
ഒരു എഡ്ടെക് പ്ലാറ്റ്ഫോം എന്ന നിലയിൽ, വിദ്യാർത്ഥികൾക്ക് അവരുടെ പഠന ആവശ്യകതകൾ നിറവേറ്റുന്നതിനുവേണ്ടി നൽകാൻ കഴിയുന്ന പഠനോപാധികളുടെ ഒരു വലിയ കൂട്ടം Embibe ക്യൂറേറ്റ് ചെയ്യുകയും നിയന്ത്രിക്കുകയും ചെയ്യുന്നു. ഏതൊരു പഠന ആശയവും ഉപയോഗിച്ച് ഉപയോക്താവിനെ ബോധവത്കരിക്കുന്നതിന് വീഡിയോകൾ, എക്സ്പ്ലെയിനറുകൾ, സംവേദനാത്മക പഠന ഘടകങ്ങൾ എന്നിവ അടങ്ങിയ ഉള്ളടക്കം ഈ ഉള്ളടക്ക പൂളിൽ പ്രാഥമികമായി അടങ്ങിയിരിക്കുന്നു. കൂടാതെ, കളികളിലൂടെയുള്ള പരിശീലനവും ടെസ്റ്റ് അനുഭവങ്ങളും പ്രദാനം ചെയ്യുന്നതിന് ബുദ്ധിപരമായി ഒരുമിച്ച് ചേർക്കാൻ കഴിയുന്ന ചോദ്യങ്ങൾ ഇതിൽ അടങ്ങിയിരിക്കുന്നു. Embibe-ൽ, പരിശീലനത്തിനായി ടെസ്റ്റ് സ്റ്റോറിലൈനിനു കീഴിലുള്ള യൂസർ ഇടപഴകൽ, നിർണായകമായ അക്കാദമിക പെരുമാറ്റം, ടെസ്റ്റ്-ടേക്കിംഗ്, ടെസ്റ്റ്-ലെവൽ, യൂസർ അറ്റെംമ്പ്റ്റുകളുമായി ബന്ധപ്പെട്ട പ്രത്യേകതകൾ എന്നിവ നൽകുന്നു. അത് വിദ്യാർത്ഥിയെ പഠനയാത്രയില് നയിക്കാനും അവരുടെ പരമാവധി സാധ്യതകൾ അൺലോക്ക് ചെയ്യാനും സഹായിക്കുന്നു. പരിശീലനത്തിൻ്റെയും ടെസ്റ്റ് സവിശേഷതകളുടെയും പ്രാധാന്യം കണക്കിലെടുത്ത്, പരമാവധി യൂസര് ഇടപഴകലും നിലനിർത്തലും കൈവരിക്കുന്നതിൽ ഞങ്ങൾ വിശ്വസിക്കുന്നു.
