ ಅಂಶ ಕಾರಣ ಎಂಬುದನ್ನು ನಿರ್ದೇಶಿಸಲಾಗುವುದು. ನಮ್ಮ ಈ ದತ್ತಾಂಶದ ಮೇಲಿನ ಗೀಳು ಪ್ರವೃತ್ತಿಯಿಂದ ವಿದ್ಯಾರ್ಥಿಗಳು ಹೇಗೆ ವ್ಯಾಸಂಗ ಮಾಡುತ್ತಾರೆ ಮತ್ತು ಅವರು ಗುರಿ ಹೇಗೆ ಸಾಧಿಸುತ್ತಾರೆ ಎಂಬುದನ್ನು ತಿಳಿಯಲು ಅನೇಕ ರೀತಿಯಲ್ಲಿ ಒಳನೋಟ ಹರಿಸುವಂತೆ ಮಾಡಿ ಬಹಿರಂಗಪಡಿಸಲು ಕಾರಣವಾಯಿತು. ಉದಾಹರಣೆಗೆ, ವಿದ್ಯಾರ್ಥಿ ಗಳಿಸುವ ಸಾಮರ್ಥ್ಯವು ಎರಡು ಅಂಶಗಳ ಸಂಯೋಜನೆಯಾಗಿದೆ. ಅವರ ಕಲಿಕೆಯ ಸಾಮರ್ಥ್ಯ ಅಂದಾಜು ಒಟ್ಟಾರೆ ಸಾಮರ್ಥ್ಯದ ~61% ರಷ್ಟು ಭಾಗವಾದರೆ, ಉಳಿದ ~39%. ರಷ್ಟು ಅವರ ನಡವಳಿಕೆಯ ಗುಣಲಕ್ಷಣಗಳು ಸೇರಿವೆ. ದತ್ತಾಂಶ-ಆಧಾರಿತವು ಅಲಗಿನಷ್ಟೇ ತೀಕ್ಷ್ಣವಾದ ಗಮನವು ವೈಯಕ್ತೀಕರಿಸಿದ ಶಿಕ್ಷಣದ ಉತ್ಪನ್ನಗಳನ್ನು ನಿರ್ಮಿಸಲು Embibe ಅನ್ನು ಸಾಧ್ಯವಾಗಿಸಿದೆ. ಅದೇ ರೀತಿ ವಿದ್ಯಾರ್ಥಿಗಳಿಗೆ ಕಲಿಕೆಯ ಉತ್ತಮ ಫಲಿತಾಂಶಕ್ಕೆ ಬಹಳಷ್ಟು ಸುಧಾರಣೆಯನ್ನು ಹೊರತಂದಿದೆ.
ಪ್ರಾಥಮಿಕ ದತ್ತಾಂಶ ಸಂಗ್ರಹ
ದತ್ತಾಂಶ ಎಂಬುದು ಪರಿಕರ. ಇದನ್ನು ವಿವಿಧ ಹಂತದಲ್ಲಿ ಸಂಗ್ರಹಿಸಲಾಗುತ್ತದೆ ಮತ್ತು Embibe ನ ಎಲ್ಲಾ ಪ್ಲಾಟ್ಫಾರ್ಮ್ನಲ್ಲಿ ಲಭ್ಯವಿದೆ. ಕೇವಲ ದತ್ತಾಂಶವನ್ನು ಮಾತ್ರ ಸೆರೆಹಿಡಿಯುವ ಉದ್ದೇಶವಲ್ಲ. ಎಷ್ಟು ಸಾಧ್ಯವೋ ಅಷ್ಟು ಸರಿಯಾದ ದತ್ತಾಂಶವನ್ನು, ಸರಿಯಾದ ಸಮಯದಲ್ಲಿ, ಸಮರ್ಪಕ ಸನ್ನಿವೇಶದಲ್ಲಿ ಸಮರ್ಪಕ ಮಟ್ಟದ ತುಣುಕುಗಳನ್ನು ಸೆರೆಹಿಡಿಯುವುದು ಉದ್ದೇಶ. Embibe ನಲ್ಲಿ ದತ್ತಾಂಶ ಸಂಗ್ರಹವು ವಿವರವಾಗಿ ಈ ಕೆಳಗಿನ ವರ್ಗಗಳಲ್ಲಿ ಬರುತ್ತದೆ:
- ಗರಿಷ್ಟ ಮಟ್ಟದ ಘಟನೆ ವಿಧಗಳ ಸಲಕರಣೆಗಳು:
