

Saas വഴി AI അൺലോക്ക് ചെയ്യുന്നു

വിദ്യാഭ്യാസ സാങ്കേതിക മേഖലയിൽ വിവരങ്ങൾ കണ്ടെത്തി അവ എല്ലാ ഉപയോക്താക്കൾക്കും ലഭ്യമാക്കുക എന്നത് ഒരു പ്രധാന ദൗത്യമാണ്. അത് നടപ്പിലാക്കുന്നതിന്, ഉൽപ്പന്നത്തിന്റെ മൊത്തത്തിലുള്ള ഉപയോക്തൃ അനുഭവവുമായി വിന്യസിച്ചിരിക്കുന്ന പ്രസക്തമായ ടാഗുകൾ ഉപയോഗിച്ച് ഉള്ളടക്കം ടാഗു ചെയ്യുന്നതിന് കമ്പനികൾ ഹ്യൂമൻ അനോട്ടേറ്ററുമാരേയോ വിഷയ വിദഗ്ധരെയോ നിയമിക്കുന്നു.
Embibe ന്റെ നോളജ് ഗ്രാഫിന് 74,000ൽ അധികം നോഡുകൾ ഉണ്ട്, ഓരോന്നും വിജ്ഞാനത്തിന്റെ ഒരു പ്രത്യേക ഘടകത്തെ പ്രതിനിധീകരിക്കുന്നു. കൂടാതെ, 1,89,380 പരസ്പരബന്ധങ്ങളും 2,15,062 അഭിരുചികളും ഉണ്ട്. നൂറുകണക്കിന് സിലബസുകളിലുടനീളം ആയിരക്കണക്കിന് പരീക്ഷകളിലായി ഉള്ളടക്കം വിപുലീകരിക്കുമ്പോൾ, ടാഗിംഗ് പ്രക്രിയ കൂടുതൽ ചെലവേറിയതും സമയമെടുക്കുന്നതുമായി മാറുന്നു. കൂടാതെ, ഡാറ്റാസെറ്റിന്റെ വ്യത്യസ്ത ഉപസെറ്റുകളിൽ പ്രവർത്തിക്കുന്ന ഒന്നിലധികം മനുഷ്യ അനോട്ടേറ്റര്മാര് ഉള്ളതിനാൽ ഒരു ഡാറ്റാസെറ്റിന്റെ മാനുവൽ ടാഗിംഗ് സംഭവിക്കുന്നത് മനുഷ്യ പക്ഷപാതങ്ങള്ക്ക് ഇടയാവുന്നു.
ലൂപ്പ് സെമി-ഓട്ടോമാറ്റിക് ടാഗിംഗ് പ്രക്രിയയിൽ മാനുവൽ പ്രോസസ്സിംഗിന് പകരം ഒരു മനുഷ്യനെ ഉപയോഗിച്ച് മനുഷ്യ ടാഗിംഗുമായി ബന്ധപ്പെട്ട പ്രശ്നങ്ങൾ ലഘൂകരിക്കാൻ മെറ്റാ ടാഗുകളുടെ റാങ്കർ ലക്ഷ്യമിടുന്നു. മെറ്റാ ടാഗുകളുടെ റാങ്കർ എന്നത് വിഷയ വിദഗ്ധർക്കായി നിർമ്മിച്ച ഒരു ഉപകരണമാണ്. വിഷയം, യൂണിറ്റ്, അധ്യായം, ടോപ്പിക്ക്, ആശയം എന്നിവ ടാഗ് ചെയ്യുന്നതിനുള്ള നിർദ്ദേശങ്ങൾ Embibe പ്ലാറ്റ്ഫോം നൽകുന്നു. കൂടാതെ, ചോദ്യത്തിന്റെ കാഠിന്യം, അനുയോജ്യമായ സമയം, ബ്ലൂം ലെവൽ എന്നിവയ്ക്കുള്ള നിർദ്ദേശങ്ങളും ഇത് നൽകുന്നു.
രണ്ട് ഉദാഹരണങ്ങൾ ഉപയോഗിച്ച് ഇത് എങ്ങനെ പ്രവർത്തിക്കുന്നുവെന്ന് നമുക്ക് വിശദീകരിക്കാം.