ചോദ്യ ശേഖരം തയ്യാറാക്കുന്ന വിവിധ സ്രോതസ്സുകളുണ്ട് – Embibe ല് തന്നെയുള്ള അധ്യാപകരും, വിഷയ വിദഗ്ധരും, അക്കാദമിക കൺസൾട്ടൻ്റുമാരും മറ്റ് വിവിധ ഉദ്യോഗസ്ഥരും ഈ പ്രക്രിയയിൽ ഏർപ്പെട്ടിരിക്കുന്നു. പ്രശസ്ത പാഠപുസ്തകങ്ങളിൽ നിന്നും റഫറൻസ് മെറ്റീരിയലുകളിൽ നിന്നുമുള്ള ചോദ്യങ്ങളും പൂളിൽ അടങ്ങിയിരിക്കുന്നു. ഉള്ളടക്ക പൂൾ ഡ്രൈവ് ചെയ്യുന്നതിൽ നിരവധി എൻ്റിറ്റികളുടെ പങ്കാളിത്തവും ഇടപഴകൽ ഡ്രൈവ് ചെയ്യുന്നതിൽ ഉള്ളടക്കത്തിൻ്റെ പ്രാധാന്യവും കണക്കിലെടുക്കുമ്പോൾ, ഉള്ളടക്കത്തിൻ്റെ ഗുണനിലവാരം ട്രാക്ക് ചെയ്യേണ്ടത് ആവശ്യമാണ്. ഉള്ളടക്ക ഡ്യൂപ്ലിക്കേഷൻ, ചോദ്യം ശരിയാക്കുന്നതിലുള്ള പ്രശ്നങ്ങൾ, അപൂർണ്ണമായ ചോദ്യങ്ങൾ, തെറ്റായ മെറ്റാ ടാഗിംഗ് എന്നിങ്ങനെ, സ്കെയിലിൽ ഉള്ളടക്ക ക്യൂറേഷനുമായി ബന്ധപ്പെട്ട വിവിധ ഗുണനിലവാര സംബന്ധമായ പ്രശ്നങ്ങൾ ഉണ്ട്. ഈ ലേഖനത്തിൽ, ഉള്ളടക്ക ഡ്യൂപ്ലിക്കേഷൻ പ്രശ്നവും അത് പരിഹരിക്കാൻ Embibe ൽ ഉപയോഗിക്കുന്ന ഇൻ്റലിജൻ്റ് സിസ്റ്റവും ഞങ്ങൾ ചർച്ച ചെയ്യും.
ഉള്ളടക്കം ഇരട്ടിക്കലും അപഗ്രഥനവും
സിസ്റ്റത്തിലെ ഉള്ളടക്കം ഇരട്ടിക്കല് (ടെസ്റ്റ്/പ്രാക്ടീസ് പ്രശ്നങ്ങൾ/ചോദ്യങ്ങൾ) എന്നത് യൂസർ ഇടപഴകലിനെ പ്രതികൂലമായി ബാധിക്കുന്ന പ്രശ്നങ്ങളിലൊന്നാണ്. നന്നായി മനസ്സിലാക്കാൻ, “ഒരു യൂസർ സ്ക്രോൾ ചെയ്യുന്ന തിരക്കിലായിരിക്കുമ്പോൾ ഒരേ വീഡിയോ/ചിത്രം തന്നെ ആവർത്തിച്ച് പ്രദർശിപ്പിക്കുന്ന ഫേസ്ബുക്ക്/ഇന്സ്റ്റഗ്രാമുമായി” ഇതിനെ താരതമ്യം ചെയ്യാം. ഇത് യൂസർ ഇടപഴകലിനെ തടസ്സപ്പെടുത്തുന്നുവെന്നത് സമ്മതിക്കേണ്ടതാണ്. ഏറ്റവും മോശമായ സാഹചര്യത്തിൽ അത് യൂസറിനെ എന്നന്നേക്കുമായി പ്ലാറ്റ്ഫോമിൽ നിന്ന് അകറ്റുകയും ചെയ്യും. അതുപോലെ, ഒരേ ചോദ്യം തന്നെ ഒരേ പരിശീലനത്തിലോ ടെസ്റ്റ് സെഷനുകളിലോ വിദ്യാർത്ഥിക്ക് നൽകുകയാണെങ്കിൽ, അത് തീർച്ചയായും യൂസർ ഡ്രോപ്പ്-ഓഫിലേക്ക് സംഭാവന ചെയ്യും.