- ಬಳಕೆದಾರರ-ಸಂವಹನ ಸ್ಪಷ್ಟ ಘಟನೆಗಳು – ಕ್ಲಿಕ್ಗಳು, ಟ್ಯಾಪ್ಗಳು, ಹೋವರ್ಗಳು, ಸ್ಕ್ರಾಲ್ಗಳು, ಪಠ್ಯ-ಪರಿಷ್ಕರಣೆಗಳು
- ಬಳಕೆದಾರರ-ಸಂವಹನ ಸೂಚಿತ ಘಟನೆಗಳು – ಕರ್ಸರ್ ಸ್ಥಾನ, ಟ್ಯಾಪ್ ಒತ್ತಡ, ಸಾಧನದ ದೃಷ್ಟಿಕೋನ, ಸ್ಥಳ
- ಸಿಸ್ಟಂ – ರಚಿತ ಸರ್ವರ್ನ ಘಟನೆಗಳು – ಪುಟದ ಲೋಡ್, ಸೆಷನ್ ರಿಫ್ರೆಶ್ಗಳು, api ಕಾಲ್ಗಳು
- ಸಿಸ್ಟಂ – ರಚಿತ ಗ್ರಾಹಕರ ಘಟನೆಗಳು – ಸಿಸ್ಟಮ್ ಪುಶ್ ನೋಟಿಫಿಕೇಷನ್ಗಳು ಮತ್ತು ಟ್ರಿಗ್ಗರ್ಗಳು
- ನಿರ್ದಿಷ್ಟ ದತ್ತಾಂಶದ ಗುಣಲಕ್ಷಣ:
- ಪುಟದ ವೀಕ್ಷಣೆ (URL, ಉಲ್ಲೇಖ, ಬಳಕೆದಾರ ಮಧ್ಯಸ್ಥಿಕೆ, ಸಾಧನ, IP, ಟೈಮ್ಸ್ಟ್ಯಾಂಪ್, ಟ್ರಾಫಿಕ್ ಮೂಲ, ಪ್ರಚಾರ)
- ಪ್ರ್ಯಾಕ್ಟೀಸ್ ಪ್ರಯತ್ನ ಮಟ್ಟದ ದತ್ತಾಂಶ (ಟೈಮ್ಸ್ಟ್ಯಾಂಪ್, ವೀಕ್ಷಣೆ/ಮರು ವೀಕ್ಷಣೆ, ಉತ್ತರದ ಆಯ್ಕೆ, ಮೊದಲ ಬಾರಿ ವೀಕ್ಷಿಸಿದ ಸಮಯ, ಸಮಯ ವ್ಯಯ, ಪರಿಹಾರ ವೀಕ್ಷಣೆ, ಸುಳಿವು ಬಳಕೆ) – ಸೆಷನ್ ಮಟ್ಟದಲ್ಲಿ ಕಲೆಹಾಕಲಾಗಿದೆ.
- ಲರ್ನ್ ನಡವಳಿಕೆಯ ದತ್ತಾಂಶ:
- ಸರ್ಚ್ ಘಟನೆಯ ದತ್ತಾಂಶ (ಟೈಮ್ಸ್ಟ್ಯಾಂಪ್, ಪ್ರಶ್ನೆ, ಫಲಿತಾಂಶ ಹೊಂದಿಸು)
- ಫಲಿತಾಂಶ ಸಂವಾದದ ದತ್ತಾಂಶ (ಟೈಮ್ಸ್ಟ್ಯಾಂಪ್, ಸೂಚಿತ ಫಲಿತಾಂಶದ ಆಯ್ಕೆ, ಫಲಿತಾಂಶ ವಿಜೆಟ್ ಮತ್ತು ಸಂದರ್ಭ, ವಿಜೆಟ್ ಸ್ಥಾನ)
- ಟೆಸ್ಟ್ ಪ್ರಯತ್ನದ ಘಟನೆಯ ಮಟ್ಟದ ದತ್ತಾಂಶ (ಟೈಮ್ಸ್ಟ್ಯಾಂಪ್, ವೀಕ್ಷಣೆ/ಮರು ವೀಕ್ಷಣೆ, ಉತ್ತರದ ಆಯ್ಕೆ, ಮೊದಲ ಬಾರಿ ವೀಕ್ಷಿಸಿದ ಸಮಯ, ಸರಿ, ಸಮಯ ವ್ಯಯ, ಮರುಮಾಹಿತಿ ವೀಕ್ಷಣೆ) – ಸೆಷನ್ ಮಟ್ಟದಲ್ಲಿ ಕಲೆ ಹಾಕಲಾಗಿದೆ.
