

Saas വഴി AI അൺലോക്ക് ചെയ്യുന്നു

സ്കെയിലിൽ പഠന ഫലങ്ങൾ നൽകുന്നതിനുള്ള ഒരു AI പ്ലാറ്റ്ഫോമാണ് Embibe [5][6]. ഏല്ലാ ഭാഷകളിലും പഠിക്കുന്ന, ലോകമെമ്പാടുമുള്ള വിദ്യാർത്ഥികളോട് ഞങ്ങൾ പ്രതിജ്ഞാബദ്ധരാണ്. ഇന്ത്യയിലെ ദശലക്ഷക്കണക്കിന് വിദ്യാർത്ഥികൾക്ക് പ്രാദേശിക ഭാഷകളിൽ വിദ്യാഭ്യാസ ഉള്ളടക്കം നൽകുക എന്നതാണ് വിവർത്തന പദ്ധതിയുടെ ലക്ഷ്യം. വിദ്യാർത്ഥികൾക്ക് അവരുടെ പഠന യാത്രയിൽ വ്യക്തിഗത പഠനവും പരിശീലനവും മൂല്യനിർണ്ണയ ഉള്ളടക്കവും നൽകിയിട്ടുണ്ടെന്ന് ഉറപ്പു വരുത്തുന്നതിന് ഉള്ളടക്കം ക്യൂറേറ്റ് ചെയ്യുകയോ സൃഷ്ടിക്കുകയോ വിവർത്തനം ചെയ്യുകയോ ചെയ്യേണ്ടത് അനിവാര്യമാണ്. [7][8].
ഉയർന്ന നിലവാരമുള്ള മിക്ക അക്കാദമിക ഉള്ളടക്കങ്ങളും ഇംഗ്ലീഷിൽ ലഭ്യമാണ്. അവ ഇന്ത്യൻ പ്രാദേശിക ഭാഷകളിലേക്കും വിവർത്തനം ചെയ്യാൻ കഴിയുമെങ്കിൽ അത് ഞങ്ങളുടെ വിദ്യാർത്ഥികൾക്ക് വളരെ ഉപകാരപ്രദമാണ്. അതിനായി, ഇന്ത്യയിലെ ഓരോ പ്രധാന പ്രാദേശിക ഭാഷകൾക്കും ഞങ്ങൾ ഇൻ-ഹൗസ് NMT(ന്യൂറൽ മെഷീൻ ട്രാൻസ്ലേഷൻ) മോഡലുകൾ നിർമ്മിച്ചു. ഓരോ മോഡലിനും അക്കാദമിക ഇംഗ്ലീഷ് വാചകം(ങ്ങൾ) ഇൻപുട്ടായും കൂടാതെ നൽകിയിരിക്കുന്ന ടാർഗെറ്റ് ഭാഷയിൽ വിവർത്തനം ചെയ്ത വാചകം(കൾ) ഔട്ട്പുട്ടായും ലഭിക്കും.
നിലവിൽ, ഞങ്ങൾ 11 ഇന്ത്യൻ ഭാഷകളെ പിന്തുണയ്ക്കുന്നു,
- ഹിന്ദി(hi)
- ഗുജറാത്തി(gu)
- മറാത്തി(mr)
- തമിഴ്(ta)
- തെലുങ്ക്(te)
- ബംഗാളി(bn)
- കന്നട(kn)
- ആസാമീസ്(as)
- ഒറിയ(or)
- പഞ്ചാബി(pa)
- മലയാളം(ml)
അക്കാദമിക ഡൊമെയ്നിനായി പ്രത്യേകമായി നിർമ്മിച്ചതല്ലാത്തതിനാൽ ഗൂഗിള് വിവർത്തനം പലപ്പോഴും തെറ്റുകൾ വരുത്താറുണ്ട്. ചില ഉദാഹരണങ്ങൾ ഇതാ:
| English | Google translation | NMT translation |
| which of the following law was given by Einstein: | ഇനിപ്പറയുന്ന നിയമങ്ങളിൽ ഏതാണ് ഐൻസ്റ്റീൻ നൽകിയത്: | താഴെ കൊടുത്തിരിക്കുന്ന നിയമങ്ങളിൽ ഏതാണ് ഐൻസ്റ്റീൻ നൽകിയത്: |