Embibe ൽ, ഈ പ്രശ്നം കൈകാര്യം ചെയ്യാൻ, സിന്ടാക്സ് (എഡിറ്റ്-ഡിസ്റ്റൻസ്) അധിഷ്ഠിത അളവുകളും ചോദ്യങ്ങളുടെ തനിപ്പകർപ്പുകൾ തിരിച്ചറിയാൻ ആഴത്തിലുള്ള ലേണിംഗ് അധിഷ്ഠിത (റെസ്നെറ്റ്-18 കൺവ്യൂഷണൽ ന്യൂറൽ നെറ്റ്വർക്ക് ആർക്കിടെക്ചർ) വെക്റ്റർ സാമ്യതകളും ഉൾക്കൊള്ളുന്ന ഒരു ഹൈബ്രിഡ് സമീപനം ഞങ്ങൾ ഉപയോഗിച്ചു. ഡീഡ്യൂപ്ലിക്കേഷൻ പൈപ്പ്ലൈൻ നടപ്പിലാക്കാൻ, പുസ്തക ഉള്ളടക്കത്തെക്കുറിച്ചുള്ള ഫുൾ-ടെക്സ്റ്റ് അന്വേഷണങ്ങള്, ഡെൻസ് വെക്ടർ ഫീൽഡുകളിലെ സമീപകാല സ്ക്രിപ്റ്റ് സ്കോർ അന്വേഷണങ്ങള് പോലുള്ള ഇലാസ്തിക തിരയലിൻ്റെ (ലൂസീൻ) പ്രധാന ഫംഗ്ഷണാലിറ്റികൾ ഞങ്ങൾ ഉപയോഗിക്കുന്നു. ഞങ്ങളുടെ പഠനോപാധികളില് (ചോദ്യങ്ങൾ) പുസ്തകങ്ങളിലുള്ളത് കൂടാതെ (ചോദ്യപാഠം, ഉത്തര വാചകം) ഇമേജ്/ചിത്ര വിവരങ്ങളും (ചിത്രങ്ങൾ, ഡയഗ്രാമുകൾ മുതലായവ) അടങ്ങിയിരിക്കുന്നു. കൂടാതെ ഉള്ളടക്ക പൂളിൽ നിന്ന് കൃത്യമായ ഡ്യൂപ്ലിക്കേറ്റ് കൌണ്ടർപാർട്ടുകളെ തിരിച്ചറിയാൻ പൈപ്പ്ലൈൻ അവ രണ്ടും പരിഗണിക്കുന്നു. സിസ്റ്റത്തിലേക്ക് ഡ്യൂപ്ലിക്കേറ്റ് ചോദ്യങ്ങൾ സൃഷ്ടിക്കുന്നതും ഉൾപ്പെടുത്തുന്നതും തടയുന്നതിന് ഒരു തത്സമയ യൂട്ടിലിറ്റി ഞങ്ങൾ പ്രവർത്തനക്ഷമമാക്കിയിട്ടുണ്ട്; ഇത് ഇരട്ടിക്കലിനുള്ള ഒരു ഗേറ്റ് കീപ്പിംഗ് പോലെ പ്രവർത്തിക്കുന്നു.
