

Saas ମାଧ୍ୟମରେ AIକୁ ଅନଲକ୍ କରିବା
ଡାଉଟ୍ ରିଜୋଲ୍ୟୁସନ୍
ପ୍ରେରଣା
ସାରା ଦେଶରେ ହଜାର ହଜାର ବିଦ୍ୟାର୍ଥୀ ଲର୍ଣ୍ଣିଂ ଆଉଟକମ୍ ଆଚିଭ୍ କରିବା ପାଇଁ ଅଧିକ ଲର୍ଣ୍ଣ କରିବା, କଠିନ ପ୍ରାକ୍ଟିସ୍ କରିବା ଏବଂ ନିଜକୁ ଟେଷ୍ଟ କରିବା ଲାଗି ପ୍ରତିଦିନ Embibe ବ୍ୟବହାର କରନ୍ତି । ଏହି ଯାତ୍ରାରେ, ସେମାନଙ୍କର ଅନେକ ପ୍ରଶ୍ନ କିମ୍ବା ଡାଉଟ୍ ଆସିବା ସ୍ୱାଭାବିକ । ତେଣୁ, ବିଦ୍ୟାର୍ଥୀମାନଙ୍କ ମଧ୍ୟରେ ପ୍ରଶ୍ନ ପ୍ରଚାରିବା ଗୁଣକୁ ସବୁବେଳେ ଉତ୍ସାହିତ କରିବା ଲାଗି ଆମେ ଡାଉଟ୍ ରିଜୋଲ୍ୟୁସନ୍ ପ୍ରଡକ୍ଟ ମଧ୍ୟ ରଖିଛୁ ।
ନାମରୁ ଜଣାପଡେ ଯେ, ଏହା ହେଉଛି ଏକ ପ୍ଲାଟଫର୍ମ ଯାହା ବିଦ୍ୟାର୍ଥୀଙ୍କ ଡାଉଟ୍ ସମାଧାନ କରିବାରେ ସାହାଯ୍ୟ କରେ । ଏହି ସହାୟତା ସମ୍ବନ୍ଧିତ ବିଷୟର ବିଶେଷଜ୍ଞଙ୍କ ଦ୍ୱାରା ଦିଆଯାଇପାରେ, କିନ୍ତୁ ଏକ ସମୟରେ ଆସୁଥିବା ଅନେକ ସମସ୍ୟା ଓ ପ୍ରଶ୍ନକୁ ନେଇ ଡାଉଟ୍ କୁ ଗୋଟିଗୋଟି କରି ସମାଧାନ କରିବା ବିଶେଷଜ୍ଞମାନଙ୍କ ପାଇଁ କଷ୍ଟକର ବ୍ୟାପାର ହୋଇପାରେ । ପୁଣି ଏଥିପାଇଁ ଅଧିକ ସମୟ ଅପେକ୍ଷା କରିବାକୁ ପଡିପାରେ ଏବଂ ଏହାକୁ ନେଇ ୟୁଜରଙ୍କ ଅନୁଭୂତି ଏତେ ଭଲ ନ ଥାଏ ।
ସୁଯୋଗର ବ୍ୟବହାର କରିବା
ଏକାଡେମିକ୍ ବିଷୟବସ୍ତୁର ଅଧିକାଂଶ ଅଂଶ ହେଉଛି ଚିତ୍ର, ସମୀକରଣ ଓ ପ୍ରତୀକଗୁଡ଼ିକରେ ନିହିତ ଥିବା ସୂଚନା । ଚିତ୍ର ଓ ପାଠ୍ୟରୁ ଅର୍ଥଗତ ସୂଚନା ବାହାର କରିବା ଏବେ ଏକ ଡୋମେନ୍-ନିର୍ଭରଶୀଳ ଏବଂ କଠିନ କାର୍ଯ୍ୟ, ଯାହା ବୃହତ ଡାଟାସେଟ୍, ନିର୍ଦ୍ଦିଷ୍ଟ ଡୋମେନ୍ ଜ୍ଞାନ ଏବଂ ପ୍ରାକୃତିକ ଭାଷା ଓ ଦୃଷ୍ଟିଭଙ୍ଗୀ ପାଇଁ ଗଭୀର ଶିକ୍ଷଣ ଆଭିମୁଖ୍ୟ ଆଦିର ଉପଲବ୍ଧତା ଆବଶ୍ୟକ କରେ ।
