
ആമുഖം:
75,000-ത്തിലധികം നോഡുകൾ ഉൾക്കൊള്ളുന്ന ഒരു പാഠ്യപദ്ധതി ബഹുമുഖ ഗ്രാഫാണ് Embibe ൻ്റെ നോളജ് ഗ്രാഫ്. ആശയങ്ങൾ എന്നും വിളിക്കപ്പെടുന്ന ഈ നോഡുകളില് ഓരോന്നും അക്കാദമിക അറിവിൻ്റെ ഒരു പ്രത്യേക യൂണിറ്റിനെ പ്രതിനിധീകരിക്കുന്നു. അവയ്ക്കിടയിലുള്ള ലക്ഷക്കണക്കിന് പരസ്പര ബന്ധങ്ങൾ, ഈ ആശയങ്ങളൊന്നും സ്വതന്ത്രമല്ലെന്നും പകരം മറ്റ് ആശയങ്ങളുമായി എങ്ങനെ ബന്ധപ്പെട്ടിരിക്കുന്നുവെന്നും കാണിക്കുന്നു.
Embibe അതിൻ്റെ ഉള്ളടക്കം വിപുലീകരിക്കുന്നതിനനുസരിച്ച് നോളജ് ഗ്രാഫും നിരന്തരം വികസിച്ചുകൊണ്ടിരിക്കുന്നു. ചരിത്രപരമായി, ഗ്രാഫിൻ്റെ ഭാഗങ്ങൾ ക്യൂറേറ്റ് ചെയ്യുന്നതിനുള്ള സ്മാർട്ട് ഓട്ടോമേഷൻ സഹിതം വിദഗ്ധരായ അധ്യാപകരുടെ സ്വമേധയാലുള്ള പരിശ്രമഫലമായാണ് ഇത് നിർമ്മിച്ചിരിക്കുന്നത്. എന്നിരുന്നാലും, ഗ്രാഫിൻ്റെ പുതിയ നോഡുകൾ സ്വയമേവ കണ്ടെത്തുന്നതും അക്കാദമിക അറിവ് സ്പെക്ട്രത്തിൻ്റെ കൂടുതൽ ഭാഗങ്ങൾ ഉൾക്കൊള്ളുന്നതിനായുള്ള ഗ്രാഫ് വിപുലീകരണവും ലക്ഷ്യമിട്ടുള്ള ഗവേഷണത്തിലാണ് Embibe നിക്ഷേപം നടത്തുന്നത്. ലേബൽ ചെയ്ത ഡാറ്റാ സെറ്റും BERT അധിഷ്ഠിത മോഡലും ഉപയോഗിച്ച് ഒരു നോളജ് ഗ്രാഫിൽ പുതിയ നോഡുകൾ കണ്ടെത്താനും പദസമുച്ചയങ്ങളും അവയുടെ പ്രസക്തി നിലകളും നൽകാനും അക്കാദമികമായി രൂപകല്പന ചെയ്ത വ്യത്യസ്തമായ ഫ്രേസ് എക്സ്ട്രാക്റ്റർ ഞങ്ങളെ പ്രാപ്തമാക്കുന്നു.
അക്കാദമികമായി ഡിഫറെൻഷിയേറ്റ് ചെയ്ത ഫ്രേസ് എക്സ്ട്രാക്ടർ:
ഒരു പാഠ പുസ്തകത്തിൽ നിന്നുള്ള വാചകങ്ങളിലെ പ്രധാന ഭാഗങ്ങള്ക്ക് സ്വയമേവ അടിവരയിടുന്ന സംവിധാനമാണ് അക്കാദമിക്ക് ഡിഫറൻഷ്യേറ്റഡ് ഫ്രേസ് എക്സ്ട്രാക്റ്റർ (ADPE). ഒരു വിദ്യാർത്ഥി പുസ്തകം വായിക്കുമ്പോൾ പ്രധാന ആശയങ്ങൾ എങ്ങനെ അടിവരയിടുന്നു എന്നതിന് സമാനമാണിത്. ഘടനയില്ലാത്ത വാചകത്തിൽ നിന്ന് ആശയങ്ങൾ വേർതിരിച്ചെടുക്കുക എന്നതാണ് ഇതിൻ്റെ പ്രാഥമിക ലക്ഷ്യം, മിക്ക ആശയങ്ങളും പുസ്തക വാചകത്തിൻ്റെ ഉപവിഭാഗങ്ങളായി തിരിച്ചറിയാൻ കഴിയുമെന്ന അനുമാനത്തിലൂടെയാണ് ഇത് നയിക്കപ്പെടുന്നത്.
കീ-ഫ്രേസ് എക്സ്ട്രാക്ഷനിലും പേരുള്ള എൻ്റിറ്റി തിരിച്ചറിയലിലും വിപുലമായ പ്രവർത്തനമുണ്ട്. എന്നിരുന്നാലും, ഒരു പാഠ്യ പുസ്തകത്തിൽ നിന്ന് ആശയങ്ങൾ യാന്ത്രികമായി വേർതിരിച്ചെടുക്കുന്നത് ഒരു വെല്ലുവിളി നിറഞ്ഞ ജോലിയാണ്. നിർവചനപ്രകാരമുള്ള ആശയം വേർതിരിച്ചെടുക്കൽ സമഗ്രമാണ്, അതായത് എല്ലാ ആശയങ്ങളും വേർതിരിച്ചെടുക്കേണ്ടതുണ്ട്. അവ ഒരു അധ്യായത്തിൻ്റെ ആശയ ശ്രേണിയുടെ ഭാഗമാണ്, മാത്രമല്ല അധ്യായത്തിൻ്റെ സന്ദർഭവും അവയുടെ സഹ-സംഭവവും പ്രസക്തിയും വിവരിക്കുന്നു. കീ-ഫ്രേസ് എക്സ്ട്രാക്ഷനിൽ നിന്ന് ഇത് വ്യത്യസ്തമാണ്, കാരണം രണ്ടാമത്തേത് ഒരു ലേഖനത്തെ വിവരിക്കുന്ന ടോപ്പ്-എൻ കീവേഡുകളിൽ ശ്രദ്ധ കേന്ദ്രീകരിക്കുന്നു, ഇവ പ്രസക്തമായ ഏതെങ്കിലും അർത്ഥവത്തായ ശ്രേണിയിൽ ആയിരിക്കണമെന്നില്ല. കൂടാതെ, പേരുള്ള എൻ്റിറ്റി എക്സ്ട്രാക്ഷനിൽ നിന്ന് ഇത് വ്യത്യസ്തമാണ്, കാരണം ഈ ടാസ്ക്, മുൻനിർദിഷ്ട ക്ലാസുകളിൽ (ഉദാ: ലൊക്കേഷൻ, വ്യക്തി, ORG) ഉൾപ്പെടുന്ന എൻ്റിറ്റികളുടെ വ്യക്തിഗത സംഭവങ്ങളെ, വാക്യങ്ങൾ പോലെയുള്ള ചെറിയ ഗ്രന്ഥങ്ങളിൽ നിന്ന് വേർതിരിച്ചെടുക്കുന്നതിൽ ശ്രദ്ധ കേന്ദ്രീകരിക്കുന്നു. അതുല്യവും അനുബന്ധവുമായ ആശയങ്ങൾ വേര്തിരിച്ചെടുക്കുക എന്നതാണ് ഞങ്ങളുടെ ലക്ഷ്യം. പരമ്പരാഗത മെഷീൻ പഠനവും ആഴത്തിലുള്ള പഠനം അടിസ്ഥാനമാക്കിയുള്ള സൂപ്പര്വൈസ് ചെയ്തതോ അല്ലാത്തതോ ആയ സാങ്കേതികതകളും ഉപയോഗിച്ച് ഇത്തരം ടാസ്ക് ഫോർമുലേഷനുകളാൽ പ്രചോദിതമായ അന്തരശാസ്ത്രം അടിസ്ഥാനമാക്കിയുള്ള ആശയം വേർതിരിച്ചെടുക്കുന്നതിനുള്ള സമീപനങ്ങൾ ഞങ്ങൾ അവതരിപ്പിക്കുന്നു.