- ಪ್ರಶ್ನೆಗಳು ಮತ್ತು ಉತ್ತರದ ಮಾಹಿತಿ ಕೇಳುವಿಕೆ (ಶೈಕ್ಷಣಿಕ ವೇದಿಕೆ), ಆರ್ಡರ್ ವಿನಂತಿಯ ಟೈಮ್ಸ್ಟ್ಯಾಂಪ್ ಮತ್ತು ಉತ್ತರದ ಮಾಹಿತಿಗಳು, ಟೈಮ್ಸ್ಟ್ಯಾಂಪ್ಗಳು, ಬಳಕೆದಾರರ ವೋಟಿಂಗ್ ನಡವಳಿಕೆ
- ಪಾವತಿಗಳು (ಬಳಕೆದಾರರ ಗುರುತು, ಬಳಕೆದಾರರ ಇಮೇಲ್ಗಳು, ಮೂರನೇ ವ್ಯಕ್ತಿಯ ಪೇಮೆಂಟ್ ಗೇಟ್ವೇ, ಪೇಮೆಂಟ್ ಗೇಟ್ವೇಯಲ್ಲಿ ವ್ಯವಹಾರದ ಗುರುತಿಸುವಿಕೆ, ಪಾವತಿಯ ವಿಧಾನ (ಕಾರ್ಡ್, ವಾಲ್ಲೇಟ್ ಮುಂತಾದವು), ಟೈಮ್ಸ್ಟ್ಯಾಂಪ್ ಆದೇಶದ ವಿನಂತಿ, ಟೈಮ್ಸ್ಟ್ಯಾಂಪ್ ನಲ್ಲಿ ಪಾವತಿಯ ವೀಕ್ಷಣೆ, ಯಾವುದೇ ಕಡಿತದ ಅನ್ವಯಿಸುವಿಕೆ, ನಿಖರತೆಯ ಆದೇಶಿತ ವಸ್ತುಗಳು)
Embibe ಕಲೆ ಹಾಕುವ ವಿಧಾನದಾದಲ್ಲಿ ಇನ್ನೂ ಅನೇಕ ಪ್ರಾಯೋಗಿಕ ಆಯ್ಕೆಗಳು ದತ್ತಾಂಶದ ಸಂಗ್ರಹದ ಪರಿಕರದಲ್ಲಿ ಸೇರಿಕೊಂಡಿವೆ. ಉದಾಹರಣೆಗೆ, ಈ ಎಲ್ಲಾ ದತ್ತಾಂಶವನ್ನು ಸಂಗ್ರಹಿಸಲು ನಾವು ಹಲವಾರು ವಿಧಾನಗಳನ್ನು ಅವಲಂಬಿಸಿದ್ದೇವೆ. ಬಳಕೆದಾರರ ಪರಸ್ಪರ ಸಂವಹನ ಈವೆಂಟ್ ಸ್ಟ್ರೀಮ್ ಅನ್ನು ಲಾಗ್ ಮಾಡುವುದನ್ನು segment.io ಮತ್ತು Heap ನಂತಹ ತೃತೀಯ ಪ್ಲಗಿನ್ಗಳೊಂದಿಗೆ ಸಂಯೋಜಿಸುವ ಮೂಲಕ ಸಾಧಿಸಲಾಗುತ್ತದೆ. ಸರ್ವರ್ ಕಡೆಯ ಪುಟದ ಜೋಡಣೆ ಮತ್ತು ಸೆಷನ್ ಘಟನೆಯು ಮುಖ್ಯವಾಗಿ ಪರಿಕರಣೆಗೊಂಡಿದೆ ಮತ್ತು noSql ದತ್ತಾಂಶದ ಮೂಲದಲ್ಲಿ ನೂಕಲಾಗಿದೆ. ಬಳಕೆದಾರರ ನಿತ್ಯ ಅಭ್ಯಾಸದ ಪ್ರತಿಕ್ರಿಯೆಯನ್ನು ನಿತ್ಯ ದತ್ತಾಂಶದ ದಾಖಲಾತಿ ಮತ್ತು ಮುಂಭಾಗದ ಅಂಚಿನಿಂದ ಪ್ರಶ್ನೆ ಸೇರಿಸಲು ಪರೀಕ್ಷೆಯ ಫಲಿತಾಂಶವನ್ನು DB ಯಲ್ಲಿ ಸಂಗ್ರಹಿಸಿಡಲಾಗುವುದು.