ചുവടെ ചിത്രീകരിച്ചിരിക്കുന്ന ഒരു ഡാറ്റാ ഫ്ലോ ഡയഗ്രം വഴി ഈ പൈപ്പ്ലൈൻ സംഗ്രഹിക്കാൻ ഞങ്ങൾ ശ്രമിക്കുന്നു:
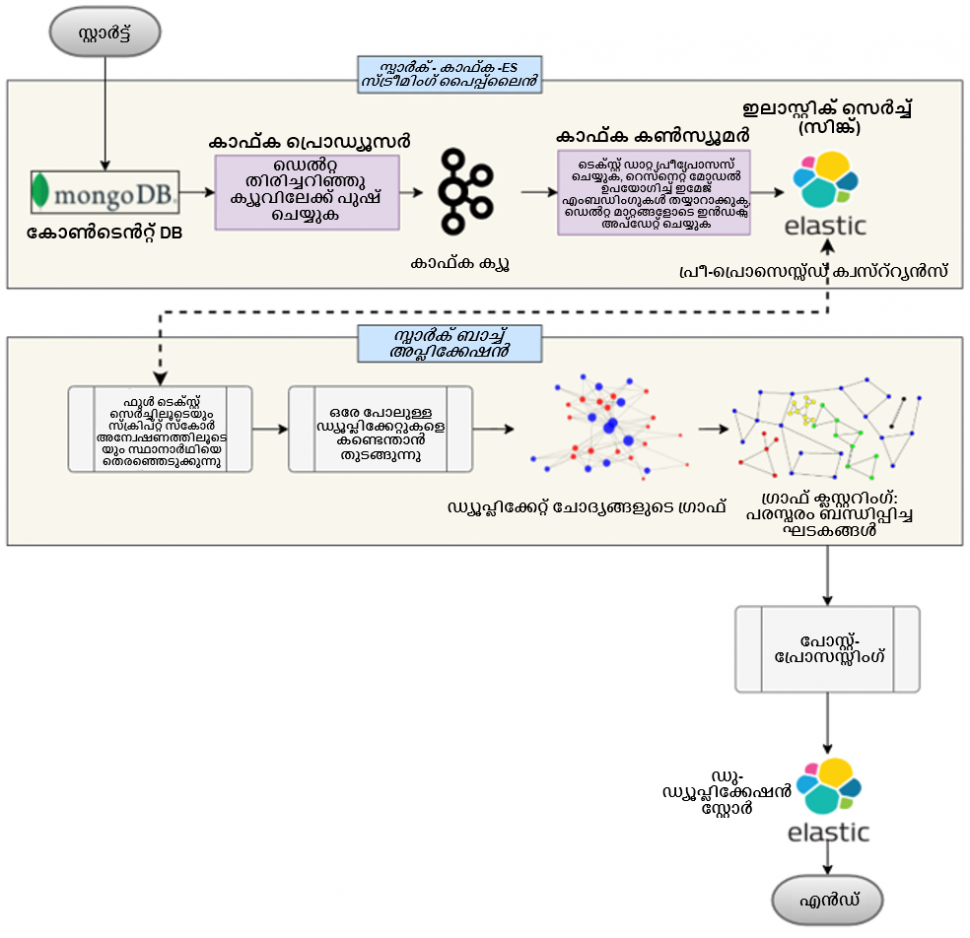
തുടക്കം തിരഞ്ഞെടുക്കൽ:
ഉള്ളടക്ക ഇരട്ടിക്കല് പൈപ് ലൈനിന്, തുടക്കം തിരഞ്ഞെടുക്കൽ/ട്യൂണിംഗ് ആണ് പ്രശ്നത്തിൻ്റെ കാതൽ. സമാനവും ഡ്യൂപ്ലിക്കേറ്റ് അല്ലാത്തതുമായ ചോദ്യങ്ങളെ ഡ്യൂപ്ലിക്കേറ്റിൽ നിന്ന് വേർതിരിക്കാൻ ഇത് സഹായിക്കുന്നു. ഇവിടെ, ഉചിതമായ പരിധികൾ തിരിച്ചറിയുന്നതിന്, ലേബൽ ചെയ്ത ഡാറ്റാസെറ്റ് തയ്യാറാക്കുന്നതിന് ഞങ്ങൾ വിഷയ വിദഗ്ധരുടെ സഹായം സ്വീകരിച്ചിട്ടുണ്ട്. അവിടെ അവർക്ക് ഒരു ആങ്കർ ചോദ്യവും പങ്കെടുക്കുന്നവരുടെ പട്ടികയും നൽകിയിട്ടുണ്ട്. ജോടികളെ ഡ്യൂപ്ലിക്കേറ്റ് ആണ് അല്ലെങ്കിൽ ഡ്യൂപ്ലിക്കേറ്റ് അല്ല എന്ന് അടയാളപ്പെടുത്താൻ അവരോട് ആവശ്യപ്പെട്ടു. കാൻഡിഡേറ്റ് ജനറേഷനായി, ഇലാസ്തിക തിരയലിൻ്റെ ഫുൾ-ടെക്സ്റ്റ് അന്വേഷണങ്ങളും ഇമേജ് ഡെൻസ് വെക്ടറുകളിലെ സ്ക്രിപ്റ്റ് സ്കോർ അന്വേഷണങ്ങളും ഉപയോഗിച്ച് ഉള്ളടക്ക പൂളിൽ നിന്ന് മികച്ച k വിദ്യാര്ഥികളെ തിരഞ്ഞെടുത്തു.