| which one of the following is not alkaline earth metal? | ഇനിപ്പറയുന്നവയിൽ ഏതാണ് ആൽക്കലൈൻ എർത്ത് ലോഹം അല്ലാത്തത്? | താഴെ കൊടുത്തിരിക്കുന്നവയിൽ ഏതാണ് ആൽക്കലൈൻ എർത്ത് ലോഹം അല്ലാത്തത്? |
| Endogenous antigens are produced by intra-cellular bacteria within a host cell. | ഒരു ഹോസ്റ്റ് സെല്ലിനുള്ളിലെ ഇൻട്രാ സെല്ലുലാർ ബാക്ടീരിയയാണ് എൻഡോജെനസ് ആന്റിജനുകൾ നിർമ്മിക്കുന്നത്. | ഒരു ആതിഥേയ കോശത്തിലെ കോശാന്തര ബാക്ടീരിയയാണ് എൻഡോജീനസ് ആന്റിജനുകൾ നിർമ്മിക്കുന്നത്. |
സമീപനം
ആദ്യം മുതൽ NMT മോഡലുകൾ നിർമ്മിക്കുന്നതിന്, നമുക്ക് ധാരാളം ഡാറ്റ ആവശ്യമാണ് (രണ്ട് ദശലക്ഷം വാക്യങ്ങൾ). അതിനാൽ, ഞങ്ങൾ ക്രമേണ മെച്ചപ്പെട്ടുകൊണ്ടിരിക്കുന്ന ഒരു ഫീഡ്ബാക്ക് ലൂപ്പ് നിർമ്മിച്ചു. ഇവിടെ എല്ലാ ഭാഷകളിലുമുള്ള അക്കാദമിക വിവർത്തകരുടെ സഹായം ഞങ്ങൾ സ്വീകരിച്ചു.
അക്കാദമിക വിവർത്തകർക്ക് ഞങ്ങൾ മെഷീൻ വിവർത്തനം ചെയ്ത (NMT ഉപയോഗിച്ച്) വാക്യം(ങ്ങൾ) നൽകുന്നു, തുടർന്ന് മോഡൽ അഡാപ്റ്റീവ് ആയി അപ്ഡേറ്റ് ചെയ്യുന്നതിന് അക്കാദമിക വിവർത്തകരിൽ നിന്നുള്ള ഫീഡ്ബാക്ക് സംയോജിപ്പിക്കുന്നു. മെഷീൻ-വിവർത്തനം ചെയ്ത വാക്യങ്ങളുടെ ഗുണനിലവാരം കാലക്രമേണ മെച്ചപ്പെടുന്നുവെന്ന് ഇത് ഉറപ്പാക്കുന്നു.
മുഴുവൻ പ്രോജക്റ്റിന്റെയും മൊത്തത്തിലുള്ള ഒരു ഘടന കാണിക്കുന്ന ഡയഗ്രം ഇതാ.
അതിനാൽ, “മനുഷ്യന് + AI” എന്ന സംയോജനമാണ് ഞങ്ങളുടെ പരിഹാരം. രണ്ടിലും ഏറ്റവും മികച്ചത് ഞങ്ങള് പ്രയോജനപ്പെടുത്തുന്നു.
ചിത്ര-വിവർത്തനം:
ചിത്ര-വിവർത്തന പ്രശ്നം പരിഹരിക്കുന്നതിനും ഞങ്ങൾ ശ്രമിക്കുന്നു. ഇക്കാര്യത്തില് ഇംഗ്ലീഷില് അടയാളപ്പെടുത്തിയ ഒരു ചിത്രം സിസ്റ്റത്തിലേക്ക് ഫീഡ് ചെയ്യുകയും ടാർഗെറ്റ് ഭാഷയിൽ അടയാളപ്പെടുത്തിയ ഒരു ചിത്രം ഔട്ട്പുട്ട് ആയി നൽകുകയും ചെയ്യും.
ഉദാഹരണത്തിന്, ഈ ഇടത് വശത്തെ ഇൻപുട്ട് ചിത്രം സ്വയമേവ വലതുവശത്തുള്ള ഔട്ട്പുട്ട് ചിത്രത്തിലേക്ക് പരിവർത്തനം ചെയ്യപ്പെടും.

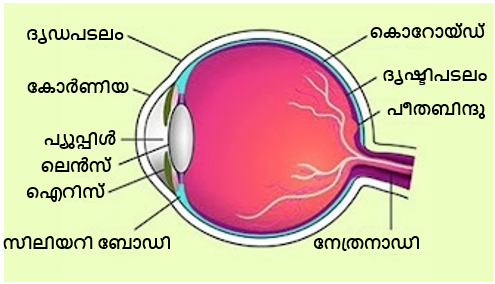
ഈ ഔട്ട്പുട്ട് ചിത്രം മികച്ചതാക്കുന്നതിന് മുകളിൽ നമുക്ക് ചെറിയ ഫോണ്ട്-സ്റ്റൈലിംഗ് അപ്ഡേറ്റുകൾ ചെയ്യാം.