ದತ್ತಾಂಶ ಸಂಸ್ಕರಣೆ
ಒಂದು ಬಾರಿ ಪ್ರಾಥಮಿಕ ದತ್ತಾಂಶ ಸಂಗ್ರಹ ಆದಮೇಲೆ, ಅದರ ಸಂಸ್ಕರಣೆ, ಉತ್ಕೃಷ್ಟಗೊಳಿಸುವುದು, ಉತ್ಖನನ ಮಾಡುವ ಮತ್ತು ದೃಶ್ಯೀಕರಿಸುವುದು ಮಾಡಬೇಕಾಗುತ್ತದೆ. Embibe ನಲ್ಲಿ, ನಾವು ಸಂಗ್ರಹಿಸಿದ ದತ್ತಾಂಶವನ್ನು ಬಳಸಲು ನಾವು ಈ ಕೆಳಗಿನ ವಿಧಾನಗಳನ್ನು ಅನುಸರಿಸುತ್ತೇವೆ:
- ಆಂತರಿಕ ವರದಿ ಮತ್ತು ತಾತ್ಪೂರ್ತಿಕ ವಿಶ್ಲೇಷಣೆ:
- ಸ್ಪಾರ್ಕ್ ಸ್ಟ್ರೀಮಿಂಗ್ ಮತ್ತು ಹಡೂಪ್ ಮ್ಯಾಪ್ ಬಳಸಿ ಲಾಗ್ ಮೈನಿಂಗ್ ಅನ್ನು ಸೃಷ್ಟಿಸಲು AWS EMR ನಲ್ಲಿ ಬಲಸುವುದರಿಂದ ಕೆಲಸ ಕಡಿಮೆ ಹಿಡಿಯುತ್ತದೆ. ಇದರಿಂದ ಸೃಷ್ಟಿ ಮತ್ತು ನಮ್ಮ ಬಳಕೆದಾರರ GOV ದತ್ತಾಂಶವನ್ನು ಸೆಷನ್ ಹಂತದಲ್ಲಿ ಸಂಗ್ರಹಿಸಿಡಲು ಆಪ್ಡೇಟ್ ಮಾಡಲಾಗುವುದು. ಪ್ರತಿಯೊಂದು ವಿಷಯದ ವಿರುದ್ಧವೂ ಪ್ರತಿ ಬಳಕೆದಾರರ ಶೈಕ್ಷಣಿಕ ಸಾಮರ್ಥ್ಯದ ಪ್ರೊಫೈಲ್ಗಳನ್ನು ಸಂಗ್ರಹಿಸುತ್ತದೆ. GOV ಮತ್ತು GAV ದತ್ತಾಂಶವನ್ನು ಸ್ಥಿತಿಸ್ಥಾಪಕತ್ವದ ಅನ್ವೇಷಣಾ ಸಮೂಹಗಳಲ್ಲಿ ಪರಿಮಾಣವನ್ನು ಅಳೆಯಲು ಸಂಗ್ರಹಿಸಲಾಗಿದೆ.