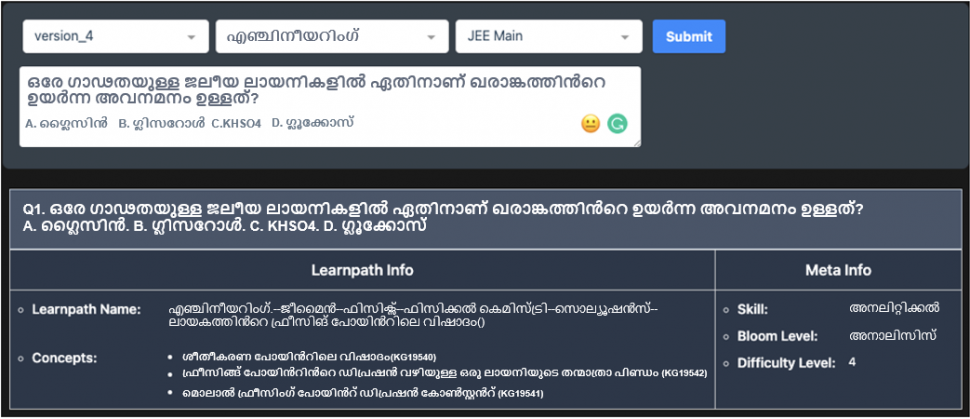
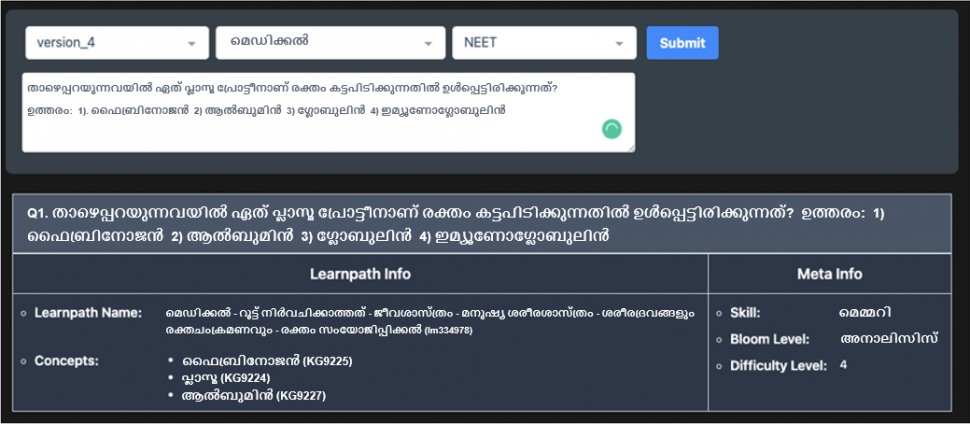
മെറ്റാ ടാഗുകളുടെ റാങ്കർ എക്സ്ട്രീം മൾട്ടിക്ലാസ് ക്ലാസിഫിക്കേഷൻ പ്രോബ്ളത്തെ (XMC) അടിസ്ഥാനമാക്കിയുള്ളതാണ്[1][2]. തന്നിരിക്കുന്ന ഏതൊരു ചോദ്യത്തിനും 74,000-തിലധികം ക്ലാസ്സുകളും ആശയങ്ങളും Embibe ല് ഉണ്ട്. ഈ ക്ലാസുകൾ പരസ്പരവിരുദ്ധമല്ല, അതായത്, അർത്ഥപരമായ ആശയങ്ങൾ ഓവർലാപ്പുചെയ്യുന്നു. XMC യുടെ മറ്റൊരു വെല്ലുവിളി ഡാറ്റാസെറ്റിന്റെ വിതരണമാണ്. എല്ലാ ക്ലാസുകൾക്കും ആശയങ്ങൾക്കും മതിയായ ഡാറ്റാ പോയിന്റുകൾ ഇല്ല, അതായത്, ചില ക്ലാസുകൾക്ക് വളരെയധികം ഡാറ്റ പോയിന്റുകൾ ഉണ്ട്, മറ്റുള്ളവയ്ക്ക് വളരെ കുറച്ച് ഡാറ്റ പോയിന്റുകൾ മാത്രമേ ഉള്ളൂ, ഇത് മോഡൽ പ്രവചനത്തിലൂടെ അവഗണിക്കപ്പെടുന്ന കുറച്ച് ഡാറ്റ പോയിന്റുകളുള്ള ക്ലാസുകളിലേക്ക് നയിച്ചേക്കാം. മെറ്റാ ടാഗുകളുടെ റാങ്കർ സ്വാഭാവിക ഭാഷാ ധാരണയ്ക്കായി അത്യാധുനിക ആഴത്തിലുള്ള പഠന സാങ്കേതിക വിദ്യകൾ പ്രയോജനപ്പെടുത്തുന്നു. ന്യൂറൽ മോഡലുകളെ പരിശീലിപ്പിക്കുന്നതിൽ നോളജ് ഗ്രാഫുകളും ഇത് പ്രയോജനപ്പെടുത്തുന്നു[3]. മോഡലിന്റെ വിശദീകരിക്കാവുന്നതും വ്യാഖ്യാനിക്കാവുന്നതുമായ പ്രവചനങ്ങൾ, പ്രവചന സജ്ജീകരണങ്ങളിൽ ഈ കഴിവ് വിന്യസിക്കാൻ വിശ്വാസത്തെ വളർത്തിയെടുക്കാൻ അക്കാദമിഷ്യന്മാരെ സഹായിക്കുന്നു [4][5]. അത്തരം സമ്പുഷ്ടമായ ഉള്ളടക്കം സ്വയമേവയുള്ള ടെസ്റ്റ് ജനറേഷനും[5][7] പഠന ഫലങ്ങൾ നൽകാനുള്ള കഴിവും പ്രാപ്തമാക്കുന്നു [6].
മെറ്റാ ടാഗ് ജനറേറ്റർ പുസ്തകങ്ങൾ, ചോദ്യങ്ങൾ, പഠന വീഡിയോകൾ എന്നിവയ്ക്കായി AI ഉപയോഗിച്ച് ആയിരക്കണക്കിന് മണിക്കൂർ നീളുന്ന മാനുവൽ ടാഗ് ജനറേഷൻ പ്രക്രിയ ലാഭിച്ചു. വിവിധ ഗ്രേഡുകൾക്കും വിഷയങ്ങൾക്കും വേണ്ടിവരുന്ന വിഷയ വിദഗ്ദ്ധരുടെ ആവശ്യകത ഇത് കുറച്ചു. വീഡിയോ, 3D അസറ്റ് എന്നിവ സൃഷ്ടിക്കുന്നതിനുള്ള സ്പീച്ച് മെറ്റാടാഗുകളും Embibe വികസിപ്പിച്ചുകൊണ്ടിരിക്കുന്നു.
References:
[1] Chang, Wei-Cheng, Hsiang-Fu Yu, Kai Zhong, Yiming Yang, and Inderjit S. Dhillon. “Taming pretrained transformers for extreme multi-label text classification.” In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pp. 3163-3171. 2020.
[2] Dahiya, Kunal, Deepak Saini, Anshul Mittal, Ankush Shaw, Kushal Dave, Akshay Soni, Himanshu Jain, Sumeet Agarwal, and Manik Varma. “DeepXML: A Deep Extreme Multi-Label Learning Framework Applied to Short Text Documents.” In Proceedings of the 14th ACM International Conference on Web Search and Data Mining, pp. 31-39. 2021.[arXiv]
[3] Faldu, Keyur, Amit Sheth, Prashant Kikani, and Hemang Akabari. “KI-BERT: Infusing Knowledge Context for Better Language and Domain Understanding.” arXiv preprint arXiv:2104.08145 (2021).
[4] Gaur, Manas, Keyur Faldu, and Amit Sheth. “Semantics of the Black-Box: Can knowledge graphs help make deep learning systems more interpretable and explainable?.” IEEE Internet Computing 25, no. 1 (2021): 51-59.
[5] Dhavala, Soma, Chirag Bhatia, Joy Bose, Keyur Faldu, and Aditi Avasthi. “Auto Generation of Diagnostic Assessments and Their Quality Evaluation.” International Educational Data Mining Society (2020).
[6] Faldu, Keyur, Aditi Avasthi, and Achint Thomas. “Adaptive learning machine for score improvement and parts thereof.” U.S. Patent 10,854,099, issued December 1, 2020.
[7] Desai, Nishit, Keyur Faldu, Achint Thomas, and Aditi Avasthi. “System and method for generating an assessment paper and measuring the quality thereof.” U.S. Patent Application 16/684,434, filed October 1, 2020.



















