

Saas ମାଧ୍ୟମରେ AIକୁ ଅନଲକ୍ କରିବା
ନଲେଜ୍ ବଡି: ଆପଣଙ୍କର ପାଠପଢାର ସାଥୀ
Embibe ରେ, ଆମେ ବିଦ୍ୟାର୍ଥୀମାନଙ୍କ ଶିକ୍ଷଣ ଯାତ୍ରାକୁ ସଶକ୍ତ କରିବାକୁ ପ୍ରତିଶ୍ରୁତିବଦ୍ଧ । ନଲେଜ୍ ବଡି ହେଉଛି ଏକ ଆର୍ଟିଫିସିଆଲ୍ ଇଣ୍ଟେଲିଜେନ୍ସ ଚାଟ୍ ବଟ୍, ଯାହା ପ୍ରଶ୍ନର ଉତ୍ତର ଏବଂ ଡାଉଟ୍ ରିଜୋଲ୍ୟୁସନ୍ ବ୍ୟବହାର କରି ବିଦ୍ୟାର୍ଥୀମାନଙ୍କୁ ସେମାନଙ୍କର ଶିକ୍ଷଣକୁ ରିଭାଇଜ୍ କରିବାରେ ସାହାଯ୍ୟ କରେ ।
ସ୍ୱୟଂକ୍ରିୟ ପ୍ରଶ୍ନ ଗଠନ ଏବଂ ଉତ୍ତର ପାଇଁ ଗଭୀର ଶିକ୍ଷଣ ମଡେଲଗୁଡିକୁ ପରିପୂର୍ଣ୍ଣ କରିବା ଲାଗି ସ୍ପଷ୍ଟ ବିଷୟ ଜ୍ଞାନ ହେଉଛି ଅତ୍ୟନ୍ତ ଗୁରୁତ୍ୱପୁର୍ଣ୍ଣ । Embibe ର ନଲେଜ୍ ଗ୍ରାଫ୍ ହେଉଛି ବିଷୟବସ୍ତୁ ବୁଦ୍ଧିମତାର ମୁଖ୍ୟ ଆଧାର, ଏଥିରେ ଲକ୍ଷାଧିକ ସମ୍ପର୍କ ବ୍ୟବହାର କରି ହଜାର ହଜାର କନସେପ୍ଟ ଓ ଦକ୍ଷତା ପରସ୍ପର ସହିତ ସଂଯୁକ୍ତ ହୋଇଛନ୍ତି ।
ନଲେଜ୍ ବଡି ପାରସ୍ପରିକ ଆର୍ଟିଫିସିଆଲ୍ ଇଣ୍ଟେଲିଜେନ୍ସ, ଅତ୍ୟାଧୁନିକ ଭାଷା ଏବଂ ଦର୍ଶନ ମଡେଲ ବ୍ୟବହାର କରି ନିର୍ମିତ ହୋଇଛି । ବୌଦ୍ଧିକ ଆଲୋଚନା ପ୍ରସ୍ତୁତ କରିବାକୁ ଏହି ଗଭୀର ଶିକ୍ଷଣ ମଡେଲଗୁଡିକରେ ଏହା ଏକାଡେମିକ୍ ନଲେଜ୍ ଗ୍ରାଫ୍ ଗୁଡିକ ସାମିଲ କରିଛି ।
ନଲେଜ୍ ବଡି ନିମ୍ନଲିଖିତ କ୍ଷମତା ପ୍ରଦାନ କରିଥାଏ:
- ବିଦ୍ୟାର୍ଥୀଙ୍କ ଲର୍ଣ୍ଣିଂ ଆଉଟକମ୍କୁ ଆକଳନ କରିବାକୁ ବିଦ୍ୟାର୍ଥୀଙ୍କ ଶିକ୍ଷଣ ଇତିହାସକୁ ଆଧାର କରି ଆପେ ଆପେ ପ୍ରଶ୍ନ ସୃଷ୍ଟି କରେ ଓ ପଚାରିଥାଏ ।