- ಟ್ರಾಫಿಕ್ ಮಾದರಿಗಳಿಗಾಗಿ ವರದಿ ಮಾಡುವ ದತ್ತಾಂಶವನ್ನು ಸೃಷ್ಟಿಸಲು ಲಾಗ್ ಮೈನಿಂಗ್, ಬಳಕೆದಾರ ಹಣಗಳಿಕೆ, ಪರೀಕ್ಷೆ ಮೇಲೆ ಪರೀಕ್ಷೆಯನ್ನು ನಡೆಸಿ ಸುಧಾರಣೆ, ಹುಡುಕಾಟ ವೈಫಲ್ಯಗಳು ಮತ್ತು ಇತರ ಅಗತ್ಯತೆಗಳು. ದತ್ತಾಂಶದ ವಿಧಾನವೂ ಮತ್ತೆ ಸ್ಥಿತಿಸ್ಥಾಪಕತ್ವದ ಅನ್ವೇಷಣೆಗೆ ಮತ್ತು Kibana ಮತ್ತು Grafana ಡ್ಯಾಶ್ ಬೋರ್ಡ್ ಅನ್ನು ಬಳಸಿ ದೃಶ್ಯೀಕರಿಸಲಾಗಿದೆ.
- ಪ್ರಾಥಮಿಕ ಕಚ್ಚಾ ದತ್ತಾಂಶವನ್ನು HBaseನಲ್ಲಿ HDFS ಮೇಲೆ ಯಾವುದೇ ಅಗತ್ಯ ವಿಶ್ಲೇಷಣೆಯನ್ನು ತಾತ್ಕಾಲಿಕ ಆಧಾರದ ಮೇಲೆ ನಡೆಸಲಾಗುತ್ತದೆ.
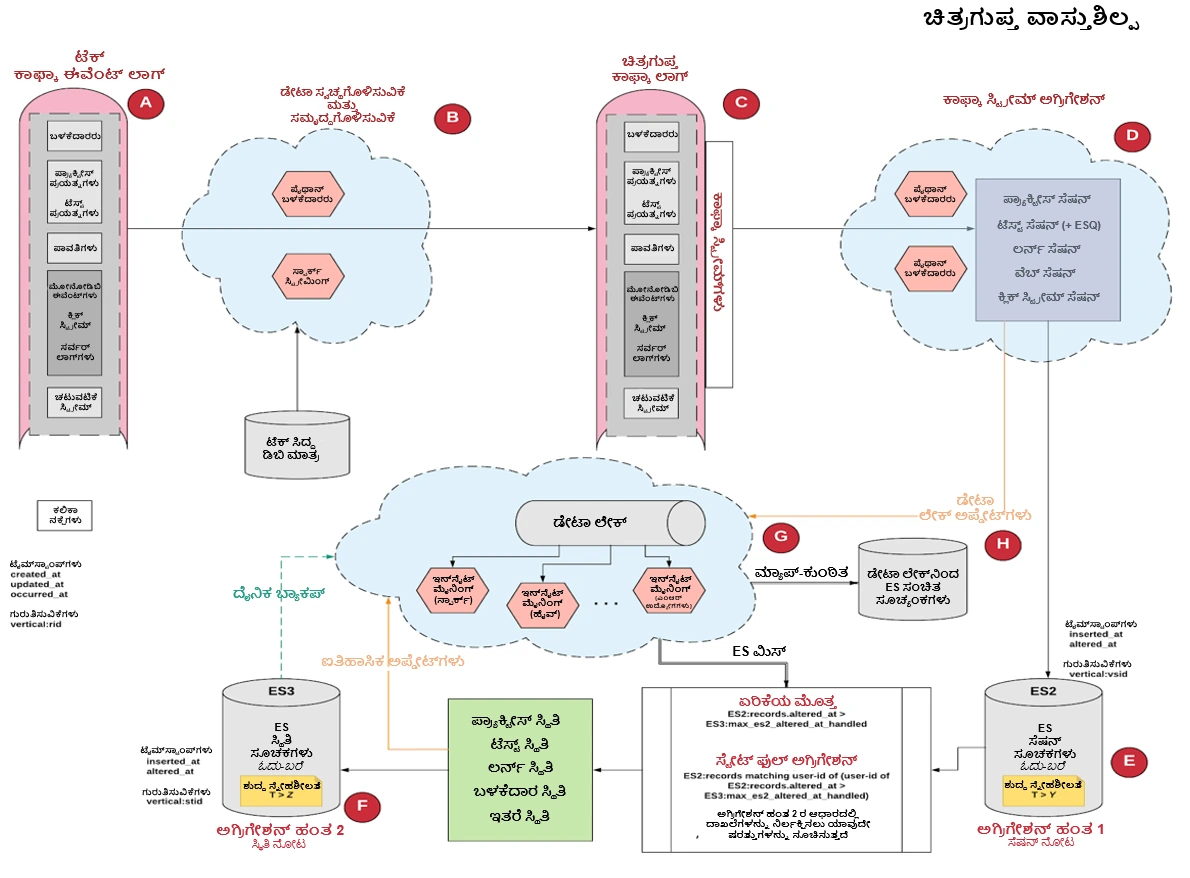
ಚಿತ್ರ 1: ಉನ್ನತ ಮಟ್ಟದಲ್ಲಿ Embibe ನ ದತ್ತಾಂಶ ವಿಜ್ಞಾನ ಪ್ರಯೋಗಾಲದಲ್ಲಿ ಅಭಿವೃದ್ದಿಪಡಿಸಿದ ಬುದ್ದಿವಂತಿಕೆಯನ್ನು ಪುಷ್ಟಿಗೊಳಿಸುವ ದತ್ತಾಂಶದ ರೇಖಾಚಿತ್ರ.