ഗവേഷണ സമീപനങ്ങൾ:
BERT (ട്രാൻസ്ഫോർമറുകളിൽ നിന്നുള്ള ദ്വിദിശ എൻകോഡർ പ്രാതിനിധ്യം), LSTM (ലോംഗ് ഷോർട്ട് ടേം മെമ്മറി) എന്നീ രണ്ട് വർഗ്ഗീകരണ ഫോർമുലേഷനുകളിൽ CNN-കൾ (കൺവല്യൂഷണൽ ന്യൂറൽ നെറ്റ്വർക്ക്) പോലെയുള്ള ADPE ഡാറ്റാസെറ്റിലെ പ്രകടനം മെച്ചപ്പെടുത്താൻ ആഴത്തിലുള്ള അത്യാധുനിക പഠന വിദ്യകൾ ഞങ്ങളുടെ പരീക്ഷണങ്ങൾ പ്രയോജനപ്പെടുത്തുന്നു. . ഒന്നാമത്തേത്, പേര് നൽകിയ എൻ്റിറ്റി തിരിച്ചറിയലുള്ള സീക്വൻസ് ടാഗിംഗ് ആണ്, രണ്ടാമത്തേത് സ്റ്റാറ്റിസ്റ്റിക്കൽ, സെമാൻ്റിക്, നാച്ചുറൽ ലാംഗ്വേജ് പ്രോസസ്സിംഗ്, ടെക്സ്റ്റ് സവിശേഷതകൾ എന്നിവ ഉപയോഗിച്ച് വിദ്യാര്ത്ഥിയുടെ n-ഗ്രാം സൃഷ്ടിക്കുന്നതിനുള്ള n-ഗ്രാം വർഗ്ഗീകരണവും ഡീപ് ന്യൂറൽ നെറ്റ്വർക്ക് ഉപയോഗിച്ചുള്ള അവയുടെ തരംതിരിക്കലുമാണ്.
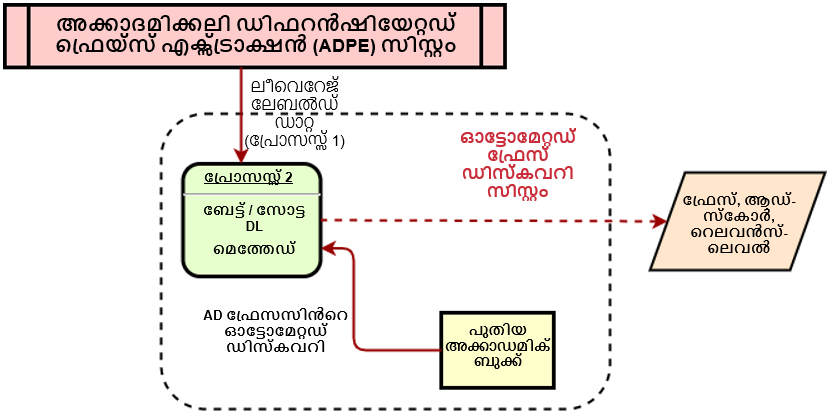
ശാസ്ത്രീയ ജേണലുകളില് നിന്നും പുസ്തക അധ്യായങ്ങളില് നിന്നും വർദ്ധിപ്പിച്ചെടുത്ത പദാവലിയും മികച്ച രീതിയില് ട്യൂൺ ചെയ്തിരിക്കുന്ന BERT അൺകേസ്ഡ് മോഡലും ഞങ്ങൾ പ്രയോജനപ്പെടുത്തുന്നു. കൂടാതെ, ഇൻപുട്ട് ടെക്സ്റ്റിൽ നിന്ന് ആശയങ്ങൾ കണ്ടെത്തുന്നതിന് എല്ലാ എൻകോഡർ ലെയറുകളുടെ പ്രാതിനിധ്യങ്ങളും ഒരു കൺസ്ട്രെയിൻഡ്-ട്രാൻസിഷൻ (BIO എൻകോഡിംഗ്) CRF (കണ്ടീഷണൽ റാൻഡം ഫീൽഡ്) സീക്വൻഷ്യൽ ടാഗറിലേക്ക് നൽകുന്നു.
എന്തുകൊണ്ട് CRF (കണ്ടീഷണൽ റാൻഡം ഫീൽഡ്):
- CRF ശ്രേണിയുടെ ലോഗ് സാധ്യത വർദ്ധിപ്പിക്കുകയും ശ്രേണീ ടാഗുകളുടെ പരമാവധി സാധ്യതയുള്ള എസ്റ്റിമേറ്റ് നിർമ്മിക്കുകയും ചെയ്യുന്നു.
