
ഡാറ്റ എന്നത് Embibe ന് ഒരു ഹരമാണ് – ഉപകരണങ്ങൾ തയ്യാറാക്കൽ, അളക്കൽ, ശേഖരിക്കൽ, ഖനനം, ആർക്കൈവ് ചെയ്യൽ. Embibe ന് അതിന്റെ ഡാറ്റയുണ്ട്, ഞങ്ങളുടെ IP അതിനെ ആശ്രയിച്ചിരിക്കുന്നു. Embibe-ൽ, ഞങ്ങളുടെ യൂസറുകൾ ഞങ്ങളുടെ ഉൽപ്പന്നങ്ങളുമായി എങ്ങനെ ഇടപഴകുന്നു എന്നതും നിർദ്ദിഷ്ട ഫലങ്ങളിലേക്ക് നയിക്കുന്ന ഘടകങ്ങൾ എന്തൊക്കെയാണെന്നും അളക്കാൻ മതിയായ ഇൻസ്ട്രുമെന്റേഷൻ ലഭ്യമാകുന്നതുവരെ ഞങ്ങൾ റിലീസുകൾ വൈകിപ്പിക്കുന്നു. ഡാറ്റയോടുള്ള ഈ അഭിനിവേശമാണ് വിദ്യാർത്ഥികൾ എങ്ങനെ പഠിക്കുന്നു, അവരുടെ ലക്ഷ്യങ്ങൾ കൈവരിക്കുന്നു എന്നതിനെക്കുറിച്ചുള്ള ഉൾക്കാഴ്ചയുള്ള നിരവധി വെളിപ്പെടുത്തലുകളിലേക്ക് ഞങ്ങളെ നയിച്ചത്. ഉദാഹരണത്തിന്, ഒരു വിദ്യാർത്ഥിയുടെ സ്കോർ ചെയ്യാനുള്ള കഴിവ് രണ്ട് ഘടകങ്ങളുടെ സംയോജനമാണ് – സ്കോർ ചെയ്യാനുള്ള മൊത്തത്തിലുള്ള സാധ്യതയുടെ ~61% സംഭാവന ചെയ്യുന്ന അവരുടെ പഠനശേഷിയും ~39% സംഭാവന ചെയ്യുന്ന പെരുമാറ്റ ഗുണങ്ങളും. ഡാറ്റാധിഷ്ഠിതമായി പ്രവർത്തിക്കുന്നതിലുള്ള ഈ റേസർ-ഷാർപ്പ് ഫോക്കസാണ് വിദ്യാഭ്യാസം വ്യക്തിഗതമാക്കുന്ന ഉൽപ്പന്നങ്ങൾ നിർമ്മിക്കാനും വിദ്യാർത്ഥികൾക്ക് പഠന ഫലങ്ങളിൽ മികച്ച മെച്ചപ്പെടുത്തലുകൾ നൽകാനും Embibe നെ പ്രാപ്തമാക്കിയത്.
പ്രാഥമിക വിവര ശേഖരണം
Embibe ന്റെ പ്ലാറ്റ്ഫോമിൽ ഉടനീളം വിവിധ ഘട്ടങ്ങളിലും ലൊക്കേഷനുകളിലും ഡാറ്റ ഇൻസ്ട്രുമെന്റ് ചെയ്യുകയും ശേഖരിക്കുകയും ചെയ്യുന്നു. കൃത്യസമയത്ത്, ശരിയായ സന്ദർഭത്തിൽ, ശരിയായ തലത്തിലുള്ള ഗ്രാനുലാരിറ്റി ഉപയോഗിച്ച്, ശരിയായ തരം ഡാറ്റ ക്യാപ്ചർ ചെയ്യുന്നതുപോലെ, ഡാറ്റ ക്യാപ്ചർ ചെയ്യേണ്ടതിന്റെ ആവശ്യമില്ല. Embibe ലെ ഡാറ്റ ക്യാപ്ചർ വിശാലമായി താഴെ പറയുന്ന വിഭാഗങ്ങളായി തിരിച്ചിരിക്കുന്നു:
- സമ്പന്നമായ ഇവന്റ് തരങ്ങളുടെ ഉപകരണം:
- യൂസർ ഇടപെടൽ വ്യക്തമായ ഇവന്റുകൾ – ക്ലിക്കുകൾ, ടാപ്പുകൾ, ഹോവറുകൾ, സ്ക്രോളുകൾ, ടെക്സ്റ്റ്-അപ്ഡേറ്റുകൾ
- യൂസർ ഇടപെടൽ അവ്യക്തമായ ഇവന്റുകൾ – കഴ്സർ സ്ഥാനം, ടാപ്പ് മർദ്ദം, ഉപകരണ ഓറിയന്റേഷൻ, സ്ഥാനം
- സിസ്റ്റം ജനറേറ്റഡ് സെർവർ സൈഡ് ഇവന്റുകൾ – പേജ് ലോഡ്, സെഷൻ പുതുക്കൽ, എപിഐ കോളുകൾ
- സിസ്റ്റം ജനറേറ്റഡ് ക്ലയന്റ് സൈഡ് ഇവന്റുകൾ – സിസ്റ്റം പുഷ് അറിയിപ്പുകളും ട്രിഗറുകളും
- പ്രോപ്പർട്ടി പ്രകാരമുള്ള നിർദ്ദിഷ്ട ഡാറ്റ:
- പേജ് കാഴ്ചകൾ (URL, റഫറർ, യൂസർ ഏജന്റ്, ഉപകരണം, IP, ടൈംസ്റ്റാമ്പ്, ട്രാഫിക് ഉറവിടം, പ്രചാരണം)
- ശ്രമ തലത്തിലുള്ള ഡാറ്റ പരിശീലിക്കുക (ടൈംസ്റ്റാമ്പ്, സന്ദർശനം/വീണ്ടും സന്ദർശിക്കുക, ഉത്തരം തിരഞ്ഞെടുക്കൽ, ആദ്യം കണ്ട സമയം, ശരിയായത്, ചെലവഴിച്ച സമയം, പരിഹാരം കണ്ടത്, ഉപയോഗിച്ച സൂചന) – സെഷൻ തലത്തിൽ സമാഹരിച്ചത്
- പെരുമാറ്റ ഡാറ്റ പഠിക്കുക:
- ഇവന്റ് ഡാറ്റ തിരയുക (ടൈംസ്റ്റാമ്പ്, അന്വേഷണം, ഫല സെറ്റ്)
- ഫല സംവേദന ഡാറ്റ (ടൈംസ്റ്റാമ്പ്, നിർദ്ദേശിച്ച ഫലം തിരഞ്ഞെടുത്തു, ഫല വിജറ്റും സന്ദർഭവും, വിജറ്റ് സ്ഥാനവും)
- ടെസ്റ്റ് ശ്രമ ഇവന്റ് ലെവൽ ഡാറ്റ (ടൈംസ്റ്റാമ്പ്, സന്ദർശനം/വീണ്ടും സന്ദർശിക്കുക, ഉത്തരം തിരഞ്ഞെടുക്കൽ, ആദ്യം കണ്ട സമയം, ശരി, ചെലവഴിച്ച സമയം, ഫീഡ്ബാക്ക് കണ്ടത്) – സെഷൻ തലത്തിൽ സമാഹരിച്ചത്
- (അക്കാദമിക് ഫോറം) ചോദ്യോത്തര വിശദാംശങ്ങൾ, ടൈംസ്റ്റാമ്പുകൾ, യൂസർ വോട്ടിംഗ് പെരുമാറ്റം എന്നിവ ചോദിക്കുക
- പേയ്മെന്റുകൾ (യൂസർ ഐഡന്റിഫയർ, യൂസർ ഇമെയിൽ, മൂന്നാം കക്ഷി പേയ്മെന്റ് ഗേറ്റ്വേ, പേയ്മെന്റ് ഗേറ്റ്വേ ഇടപാട് ഐഡന്റിഫയർ, പേയ്മെന്റ് മോഡ് (കാർഡ്, വാലറ്റ്, മുതലായവ), ഓർഡർ അഭ്യർത്ഥനയുടെ ടൈംസ്റ്റാമ്പ്, പേയ്മെന്റ് റിയലൈസേഷന്റെ ടൈംസ്റ്റാമ്പ്, പ്രയോഗിച്ച ഏതെങ്കിലും കിഴിവുകൾ, ഓർഡർ ഇനത്തിന്റെ പ്രത്യേകതകൾ)
