

Saas വഴി AI അൺലോക്ക് ചെയ്യുന്നു

പ്രചോദനം
രാജ്യത്തുടനീളമുള്ള ദശലക്ഷക്കണക്കിന് വിദ്യാർത്ഥികൾ ആഗ്രഹിക്കുന്ന തരത്തിലുള്ള പഠന ഫലങ്ങൾ നേടുന്നതിന് കൂടുതൽ പഠിക്കാനും കഠിനമായി പരിശീലിക്കാനും സ്വന്തമായി ടെസ്റ്റ് ചെയ്യാനുമായി Embibe പതിവായി ഉപയോഗിക്കുന്നു. ഈ പഠന യാത്രയിലുടനീളം, ഒരു കൂട്ടം ചോദ്യങ്ങളിലോ സംശയങ്ങളിലോ അവര് ഇടറിവീഴാനുള്ള സാധ്യതയുണ്ട്. അതിനാൽ, വിദ്യാർത്ഥികൾക്കിടയിൽ ചോദ്യം ചെയ്യൽ എപ്പോഴും പ്രോത്സാഹിപ്പിക്കപ്പെടുന്നുവെന്ന് ഉറപ്പാക്കാന്നതിനുതകുന്ന സംശയ നിവാരണ ഫലങ്ങള് ഞങ്ങൾക്കുണ്ട്.
പേര് സൂചിപ്പിക്കുന്നത് പോലെത്തന്നെ, വിദ്യാർത്ഥികളുടെ സംശയങ്ങൾ നിര്ധാരണം ചെയ്യാന് സഹായിക്കുന്ന ഒരു പ്ലാറ്റ്ഫോമാണ് ഇത്. വിഷയവുമായി ബന്ധപ്പെട്ട വിദഗ്ധർക്ക് ഈ സഹായം നൽകാൻ കഴിയുമെങ്കിലും, ഒരേസമയം ഒന്നിനു പുറകെ ഒന്നായി വരുന്ന സംശയങ്ങളുടെ ആഴത്തിനും വ്യാപ്തിക്കുമനുസരിച്ച് ഓരോ സംശയങ്ങള്ക്കും അപ്പപ്പോള് തന്നെ മാന്വലി നിവാരണം നല്കുകയെന്നത് ഈ വിദഗ്ധരേ വളരെ പ്രയാസകരമാക്കുന്ന ഒന്നാണ്. ഇത്, കൂടുതൽ കാത്തിരിപ്പ് സമയവും കുറഞ്ഞ യൂസർ അനുഭവവും ഉണ്ടാക്കുന്നതിലേക്ക് നയിക്കും.
അവസരം ഉപയോഗപ്പെടുത്തുന്നു
മിക്ക പഠന ഉള്ളടക്കത്തിലും ചിത്രങ്ങളിലും സമവാക്യങ്ങളിലും ചിഹ്നങ്ങളിലുമെല്ലാം ഒളിഞ്ഞിരിക്കുന്ന ഒത്തിരി വിവരങ്ങൾ ഉൾപ്പെട്ടിരിക്കുന്നു. ചിത്രങ്ങളിൽ നിന്നും വാക്കുകളിൽ നിന്നും അര്ത്ഥങ്ങള് വേര്തിരിച്ചെടുക്കുന്നത് ഇപ്പോഴും ഒരു ഡൊമെയ്ൻ-ആശ്രിതവും കഠിനവുമായ ജോലിയാണ്. ഇതിന് വലിയ ഡാറ്റാസെറ്റുകൾ, ഡൊമെയ്ൻ നിർദ്ദിഷ്ട അറിവ്, സ്വാഭാവിക ഭാഷയ്ക്കും ദർശനത്തിനും വേണ്ടിയുള്ള ആഴത്തിലുള്ള പഠന സമീപനങ്ങൾ എന്നിവയിലേക്കുള്ള പ്രവേശനമാര്ഗം ആവശ്യമാണ്.