ଅଧିକାଂଶ ଡାଉଟ୍-ରିଜୋଲ୍ୟୁସନ୍ ପ୍ରଡକ୍ଟଗୁଡିକ ଉପଲବ୍ଧ ପ୍ରଶ୍ନାବଳୀ ସଂଗ୍ରହ ବ୍ୟବହାର କରି ସମତୁଲ୍ୟ ପ୍ରଶ୍ନ ଯୋଗାଇଦେଇଥାନ୍ତି । କିମ୍ବା ପ୍ରଶ୍ନର ପ୍ରସଙ୍ଗକୁ ଆଧାର କରି ଉତ୍ତର ଦେବାକୁ ସକ୍ଷମ ହେବା ପାଇଁ ଏକ ପ୍ରଣାଳୀ ଗଠନ କରିଥାନ୍ତି । Embibeରେ ଆମର ପ୍ରଶ୍ନ ବ୍ୟାଙ୍କରେ ଲକ୍ଷ ଲକ୍ଷ ପ୍ରଶ୍ନ ଅଛି । ପ୍ରଶ୍ନରେ ଉପସ୍ଥିତ ପ୍ରଶ୍ନ ବିଷୟବସ୍ତୁ, ଏବଂ ଅଙ୍କନ କିମ୍ବା ଚିତ୍ରରୁ ପ୍ରାସଙ୍ଗିକ ସୂଚନା ପାଇବା ପାଇଁ ଆମେ ଆମର ଏକାଡେମିକ୍ ସଂଗ୍ରହାବଳୀକୁ ଅଦ୍ୟତନ ଓ ବିକଶିତ କରିବା ପାଇଁ ଅତ୍ୟାଧୁନିକ ମଡେଲ୍ ବ୍ୟବହାର କରୁଛୁ ।
ଡାଉଟ୍ ରିଜୋଲ୍ୟୁସନ୍ ପ୍ରଡକ୍ଟ ଦ୍ଵାରା କୌଣସି ମାନବ ପଦକ୍ଷେପ ସାହାଯ୍ୟ ବିନା 93% ପ୍ରଶ୍ନର ଉତ୍ତର ଆପେ ଆପେ ଦିଆଯାଇପାରେ ।
ଡାଉଟ୍ ରିଜୋଲ୍ୟୁସନ୍ ସିଷ୍ଟମ୍ ଗଠନ
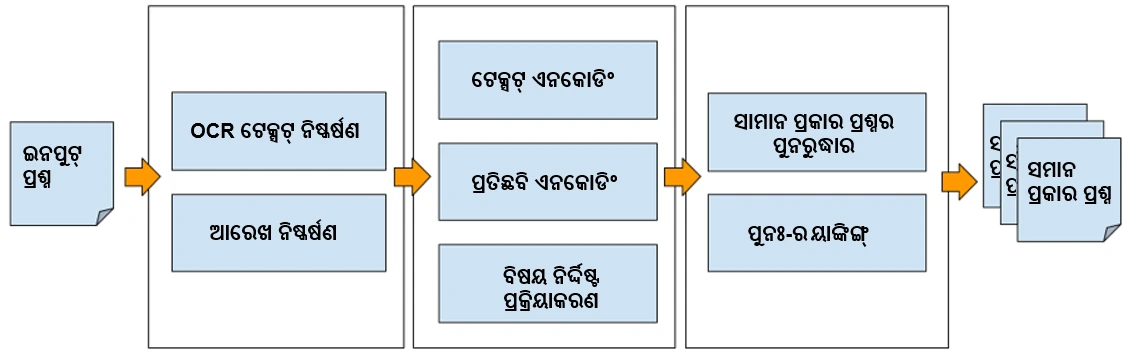
ଡାଇଗ୍ରାମ୍ ଏକ୍ସଟ୍ରାକ୍ସନ୍:

ତୁରନ୍ତ ଡାଉଟ୍ ର ସମାଧାନ କରିବାକୁ ହେଲେ ଏହା ଗୁରୁତ୍ୱପୂର୍ଣ୍ଣ ଯେ ପ୍ରଶ୍ନରେ ପ୍ରଦତ୍ତ ସମସ୍ତ ବିବରଣୀକୁ ଆମକୁ ବୁଝିବାକୁ ହେବ । ଏହା ସହ ଆମେ ଡାଇଗ୍ରାମ୍ ଏକ୍ସଟ୍ରାକ୍ସନ୍ ଲେୟାର୍ ମଧ୍ୟ ଉପଯୋଗ କରିଥାଉ । ଏହା ଦ୍ୱାରା ସୁନିଶ୍ଚିତ କରାଯାଏ ଯେ ଏକ୍ସଟ୍ରାକ୍ଟେଡ୍ ଚିତ୍ରଗୁଡ଼ିକ ଅର୍ଥଗତ ସମାନତାକୁ ମଧ୍ୟ ହିସାବ କରିଥାଏ । OCR ମଡ୍ୟୁଲରେ ଇନପୁଟ୍ ରେ ଡାଇଗ୍ରାମ ଥିଲେ, ଏହାକୁ ଭ୍ରମରେ ପକାଇପାରେ, ତେଣୁ ଆମେ ଡାଇଗ୍ରାମ୍ ବାଉଣ୍ଡିଂ ବକ୍ସକୁ ଅପସାରଣ କରିବା ପାଇଁ ଚିତ୍ରକୁ ପ୍ରକ୍ରିୟାକରଣ କରୁ, ଯାହା ଏହାକୁ OCR ପ୍ରକ୍ରିୟାକରଣ ପାଇଁ ସରଳ କରିଥାଏ । ଏକାଡେମିକ୍-ଡୋମେନ୍ ପାଇଁ ଆମେ ଫିଗର୍ ଏକ୍ସଟ୍ରାକ୍ସନ୍ ମଡେଲ୍ ପ୍ରସ୍ତୁତ କରିଛୁ । ଯାହା YOLOv5 ପରି ଜଟିଳ ମଡେଲଗୁଡିକରେ ମଧ୍ୟ ସଠିକତା ସହ ଫଳାଫଳ ଦେଇଥାଏ ।
ଅପ୍ଟିକାଲ୍ କ୍ୟାରେକ୍ଟର୍ ରେକୋଗନିସନ୍ (OCR):