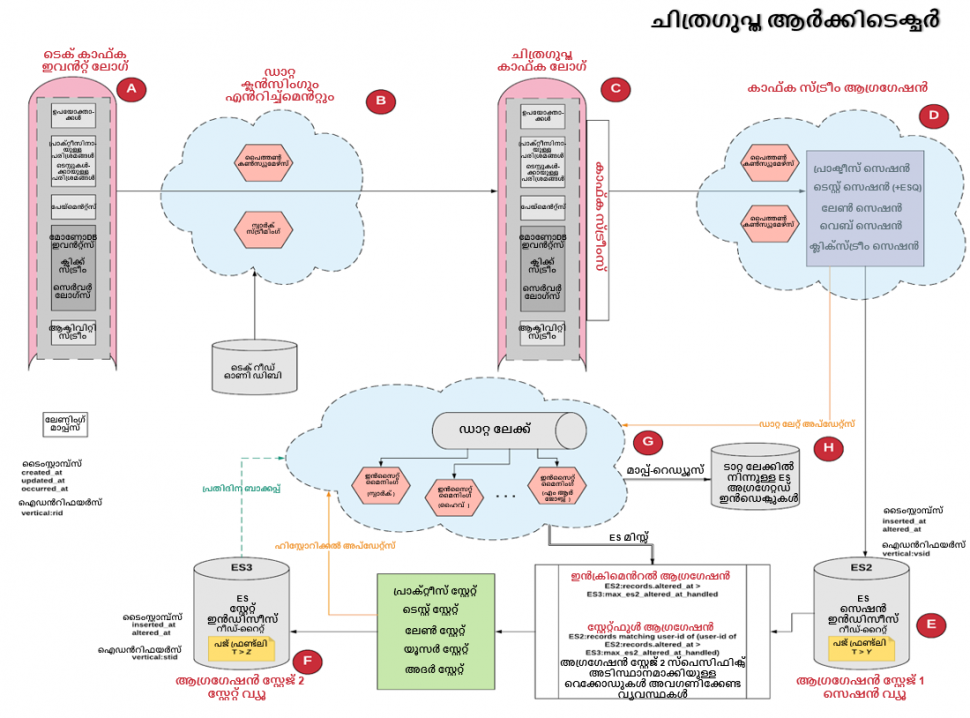
Embibe ചെയ്യുന്ന സ്കെയിലിൽ ഡാറ്റ ശേഖരണം നടത്തുമ്പോൾ കണക്കിലെടുക്കേണ്ട നിരവധി പ്രായോഗിക പരിഗണനകളുണ്ട്. ഉദാഹരണത്തിന്, ഈ ഡാറ്റയെല്ലാം ശേഖരിക്കുന്നതിന് ഞങ്ങൾ നിരവധി രീതികളെ ആശ്രയിക്കുന്നു. segment.io, Heap എന്നിവ പോലുള്ള മൂന്നാം കക്ഷി പ്ലഗിന്നുകളുമായി സംയോജിപ്പിച്ച് യൂസർ ഇടപെടൽ ഇവന്റ് സ്ട്രീം ലോഗിൻ ചെയ്യാനാകും. സെർവർ സൈഡ് പേജ് ലോഡും സെഷൻ ഇവന്റ് ലോഗിംഗും ഇൻ-ഹൗസ് ഇൻസ്ട്രുമെന്റ് ചെയ്ത് noSql ഡാറ്റാബേസുകളിലേക്ക് തള്ളുന്നു. പ്രാക്ടീസും ടെസ്റ്റും പോലുള്ള പ്രോപ്പർട്ടികളിലെ യൂസർ പ്രവർത്തനത്തിന്റെ പ്രതിദിന ഡാറ്റ, ഫ്രണ്ട് എൻഡ് വഴിയുള്ള അന്വേഷണ അഗ്രഗേഷനുകൾക്കായി DB യിൽ സംഭരിക്കുന്നു.
ഡാറ്റ പ്രോസസ്സിംഗ്
പ്രാഥമിക ഡാറ്റാ ശേഖരണം നടന്നാൽ, അത് വൃത്തിയാക്കാനും സമ്പുഷ്ടമാക്കാനും ഖനനം ചെയ്യാനും ദൃശ്യവൽക്കരിക്കാനും ആവശ്യമാണ്. Embibe ൽ, ഞങ്ങൾ ശേഖരിക്കുന്ന ഡാറ്റ ഉപയോഗിക്കുന്നതിന് ഇനി പറയുന്ന വിശാലമായ സമീപനങ്ങളുണ്ട്:
- ഇൻ-ഹൗസ് റിപ്പോർട്ടിംഗും അഡ്-ഹോക്ക് വിശകലനവും:
- സ്പാർക്ക് സ്ട്രീമിംഗും ഹഡൂപ്പ് മാപ്പും ഉപയോഗിച്ച് ലോഗ് മൈനിംഗ്, സെഷൻ ലെവൽ ആക്റ്റിവിറ്റി സംഭരിക്കുന്ന ഞങ്ങളുടെ യൂസർ GOV ഡാറ്റയും ഓരോ ഉള്ളടക്കത്തിനും എതിരായി ഓരോ യൂസറിനും അക്കാദമിക് എബിലിറ്റി പ്രൊഫൈലുകൾ സംഭരിക്കുന്ന GAV ഡാറ്റയും സൃഷ്ടിക്കുന്നതിനും അപ്ഡേറ്റ് ചെയ്യുന്നതിനും AWS EMR-ൽ ജോലികൾ കുറയ്ക്കുക. GOV, GAV ഡാറ്റ സ്കെയിലിൽ സേവിക്കുന്നതിനായി ഇലാസ്റ്റിക് തിരയൽ ക്ലസ്റ്ററുകളിൽ സംഭരിച്ചിരിക്കുന്നു.