മിക്ക സംശയ നിവാരണ ഉൽപ്പന്നങ്ങളും സമാനമായ ചോദ്യങ്ങൾ നൽകുന്നതിന് അല്ലെങ്കിൽ ചോദ്യത്തിന് ചുറ്റുമുള്ള ലഭ്യമായ സന്ദർഭത്തെ അടിസ്ഥാനമാക്കി ചോദ്യങ്ങൾക്ക് ഉത്തരം നൽകാൻ കഴിവുള്ള ഒരു സിസ്റ്റം നിർമ്മിക്കുന്നതിന് നിലവിലുള്ള ഉള്ളടക്കത്തിന്റെ കോർപ്പറയെ ഉപയോഗപ്പെടുത്തുന്നു. Embibe ൽ, ഞങ്ങളുടെ ചോദ്യബാങ്കിൽ ദശലക്ഷക്കണക്കിന് ചോദ്യങ്ങളുണ്ട്. ചോദ്യ വാചകം, ചോദ്യത്തിലെ ഡയഗ്രമുകൾ അല്ലെങ്കിൽ കണക്കുകൾ എന്നിവയിൽ നിന്ന് സന്ദർഭോചിതമായ വിവരങ്ങൾ ലഭിക്കുന്നതിന് ഞങ്ങളുടെ അക്കാദമിക കോർപ്പറയിൽ മികച്ച രീതിയിൽ ട്യൂൺ ചെയ്തിരിക്കുന്ന അത്യാധുനിക മോഡലുകൾ ഞങ്ങൾ ഉപയോഗിക്കുന്നു.
സംശയ നിവാരണ ഉൽപ്പന്നം ഉപയോഗിച്ച്, 93% ചോദ്യങ്ങൾക്കും മനുഷ്യ ഇടപെടലിന്റെ ആവശ്യമില്ലാതെ സ്വയമേവ ഉത്തരം നൽകാൻ കഴിയും.
സംശയ നിവാരണ സംവിധാനം നിർമിക്കുന്നു
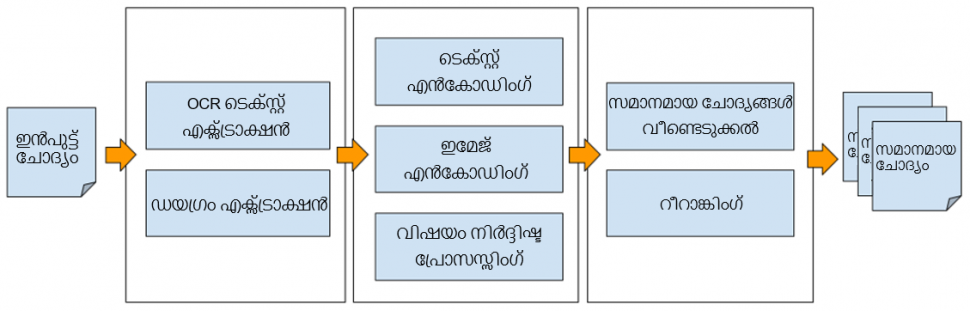
ചിത്രം 1: സംശയ നിവാരണ സംവിധാനത്തിന്റെ ബ്ലോക്ക് ഡയഗ്രം
ഡയഗ്രം വേര്തിരിക്കല്:

സംശയം അപ്പപ്പോള് തന്നെ പരിഹരിക്കാൻ സഹായിക്കുന്നതിന്, ചോദ്യവുമായി ബന്ധപ്പെട്ട എല്ലാ വിശദാംശങ്ങളും ക്യാപ്ചർ ചെയ്യേണ്ടത് പ്രധാനമാണ്. അതിനാൽ, വേര്തിരിക്കപ്പെട്ട ഡയഗ്രമുകളും അര്ത്ഥ സമാനത കണക്കാക്കുന്നതിൽ പരിഗണിക്കപ്പെടുന്നുവെന്ന് ഉറപ്പാക്കാൻ ഞങ്ങൾ ഒരു ഡയഗ്രം എക്സ്ട്രാക്ഷൻ ലേയർ അവതരിപ്പിക്കുന്നു. OCR മൊഡ്യൂളിലേക്കുള്ള ഇൻപുട്ടിൽ ഒരു ഡയഗ്രം ഉള്ളത് അതിനെ ആശയക്കുഴപ്പത്തിലാക്കാം, അതിനാൽ OCR പ്രോസസ്സിംഗിനായി ഇത് ലളിതമാക്കുന്ന ഡയഗ്രം ബൗണ്ടിംഗ് ബോക്സ് നീക്കം ചെയ്യുന്നതിന് ഞങ്ങൾ ചിത്രം പ്രോസസ്സ് ചെയ്യേണ്ടി വരുന്നു. അക്കാദമിക്-ഡൊമെയ്നിനായുള്ള ഞങ്ങളുടെ പ്രാദേശികമായി നിർമ്മിച്ച ഫിഗർ എക്സ്ട്രാക്ഷൻ മോഡൽ സമാനമായ കൃത്യതകൾ കൈവരിക്കുന്നതിലൂടെ ലേറ്റൻസിയിൽ YOLOv5 പോലുള്ള സങ്കീർണ്ണ മോഡലുകളെ സാരമായി മറികടക്കുന്നു.