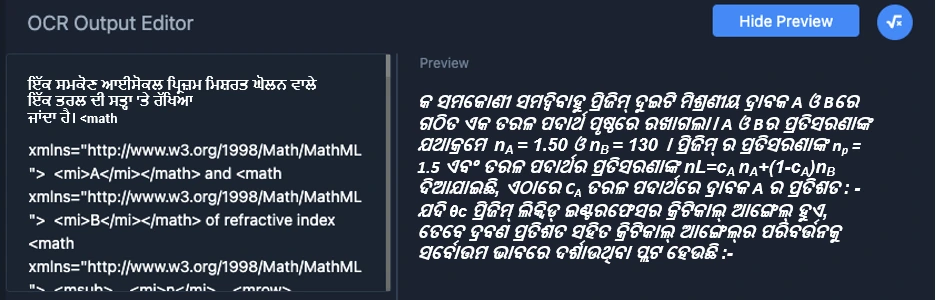
ଆମେ ଚିତ୍ରରେ ଥିବା ଫିଗରଗୁଡ଼ିକୁ ବାହାର କରିବା ପରେ, ପରବର୍ତ୍ତୀ ପର୍ଯ୍ୟାୟରେ ବ୍ୟବହୃତ ହେବାକୁ ଥିବା ଚିତ୍ର ଭିତରେ ଥିବା ପାଠ୍ୟକୁ ବାହାର କରିବା ଏବଂ ବିଶ୍ଳେଷଣ କରିବା ପାଇଁ ଆମେ OCR ସ୍ତର ବ୍ୟବହାର କରୁ । ସ୍କିଉ ସଂଶୋଧନ, ସ୍ୟାଡୋ ହଟାଇବା, ରିଜୋଲ୍ୟୁସନ୍ ବଢାଇବା, ଏବଂ ଅସ୍ପଷ୍ଟତା ଚିହ୍ନଟ କରିବା ପରି ପଦକ୍ଷେପଗୁଡିକ OCR କାର୍ଯ୍ୟଦକ୍ଷତାକୁ ଉନ୍ନତ କରିବା ପାଇଁ କରାଯାଇଥାଏ ।
ଚିତ୍ର ଏନକୋଡିଂ:
ଆମେ ଚିତ୍ରରେ ଥିବା ଅର୍ଥ ସମ୍ବନ୍ଧୀୟ ସୂଚନାକୁ ଧରି ରଖିବା ପାଇଁ ଡେନ୍ସ ଭେକ୍ଟରରେ ଫିଗରକୁ ଏନକୋଡ୍ କରିବା ପାଇଁ ResNet ଓ EfficientNet ପରି ଅତ୍ୟାଧୁନିକ କମ୍ପ୍ୟୁଟର ଭିଜନ୍ ମଡେଲଗୁଡିକର ବ୍ୟବହାର କରୁ, ଯାହା ଫଳରେ ଅର୍ଥଗତ ଭାବେ ସମାନ ଚିତ୍ର କିଛି ଭିନ୍ନ ଚିତ୍ରଠାରୁ ପରସ୍ପର ପାଖାପାଖି ହେବେ ।
ଟେକ୍ସଟ୍ ଏନକୋଡିଂ:
ପ୍ରଶ୍ନ ପାଠ୍ୟ, ଉତ୍ତର ଓ ସେଗୁଡିକର ବିସ୍ତୃତ ବ୍ୟାଖ୍ୟାକୁ ନେଇ ଆମ ଏକାଡେମିକ୍ କର୍ପୋରାରେ ମଡେଲକୁ ଦକ୍ଷ କରି ଟ୍ରିପଲେସ୍ କ୍ଷତି ଏବଂ ପାରସ୍ପରିକ ସର୍ବାଧିକ ସୂଚନା ପ୍ରଦାନ ପରି କୌଶଳଗୁଡିକ ବ୍ୟବହାର ଦ୍ୱାରା ଆମେ ଡେନ୍ସ ଭେକ୍ଟର ନିରୂପଣ ଶିଖିଥାଉ । ଆମେ BERT, ଏବଂ T5 ପରି ପୂର୍ବ-ପ୍ରଶିକ୍ଷିତ ଭାଷା ମଡେଲଗୁଡିକର ଲାଭ ଉଠାଇଥାଉ । ତା’ପରେ ଆମେ ଏହି ଏନକୋଡର୍ ମଡେଲକୁ OCR ବାହାର କରାଯାଇଥିବା ପାଠକୁ ଡେନସ୍ ଭେକ୍ଟରରେ ରୂପାନ୍ତର କରିବା ପାଇଁ ବ୍ୟବହାର କରିଥାଉ, ଯାହାକି ଅର୍ଥଗତ ସମାନ ପ୍ରଶ୍ନର ପୁନରୁଦ୍ଧାର ପାଇଁ ବ୍ୟବହୃତ ହୁଏ ।
ସମାନ ପ୍ରକାର ପ୍ରଶ୍ନକୁ ପୁଣି ପାଇବା:
ଆମ କୋଶ୍ଚିନ୍ ବ୍ୟାଙ୍କରେ ଥିବା ସମସ୍ତ ପ୍ରଶ୍ନକୁ ନେଇ ଆମେ ଏନକୋଡେଡ୍ ଚିତ୍ର ଏବଂ ପାଠ୍ୟ ତୁଳନା କରୁ ଏବଂ ଟପ୍-k ସମାନ ପ୍ରଶ୍ନର ପୁନରୁଦ୍ଧାର କରୁ । ଏକ ପ୍ରଶ୍ନରେ ଚିତ୍ରର ମହତ୍ତ୍ୱ ଆଧାରରେ ପାଠ୍ୟ ଓ ଚିତ୍ର ଉଭୟ ଥିଲେ ଆମେ ଏକ ଭରିତ ସମାନତା ନେବା ପାଇଁ ମଧ୍ୟ କୌଶଳ ଆପଣାଇଥାଉ । ଲକ୍ଷ ଲକ୍ଷ ରେକର୍ଡରେ ଡେନ୍ସ ଭେକ୍ଟରର କୋସାଇନ୍ ସମାନତା କରିବା କାର୍ଯ୍ୟରେ ଅଧିକ ଖର୍ଚ୍ଚ ହୋଇଥାଏ । ତେଣୁ, ସିଷ୍ଟମର ଭଲ ପ୍ରଦର୍ଶନ ପାଇଁ ଆମେ ସାର୍ଡିଙ୍ଗ୍, ବକେଟିଂ ଏବଂ କ୍ଲଷ୍ଟରିଙ୍ଗ୍ ପଦ୍ଧତିକୁ ବ୍ୟବହାର କରିଥାଉ ।
ବିଷୟ ନିର୍ଦ୍ଧିଷ୍ଟ ପୋଷ୍ଟ ପ୍ରୋସେସିଂ:
ଆମେ ବିଷୟ ନିର୍ଦ୍ଦିଷ୍ଟ ପୋଷ୍ଟ ପ୍ରୋସେସିଂ କୌଶଳ ବ୍ୟବହାର କରୁ, ଯେପରିକି ପାଠ୍ୟବସ୍ତୁରେ ଥିବା ରାସାୟନିକ ସମୀକରଣ ପରିଚାଳନା, ଗାଣିତିକ ପରିପ୍ରକାଶର ସମାଧାନ କରିବା । ପାଠ୍ୟବସ୍ତୁରେ ଥିବା ରାସାୟନିକ ସମୀକରଣ ଏବଂ ରାସାୟନିକ ତତ୍ତ୍ୱଗୁଡ଼ିକ ସମାନ ପ୍ରଶ୍ନଗୁଡିକର ପୁନରୁଦ୍ଧାର ପାଇଁ ଏକ ଗୁରୁତ୍ୱପୂର୍ଣ୍ଣ ଭୂମିକା ଗ୍ରହଣ କରିଥାଏ ।
ସନ୍ଦର୍ଭ:
[1] Raffel, Colin, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. “Exploring the limits of transfer learning with a unified text-to-text transformer.” arXiv preprint arXiv:1910.10683 (2019).
[2] Devlin, Jacob, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. “Bert: Pre-training of deep bidirectional transformers for language understanding.” arXiv preprint arXiv:1810.04805 (2018).