- ട്രാഫിക് പാറ്റേണുകൾ, യൂസർ ധനസമ്പാദനം, ടെസ്റ്റ്-ഓൺ-ടെസ്റ്റ് മെച്ചപ്പെടുത്തൽ, തിരയൽ പരാജയങ്ങൾ, മറ്റ് ആവശ്യങ്ങൾ എന്നിവയ്ക്കായി റിപ്പോർട്ടിംഗ് ഡാറ്റ സൃഷ്ടിക്കാൻ ലോഗ് മൈനിംഗ്. പ്രോസസ്സ് ചെയ്ത ഡാറ്റ വീണ്ടും ഇലാസ്റ്റിക് സെർച്ചിലേക്ക് തള്ളുകയും കിബാന, ഗ്രാഫാന ഡാഷ്ബോർഡുകൾ ഉപയോഗിച്ച് ദൃശ്യവൽക്കരിക്കുകയും ചെയ്യുന്നു.
- ഒരു അഡ്-ഹോക്ക് അടിസ്ഥാനത്തിൽ നടത്തുന്നതിന് ആവശ്യമായ ഏതെങ്കിലും വിശകലനത്തിനായി പ്രാഥമിക അസംസ്കൃത ഡാറ്റ HDFS-ൽ HBase-ൽ സംഭരിക്കുന്നു.
- ബിസിനസ്/ഉൽപ്പന്നം/മാർക്കറ്റിംഗ് സെൽഫ്-സെർവ് എന്നിവയ്ക്കുള്ള മൂന്നാം കക്ഷി ഉപകരണങ്ങൾ
- ഞങ്ങളുടെ ഓൺ-പേജ്, ഇൻ-ആപ്പ് യൂസർ ആശയവിനിമയ ഡാറ്റ segment.io (മൂന്നാം കക്ഷി പ്ലഗിൻ) ഉപയോഗിച്ച് ക്യാപ്ചർ ചെയ്യുന്നു, അത് ഡാറ്റയെ വിവിധ ബാഹ്യ ഡാറ്റ വിഷ്വലൈസേഷൻ പ്ലാറ്റ്ഫോമുകളിലേക്ക് സ്വയമേവ റൂട്ട് ചെയ്യുന്നു
- ട്രാഫിക് ഉറവിടങ്ങൾ, ഡെമോഗ്രാഫിക്, ലൊക്കേഷൻ വിവരങ്ങൾ, ഉപകരണത്തിന്റെ തകർച്ച, പേജ് കാഴ്ചകൾ, ചെലവഴിച്ച സമയം, നിലനിർത്തൽ അളവുകൾ എന്നിവയുൾപ്പെടെ വിശാലമായ ട്രാഫിക് നിരീക്ഷണത്തിനുള്ള Google Analytics.
- യൂസർ ഫ്ലോകളുടെ വിശകലനത്തിനും ഒപ്റ്റിമൈസേഷനുമുള്ള ഹീപ്പ് അനലിറ്റിക്സ്. Segment.io വഴിയുള്ള എല്ലാ യൂസർ ഇടപെടൽ ഇവന്റുകളും ഹീപ്പിലേക്ക് തള്ളാൻ FE വയർ ചെയ്തു. യൂസർ പരിവർത്തന ഫണലുകളുടെയും ഫ്ലോകളുടെയും സെൽഫ് സെർവ് ശൈലി ഡൈനാമിക് സജ്ജീകരണം ഹീപ്പ് അനുവദിക്കുന്നു.




