ഒപ്റ്റിക്കൽ ക്യാരക്ടർ റെക്കഗ്നിഷൻ (OCR):

ചിത്രത്തിലുള്ള കണക്കുകൾ വേര്തിരിച്ചതിനു ശേഷം, ചിത്രത്തിനുള്ളിലെ വാക്കുകള് വേര്തിരിക്കാനും വ്യാകരിക്കാനും ഞങ്ങൾ OCR ലേയർ ഉപയോഗിക്കുന്നു. OCR പ്രകടനം മെച്ചപ്പെടുത്തുന്നതിനായി സ്ക്യു കറക്ഷൻ, ഷാഡോ നീക്കം ചെയ്യൽ, റെസല്യൂഷൻ മെച്ചപ്പെടുത്തൽ, മങ്ങൽ കണ്ടെത്തൽ തുടങ്ങിയ മുൻകൂർ പ്രോസസ്സിംഗ് ഘട്ടങ്ങൾ ചെയ്യുന്നു.
ഇമേജ് എൻകോഡിംഗ്: ചിത്രത്തിലെ അര്ത്ഥ സംബന്ധമായ വിവരങ്ങൾ ക്യാപ്ചർ ചെയ്യുന്ന സാന്ദ്രമായ വെക്ടറിലേക്ക് കണക്കുകൾ എൻകോഡ് ചെയ്യാൻ ഞങ്ങൾ ResNet, EfficientNet പോലുള്ള അത്യാധുനിക കമ്പ്യൂട്ടർ വിഷൻ മോഡലുകൾ ഉപയോഗിക്കുന്നു, അതായത് അർത്ഥപരമായി സമാനമായ ചിത്രങ്ങൾ ചില വ്യത്യസ്ത ചിത്രങ്ങളേക്കാൾ പരസ്പരം അടുത്തായിരിക്കും.
ടെക്സ്റ്റ് എൻകോഡിംഗ്: ചോദ്യ വാചകങ്ങളും ഉത്തരങ്ങളും അവയുടെ വിശദമായ വിശദീകരണങ്ങളും അടങ്ങുന്ന ഞങ്ങളുടെ അക്കാദമിക കോർപ്പറയിലെ മാതൃകയെ പരിശീലിപ്പിച്ച് ട്രിപ്പ്ലെസ് നഷ്ടം, പരസ്പര വിവരങ്ങൾ പരമാവധിയാക്കൽ തുടങ്ങിയ സാങ്കേതിക വിദ്യകൾ പ്രയോജനപ്പെടുത്തി ഞങ്ങൾ സാന്ദ്രമായ വെക്റ്റർ പ്രാതിനിധ്യം പഠിക്കുന്നു. BERT, T5 എന്നിവ പോലുള്ള മുൻകൂട്ടി പരിശീലിപ്പിച്ച ഭാഷാ മോഡലുകൾ ഞങ്ങൾ പ്രയോജനപ്പെടുത്തുന്നു. OCR വേര്തിരിച്ചെടുക്കുന്ന ഭാഗത്തെ സാന്ദ്രമായ വെക്റ്ററുകളാക്കി മാറ്റാൻ ഞങ്ങൾ ഈ എൻകോഡർ മോഡൽ ഉപയോഗിക്കുന്നു, അവ അർത്ഥപരമായി സമാനമായ ചോദ്യങ്ങൾ വീണ്ടെടുക്കാൻ കൂടുതൽ ഉപയോഗിക്കുന്നു.