- ತೃತೀಯ ಕಕ್ಷಿ ಉದ್ಯಮ/ಉತ್ಪನ್ನ/ಮಾರುಕಟ್ಟೆಯಲ್ಲಿ ಸ್ವ-ಸಹಾಯ ಪರಿಕರ
- ನಮ್ಮ ಆನ್-ಪೇಜ್ ಮತ್ತು ಇನ್-ಆ್ಯಪ್ ಬಳಕೆದಾರರ ಸಂವಹನದ ದತ್ತಾಂಶವನ್ನು segment.io (ತೃತೀಯ ಕಕ್ಷಿ ಪ್ಲಗ್ ಇನ್) ನಿಂದ ಸೆರೆಹಿಡಿಯಲಾಗಿದೆ. ಇದು ದತ್ತಾಂಶವನ್ನು ವಿವಿಧ ಬಾಹ್ಯ ದತ್ತಾಂಶ ದೃಶ್ಯೀಕರಣ ಪ್ಲಾಟ್ಫಾರ್ಮ್ಗಳಿಗೆ ಸ್ವಯಂ-ಮಾರ್ಗ ಕಲ್ಪಿಸುತ್ತದೆ.
- ಟ್ರಾಫಿಕ್ ಮೂಲಗಳನ್ನು ಒಳಗೊಂಡಂತೆ ವಿಶಾಲ ಮಟ್ಟದ ಟ್ರಾಫಿಕ್ ಮೇಲ್ವಿಚಾರಣೆಗಾಗಿ ಗೂಗಲ್ ಅನಾಲಿಟಿಕ್ಸ್, ಜನಗಣತಿ ಮತ್ತು ಸ್ಥಳ ಮಾಹಿತಿ, ಸಾಧನದ ಸ್ಥಗಿತ, ಪುಟದ ವೀಕ್ಷಣೆ, ಸಮಯದ ವ್ಯಯ, ಸ್ವಾಧೀನ ಮಾಪನಗಳು.
- ವಿಶ್ಲೇಷಣೆಗಾಗಿ ರಾಶಿ ವಿಶ್ಲೇಷಣೆ ಮತ್ತು FE ತಂತಿಸಹಿತ ಎಲ್ಲಾ ಬಳಕೆದಾರರ ಪರಸ್ಪರ ಸಂವಹನಗಳನ್ನು segment.io ಮೂಲಕ ತಳ್ಳುವುದು. ಬಹಳಷ್ಟು ಬಳಕೆದಾರರ ಪರಿವರ್ತನೆ ಕೊಳವೆಗಳು ಮತ್ತು ಹರಿವುಗಳ ಸ್ವಯಂ-ಸೇವೆ ಶೈಲಿಯ ಕ್ರಿಯಾತ್ಮಕ ಸೆಟ್ಟಿಂಗ್ ಅನ್ನು ಅನುಮತಿಸುತ್ತದೆ. ರಾಶಿ ಬಳಕೆದಾರರ ಪರಿವರ್ತನೆ ಕೊಳವೆಗಳು ಮತ್ತು ಹರಿವುಗಳ ಸ್ವಯಂ-ಸೇವೆ ಶೈಲಿಯ ಕ್ರಿಯಾತ್ಮಕ ಸೆಟ್ಟಿಂಗ್ ಅನ್ನು ಅನುಮತಿಸುತ್ತದೆ.




