[3] Tan, Mingxing, and Quoc Le. “Efficientnet: Rethinking model scaling for convolutional neural networks.” In International Conference on Machine Learning, pp. 6105-6114. PMLR, 20
[4] Faldu, Keyur, Amit Sheth, Prashant Kikani, and Hemang Akabari. “KI-BERT: Infusing Knowledge Context for Better Language and Domain Understanding.” arXiv preprint arXiv:2104.08145 (2021).
[5] Gaur, Manas, Keyur Faldu, and Amit Sheth. “Semantics of the Black-Box: Can knowledge graphs help make deep learning systems more interpretable and explainable?.” IEEE Internet Computing 25, no. 1 (2021): 51-59.
[6] Gaur, Manas, Ankit Desai, Keyur Faldu, and Amit Sheth. “Explainable AI Using Knowledge Graphs.” In ACM CoDS-COMAD Conference. 2020.
[7] Sheth, Amit, Manas Gaur, Kaushik Roy, and Keyur Faldu. “Knowledge-intensive Language Understanding for Explainable AI.” IEEE Internet Computing 25, no. 5 (2021): 19-24.
[8] “#RAISE2020 – Embibe – AI-Powered learning outcomes platform for personalized education”, MyGov India, Oct 2020, https://www.youtube.com/watch?v=kuwFtHgN3qU
[9] Faldu, Keyur, Aditi Avasthi, and Achint Thomas. “Adaptive learning machine for score improvement and parts thereof.” U.S. Patent 10,854,099, issued December 1, 2020.
← AI ହୋମ୍କୁ ଫେରନ୍ତୁ


