സമാന ചോദ്യങ്ങൾ വീണ്ടെടുക്കുന്നു: ഞങ്ങളുടെ ചോദ്യബാങ്കിൽ നിലവിലുള്ള എല്ലാ ചോദ്യങ്ങളുമായി ഞങ്ങൾ എൻകോഡ് ചെയ്ത ചിത്രങ്ങളും വാചകങ്ങളും താരതമ്യം ചെയ്യുകയും top-k സമാന ചോദ്യങ്ങൾ വീണ്ടെടുക്കുകയും ചെയ്യുന്നു. ഒരു ചോദ്യത്തിലെ ചിത്രത്തിന്റെ പ്രാധാന്യത്തെ അടിസ്ഥാനമാക്കി വാക്കും ചിത്രവും രണ്ടും ഉണ്ടെങ്കിൽ, കൂടുതൽ സാമ്യമുള്ളത് എടുക്കുന്നതിനുള്ള സാങ്കേതിക വിദ്യകളും ഞങ്ങൾ ഉപയോഗിക്കുന്നു. ദശലക്ഷക്കണക്കിന് റെക്കോഡുകളേക്കാൾ സാന്ദ്രമായ വെക്ടറുകളുടെ കോസൈൻ സമാനത നടപ്പിലാക്കുന്നത് ചെലവേറിയതാണ്. അതിനാൽ, ഞങ്ങളുടെ സിസ്റ്റത്തെ ചെലവു കുറഞ്ഞ രീതിയില് പ്രവർത്തനക്ഷമമാക്കാൻ ഷാർഡിംഗ്, ബക്കറ്റിംഗ്, ക്ലസ്റ്ററിംഗ് എന്നീ സമീപനങ്ങൾ ഞങ്ങൾ പ്രയോജനപ്പെടുത്തുന്നു.
വിഷയ നിർദ്ദിഷ്ട പോസ്റ്റ് പ്രോസസ്സിംഗ്: കെമിക്കൽ സമവാക്യങ്ങൾ കൈകാര്യം ചെയ്യൽ, പുസ്തകത്തില് ഉള്ള ഗണിത പദപ്രയോഗങ്ങൾ തുടങ്ങിയ വിഷയ നിർദ്ദിഷ്ട പോസ്റ്റ് പ്രോസസ്സിംഗ് ടെക്നിക്കുകൾ ഞങ്ങൾ ഉപയോഗിക്കുന്നു. വാചകത്തിൽ അടങ്ങിയിരിക്കുന്ന രാസ സമവാക്യങ്ങളും രാസ ഘടകങ്ങളും അർത്ഥപരമായി സമാനമായ ചോദ്യങ്ങൾ വീണ്ടെടുക്കുന്നതിന് ഒരു പ്രധാന പങ്ക് വഹിക്കുന്നു.
References:
[1] Raffel, Colin, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. “Exploring the limits of transfer learning with a unified text-to-text transformer.” arXiv preprint arXiv:1910.10683 (2019).
[2] Devlin, Jacob, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. “Bert: Pre-training of deep bidirectional transformers for language understanding.” arXiv preprint arXiv:1810.04805 (2018).
[3] Tan, Mingxing, and Quoc Le. “Efficientnet: Rethinking model scaling for convolutional neural networks.” In International Conference on Machine Learning, pp. 6105-6114. PMLR, 20
[4] Faldu, Keyur, Amit Sheth, Prashant Kikani, and Hemang Akabari. “KI-BERT: Infusing Knowledge Context for Better Language and Domain Understanding.” arXiv preprint arXiv:2104.08145 (2021).
[5] Gaur, Manas, Keyur Faldu, and Amit Sheth. “Semantics of the Black-Box: Can knowledge graphs help make deep learning systems more interpretable and explainable?.” IEEE Internet Computing 25, no. 1 (2021): 51-59.
[6] Gaur, Manas, Ankit Desai, Keyur Faldu, and Amit Sheth. “Explainable AI Using Knowledge Graphs.” In ACM CoDS-COMAD Conference. 2020.
[7] Sheth, Amit, Manas Gaur, Kaushik Roy, and Keyur Faldu. “Knowledge-intensive Language Understanding for Explainable AI.” IEEE Internet Computing 25, no. 5 (2021): 19-24.
[8] “#RAISE2020 – Embibe – AI-Powered learning outcomes platform for personalized education”, MyGov India, Oct 2020, https://www.youtube.com/watch?v=kuwFtHgN3qU
[9] Faldu, Keyur, Aditi Avasthi, and Achint Thomas. “Adaptive learning machine for score improvement and parts thereof.” U.S. Patent 10,854,099, issued December 1, 2020.
← AI ഹോം-ലേക്ക് തിരിച്ച്


