- CRF നിയന്ത്രണങ്ങൾ, ലേബൽ എൻകോഡിംഗ് വഴി നിർദ്ദേശിച്ച പ്രകാരം സാധുവായ മൾട്ടിഗ്രാം ശ്രേണീ ലേബലുകൾ മാത്രമേ ജനറേറ്റ് ചെയ്യുന്നുള്ളൂ എന്ന് ഉറപ്പാക്കുന്നു – (ഉദാ: BIO എൻകോഡിംഗ് ഒരു ശ്രേണിയിലെ എൻ്റിറ്റി സെഗ്മെൻ്റെഷൻ ഉറപ്പ് നൽകുന്നു, എന്നാൽ അവ പാലിക്കേണ്ട ചില വ്യാകരണ നിയമങ്ങളുണ്ട്)
- ഒരു സാധാരണ രേഖീയ പാളിയേക്കാൾ നെറ്റ്വർക്കിൻ്റെ (ഫ്രോസൺ ചെയ്യാതെ വിട്ടാൽ) ഔട്ട്പുട്ട് ലോഗിറ്റുകൾ മികച്ച രീതിയിൽ ഉത്തമീകരിക്കുന്ന നഷ്ടമായി CRF സീക്വൻഷ്യൽ ലോഗ് സാധ്യത ഉപയോഗിക്കുന്നു, ഇത് ഒരു സാധാരണ രേഖീയ പാളിയുടെ ഔട്ട്പുട്ട് CRF നന്നായി ട്യൂൺ ചെയ്ത രേഖീയ പാളിയുമായി താരതമ്യം ചെയ്യുന്നതിലൂടെ സ്ഥിരീകരിക്കാം.
സംഗ്രഹം:
Embibe ൻ്റെ എല്ലാ ഉൽപ്പന്നങ്ങളുടെയും നട്ടെല്ലാണ് നോളജ് ഗ്രാഫ്. അതുകൊണ്ടു തന്നെ നോളജ് ഗ്രാഫ് പൂർത്തീകരണം ഞങ്ങളുടെ പ്രാഥമിക കടമയാണ്. നോളജ് ഗ്രാഫ് നിലനിർത്താനും വളരെ കുറഞ്ഞ മാനുവൽ ഇടപെടലുകളോടെ അത് അതിവേഗം വിപുലീകരിക്കാനും ഈ പ്രവര്ത്തനം ഞങ്ങളെ സഹായിച്ചു.
ഈ എക്സർസൈസ് മാതൃകയിൽ BERT ഉപയോഗിച്ച് പരിശീലിപ്പിക്കുകയും ഡാറ്റ പ്രോസസ്സിംഗ്, മോഡലിംഗ്, മൂല്യനിർണ്ണയം എന്നിവയ്ക്കായി മറ്റ് സാങ്കേതിക വിദ്യകൾ ഉപയോഗിക്കുകയും ചെയ്യുന്നു. റോ അക്കാദമിക പുസ്തകത്തിലെ പ്രധാന പഠന സംബന്ധമായ വാക്കുകൾക്ക് അടിവരയിടുന്നതിന് അക്കാദമികമായി വ്യത്യസ്തമായ പദസമുച്ചയ എക്സ്ട്രാക്റ്റർ ഉപയോഗിക്കുന്നു. അതിനാൽ, വ്യത്യസ്ത ഉറവിടങ്ങളിൽ നിന്ന് നൽകിയിരിക്കുന്ന പുസ്തക ഡാറ്റയിൽ നിന്ന് ആശയം കണ്ടെത്തുന്ന പ്രക്രിയ ഞങ്ങൾ ഓട്ടോമേറ്റ് ചെയ്തു.
References:
[1] Devlin Jacob, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805 (2018).
[2] Zhiheng Huang, Wei Xu, Kai Yu. Bidirectional LSTM-CRF Models for Sequence Tagging. arXiv preprint arXiv:1508.01991 (2015)
[3] William Cavnar and John Trenkle. N-Gram-Based Text Categorization. In Proceedings of SDAIR-94, 3rd Annual Symposium on Document Analysis and Information Retrieval (Las Vegas, US, 1994), pp. 161–175.
[4] Gaur, Manas, Keyur Faldu, and Amit Sheth. “Semantics of the Black-Box: Can knowledge graphs help make deep learning systems more interpretable and explainable?.” IEEE Internet Computing 25, no. 1 (2021): 51-59.




