ഇപ്പോൾ, ശരിയായ തുടക്ക മൂല്യം തിരഞ്ഞെടുക്കുന്നതിന്, ലേബൽ ചെയ്ത ഡാറ്റാസെറ്റിന് പകരം പരമാവധി കൃത്യത സ്കോർ ഒബ്ജക്റ്റീവ് ഉപയോഗിച്ച് വ്യത്യസ്ത തുടക്ക മൂല്യങ്ങളിൽ (പരിധി: 0.5 മുതൽ 1.0, സ്റ്റെപ്പ്-സൈസ്: 0.05) ഒരു ഗ്രിഡ് തിരയൽ ഉപയോഗിച്ചു. ഇവിടെ ആങ്കർ ചോദ്യങ്ങൾക്കായി മികച്ച k കാൻഡിഡേറ്റുകൾ ജനറേറ്റ് ചെയ്യുകയും കൃത്യത നമ്പറുകൾ വ്യത്യസ്ത തുടക്ക മൂല്യങ്ങളിൽ നേടുകയും ചെയ്തു. പരമാവധി കൃത്യത നൽകുന്ന സമാന സ്കോർ തുടക്കം ഫൈനല് പരിധി മൂല്യമായി തിരഞ്ഞെടുത്തു.
ബെഞ്ച്മാർക്കിംഗ് പ്രക്രിയ
ഹോൾഡ്-ഔട്ട് ലേബൽ ചെയ്ത സെറ്റിന് പകരം, സൂചിപ്പിച്ച ഡ്യൂപ്ലിക്കേറ്റ് തിരിച്ചറിയൽ പ്രക്രിയയുടെ ഒരു ബെഞ്ച്മാർക്കിംഗ് നടത്തി. ചുവടെയുള്ള പട്ടിക അതിൻ്റെ പ്രത്യേകതകൾ പരാമർശിക്കുന്നു:
| ഡാറ്റ | സെറ്റ് സൈസ് | കൃത്യത (ശരിയായി അടയാളപ്പെടുത്തിയിരിക്കുന്നു) |
| ലേബൽ ചെയ്ത ചോദ്യ ജോടികൾ അടങ്ങിയിരിക്കുന്നു: വാചകം മാത്രം, വാചകം + ചിത്രം, ചിത്രം മാത്രം | 5114 | 83.1% (4250) |
| ലേബൽ ചെയ്ത ചോദ്യ ജോടികൾ അടങ്ങിയിരിക്കുന്നു: വാചകം + ചിത്രം, ചിത്രം മാത്രം | 2710 | 80.1% (2193) |
നിഗമനവും ഭാവി പ്രവർത്തനവും
പല മെഷീൻ ലേണിംഗ് ടാസ്ക്കുകളിലും 80%+ കൃത്യത മതിയെങ്കിലും, Embibe പ്രവർത്തിക്കുന്ന സ്കെയിലിന് കൈകള് ഉപയോഗിച്ചുള്ള വെരിഫിക്കേഷൻ കുറയ്ക്കുന്നതിന് കൂടുതൽ കൃത്യമായ മോഡലുകൾ ആവശ്യമാണ്. സെമാൻ്റിക് സാമ്യത അടിസ്ഥാനമാക്കിയുള്ള ടെക്സ്റ്റ് മൈനിംഗിലെ നിലവിലെ വികസനത്തിനൊപ്പം, 90%+ കൃത്യത ലക്ഷ്യമാക്കി ഡെൻസ് വെക്ടർ (ഇമേജും ടെക്സ്റ്റ് എംബഡിംഗും) അടിസ്ഥാനമാക്കിയുള്ള ഉള്ളടക്ക സാമ്യതയുള്ള അൽഗോരിതം Embibe വികസിപ്പിക്കുന്നു.




