ഈ പ്രോജക്റ്റിനായി, ഞങ്ങൾ ആദ്യം ചിത്രത്തിൽ നിന്ന് ടെക്സ്റ്റ് ലേബലുകൾ കണ്ടെത്തുന്നു, തുടർന്ന് ഓരോ ടെക്സ്റ്റ് ലേബലിനും OCR ചെയ്യുക, തുടർന്ന് ന്യൂറൽ മെഷീൻ ട്രാൻസ്ലേഷൻ API-കൾ ഉപയോഗിച്ച് അവ വിവർത്തനം ചെയ്യുക, അവസാനം വിവർത്തനം ചെയ്ത ടെക്സ്റ്റ് ചിത്രത്തിലേക്ക് അതത് സ്ഥലത്ത് ഇടുക.
അതിനാൽ, ഗുണനിലവാരത്തിൽ വിട്ടുവീഴ്ച ചെയ്യാതെ വിവർത്തനത്തിന്റെ ആകെ ചെലവ് എങ്ങനെ ഗണ്യമായി കുറയ്ക്കാമെന്ന് ഞങ്ങൾ കണ്ടു. ടെക്സ്റ്റ് ട്രാൻസ്ലേഷൻ ഓട്ടോമേഷൻ കാരണം, മനുഷ്യ വിവർത്തകരുടെ സ്വമേധയാലുള്ള ജോലി ~75% മുതൽ 80% വരെ കുറയുകയും അവരുടെ ഉൽപ്പാദനക്ഷമത ഗണ്യമായി വർദ്ധിപ്പിക്കുകയും ചെയ്തു. ഇത് ഒടുവിൽ വിവർത്തനത്തിന്റെ ആകെ ചെലവ് കുറച്ചു.
ഈ NMT മോഡലുകളുടെ പ്രകടനം മെച്ചപ്പെടുത്താൻ നമുക്ക് ഭാവിയിൽ ഇനിയും വളരെയധികം കാര്യങ്ങൾ ചെയ്യാനുണ്ട്. KI-BERT[2] ഉപയോഗിച്ച് ഈ NMT മോഡലുകളിലേക്ക് നമ്മുടെ ആന്തരിക അക്കാദമിക് വിജ്ഞാന ഗ്രാഫിൽ നിന്നുള്ള അറിവ് പ്രേരിപ്പിക്കാൻ ശ്രമിക്കാം. വിജ്ഞാന ഗ്രാഫുകളിൽ നിന്നുള്ള കൂടുതൽ പ്രസക്തമായ അറിവ്, NMT മോഡലുകളിൽ ഞങ്ങൾ ഉപയോഗിക്കുന്ന ട്രാൻസ്ഫോർമറുകൾ പോലെയുള്ള ശ്രദ്ധാധിഷ്ഠിത മോഡലുകളുടെ ദൃഢത മെച്ചപ്പെടുത്താൻ കഴിയും [3][4].
References
[3] Gaur, Manas, Keyur Faldu, and Amit Sheth. “Semantics of the Black-Box: Can knowledge graphs help make deep learning systems more interpretable and explainable?.” IEEE Internet Computing 25, no. 1 (2021): 51-59
[4] Sheth, Amit, Manas Gaur, Kaushik Roy, and Keyur Faldu. “Knowledge-intensive Language Understanding for Explainable AI.” IEEE Internet Computing 25, no. 5 (2021): 19-24.
[5] “#RAISE2020 – Embibe – AI-Powered learning outcomes platform for personalized education”, MyGov India, Oct 2020, https://www.youtube.com/watch?v=kuwFtHgN3qU
[6] Faldu, Keyur, Aditi Avasthi, and Achint Thomas. “Adaptive learning machine for score improvement and parts thereof.” U.S. Patent 10,854,099, issued December 1, 2020.
[7] Dhavala, Soma, Chirag Bhatia, Joy Bose, Keyur Faldu, and Aditi Avasthi. “Auto Generation of Diagnostic Assessments and Their Quality Evaluation.” International Educational Data Mining Society (2020).
[8] Faldu, Keyur, Achint Thomas, and Aditi Avasthi. “System and method for recommending personalized content using contextualized knowledge base.” U.S. Patent Application 16/586,512, filed October 1, 2020.
← AI ഹോം-ലേക്ക് തിരിച്ച്


