- ବିଦ୍ୟାର୍ଥୀ ଶିକ୍ଷଣ ବିଷୟବସ୍ତୁ ସହ ବ୍ୟସ୍ତ ଥିବାବେଳେ ବିଦ୍ୟାର୍ଥୀଙ୍କ ପ୍ରଶ୍ନର ଉତ୍ତର ଦେଇଥାଏ ।
- ବ୍ୟବହାରକାରୀଙ୍କ ପସନ୍ଦର ଆଞ୍ଚଳିକ ଭାଷାରେ ପ୍ରଶ୍ନଗୁଡ଼ିକୁ ଆପେ ଆପେ ଅନୁବାଦ କରିଦିଏ ।
ଚିତ୍ର 1. ରେ ନଲେଜ୍ ବଡିର କ୍ଷମତା ସମ୍ପର୍କରେ ଉଦାହରଣ ଦିଆଯାଇଛି ।
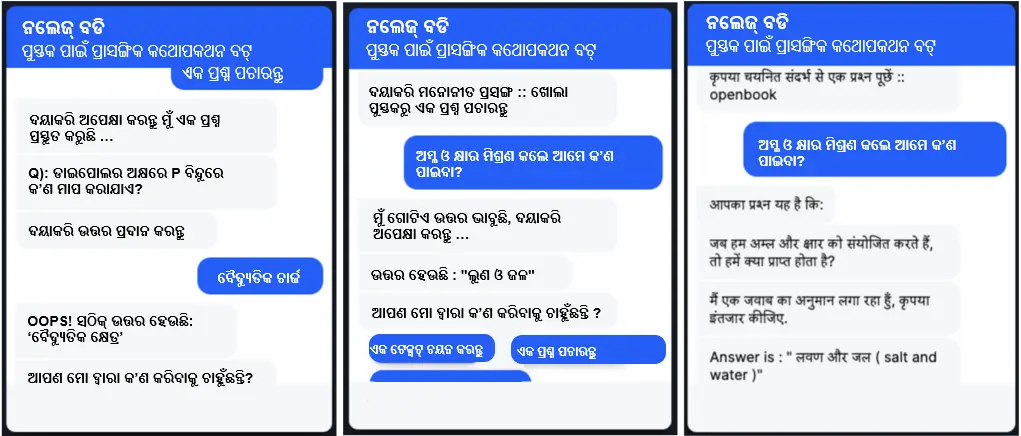
1.କ୍ୱେଶ୍ଚିନ୍ ଜେନେରେସନ୍ (QG)
ସ୍ୱୟଂଚାଳିତ ଭାବରେ ପ୍ରଶ୍ନ ସୃଷ୍ଟି କରିବାର କ୍ଷମତା ବିଦ୍ୟାର୍ଥୀମାନଙ୍କ ସହିତ ଜଡିତ ହେବାର ସୁଯୋଗ ଆଣିଥାଏ ଏବଂ ସେମାନଙ୍କର କନସେପ୍ଟ ମାଷ୍ଟରୀକୁ ଆକଳନ କରିପାରିବ । ଆମେ ଅତ୍ୟାଧୁନିକ T5, UniLM ଆଦି ପରି ଭାଷା ମଡେଲଗୁଡିକ ବିସ୍ତାର କରିଛୁ ଏବଂ ସେଗୁଡିକୁ ARC, DROP, QASC, SciQ, SciTail, SQUAD, HotpotQA, ଆଦି ସର୍ଚ୍ଚ ଡାଟାବେସ୍ ଓ Embibeର ନିଜସ୍ୱ ଡାଟାସେଟଗୁଡିକ ପାଇଁ ଦକ୍ଷ କରିଛୁ । ଆମେ ଏକାଧିକ ପ୍ରକାରର ପ୍ରଶ୍ନକୁ ବୁଲିୟାନ୍, ସ୍ପାନ୍-ଆଧାରିତ, ଶୂନ୍ୟ ସ୍ଥାନ ପୂରଣ କରିବା, ବହୁ ବିକଳ୍ପ ପ୍ରଶ୍ନ ଇତ୍ୟାଦିରେ କାମ କରିଥାଉ । ଆମେ KI-BERT ପରି ଆର୍କିଟେକଚର୍ ସହିତ ଏକାଡେମିକ୍ ନଲେଜ୍ ଗ୍ରାଫରୁ ଜ୍ଞାନର ଇନଫ୍ୟୁଜନ୍ ବ୍ୟବହାର କରୁ [3] । ଆମେ ମଧ୍ୟ ସୁନିଶ୍ଚିତ କରୁ ଯେ ମଡେଲଗୁଡିକ ନଲେଜ୍ ଗ୍ରାଫ୍ ସାହାଯ୍ୟରେ ଉତ୍ତମ ବ୍ୟାଖ୍ୟାଯୋଗ୍ୟ ହେବ [4][6][7] । ଆମର ମଡେଲଗୁଡିକ ଉପାଦାନର ଆଓ୍ୱେର୍ ଆଟେନସନ୍ ମେକାନିଜିମ୍ ର ସାହାଯ୍ୟରେ ମଲ୍ଟି-ହପ୍ ପ୍ରଶ୍ନ ମଧ୍ୟ ସୃଷ୍ଟି କରିଥାଏ । କ୍ୱେଶ୍ଚିନ୍ ଜେନେରେସନ୍ ମଡେଲ୍ ଶିକ୍ଷଣ ପ୍ରସଙ୍ଗକୁ ଇନପୁଟ୍ ଭାବରେ ଗ୍ରହଣ କରେ, ଇଚ୍ଛିତ ପ୍ରଶ୍ନ ପ୍ରକାର ପାଇଁ ପ୍ରମ୍ପ୍ଟ ଏବଂ ଅନ୍ୟାନ୍ୟ ପ୍ରଶ୍ନ ପ୍ରକାର ନିର୍ଦ୍ଦିଷ୍ଟ ମେଟାଡାଟାକୁ ଇନପୁଟ୍ ଭାବରେ ଗ୍ରହଣ କରେ । ପ୍ରଶ୍ନ ସୃଷ୍ଟି କରିବା ପାଇଁ ଆମେ ବିମ୍ ସର୍ଚ୍ଚ ଓ କ୍ଷୁଦ୍ର ନମୁନା ସଂଗ୍ରହ ପ୍ରଣାଳୀ ବ୍ୟବହାର କରିଥାଉ ।
2.କ୍ଵେଶ୍ଚିନ୍ ଆନସରିଂ (QA)
ବିଦ୍ୟାର୍ଥୀମାନଙ୍କ ଶିକ୍ଷଣ ଯାତ୍ରା ସକାରାତ୍ମକ ଭାବରେ ପ୍ରଭାବିତ ହୁଏ ଯେତେବେଳେ ସେମାନେ ଏଥିରେ ପ୍ରଶ୍ନର ଉତ୍ତର ଦେବା କ୍ଷମତା ସହ ଜଡିତ ହୁଅନ୍ତି । ସେମାନଙ୍କର ପ୍ରଶ୍ନର ଉତ୍ତର ଦିଆଗଲେ ଏବଂ ସେମାନେ ପ୍ରଶ୍ନ ପଚାରିଲେ ଶିକ୍ଷଣ କାର୍ଯ୍ୟକଳାପ ପ୍ରଭାବଶାଳୀ ହୋଇଥାଏ । ନଲେଜ୍ ବଡି ବିଦ୍ୟାର୍ଥୀମାନଙ୍କୁ ଯେକୌଣସି ପ୍ରଶ୍ନ ପଚାରିବାକୁ ସଶକ୍ତ କରିଥାଏ, ଯେଉଁଗୁଡିକୁ ପ୍ରଶ୍ନ ଉତ୍ତର ମଡେଲ୍ ବ୍ୟବହାର କରି ଉତ୍ତର ଦିଆଯାଇଥାଏ । ପ୍ରଶ୍ନର ଉତ୍ତର ମଡେଲଗୁଡିକ T5, UniLM ଇତ୍ୟାଦି ପରି ପ୍ରାକ୍-ଦକ୍ଷତା ସମ୍ପନ୍ନ ଭାଷା ମଡେଲଗୁଡିକ ବ୍ୟବହାର କରି ଦକ୍ଷତାଯୁକ୍ତ ହୁଏ ଏବଂ ସର୍ଚ୍ଚ ଡାଟାସେଟ୍ ଓ ପୂର୍ବରୁ ଉଲ୍ଲେଖ ହୋଇଥିବା Embibe ନିଜସ୍ୱ ଡାଟାସେଟଗୁଡିକରେ ରଖାଯାଇଥାଏ । ବ୍ୟବହାରକାରୀମାନେ ବିଭିନ୍ନ ପ୍ରସଙ୍ଗ ଅନୁଯାୟୀ ପ୍ରଶ୍ନ ପଚାରିପାରିବେ, ଯେପରିକି ମନୋନୀତ ପାଠ୍ୟବିଷୟ, ଗୋଟିଏ ଅଧ୍ୟାୟ, ଗୋଟିଏ ପୁସ୍ତକ, କିମ୍ବା ପାଠ୍ୟକ୍ରମ ବିଷୟରୁ ସେମାନେ ପ୍ରଶ୍ନ ପଚାରିପାରନ୍ତି । ଆମର ପ୍ରଶ୍ନ ଉତ୍ତର ପ୍ରଣାଳୀ, ଡେନସ୍ ଭେକ୍ଟର ଅର୍ଥଗତ ସମାନତା ବ୍ୟବହାର କରି ପ୍ରସଙ୍ଗ ଆଧାରିତ ବିଷୟ ଚୟନ କରେ ଏବଂ ଉତ୍ତରର ପୂର୍ବାନୁମାନ କରିବାକୁ ପ୍ରଶ୍ନ ଉତ୍ତର ମଡେଲକୁ ସୂଚିତ କରିଥାଏ । ଫିଡବ୍ୟାକ୍ ଲୁପ୍ କ୍ରମାଗତ ଭାବରେ ଆମର ମଡେଲକୁ ଉନ୍ନତ ହେବାକୁ ସାହାଯ୍ୟ କରିବ । ଆମର ପ୍ରଶ୍ନର ଉତ୍ତର ମଡେଲ ଏତେ ଉନ୍ନତ ଯେ ଏହା NEET ପ୍ରବେଶିକା ପରୀକ୍ଷାରେ ମଧ୍ୟ ସଫଳତା ଅର୍ଜନ କରିପାରୁଛି ।
3.ଆଞ୍ଚଳିକ ଭାଷାରେ ଅନୁବାଦ (VT)
ନଲେଜ୍ ବଡି ଏକାଧିକ ଭାଷାକୁ ସମର୍ଥନ କରେ ଏବଂ ୟୁଜରମାନଙ୍କ ପସନ୍ଦ ଆଧାରରେ ସଂପୂର୍ଣ୍ଣ କଥୋପକଥନ ଯେକୌଣସି ଆଞ୍ଚଳିକ ଭାଷାରେ ହୋଇପାରେ । ଏହା ଯେକୌଣସି ପୂର୍ବ-ପରିଭାଷିତ ଭାଷାରେ ସ୍ୱୟଂ-ପ୍ରସ୍ତୁତ ପ୍ରଶ୍ନ ପଚାରିପାରେ ଏବଂ ଏହା ସେହି ଭାଷାରେ ଉତ୍ତରଗୁଡିକର ମୂଲ୍ୟାୟନ ମଧ୍ୟ କରିପାରେ । ଆମର ନିଜସ୍ୱ ବିକଶିତ NMT ମଡେଲ୍ ବ୍ୟବହାର କରୁ ଯାହା ଜେନେରିକ୍ ଅନୁବାଦ ପାଇଁ ଅନ୍ୟ ବ୍ୟବସ୍ଥା ତୁଳନାରେ ଦକ୍ଷ । ବର୍ତ୍ତମାନ, ଆମେ ଚାଟ୍ ବଟ୍ରେ 11 ଟି ଭାରତୀୟ ଭାଷା ବ୍ୟବହାର କରୁଛୁ, ଯେଉଁଥିରେ ହିନ୍ଦୀ, ଗୁଜୁରାଟୀ, ମରାଠୀ, ତାମିଲ୍, ତେଲୁଗୁ, ବଙ୍ଗାଳୀ, କନ୍ନଡ, ଆସାମୀ, ଓଡ଼ିଆ, ପଞ୍ଜାବୀ ଏବଂ ମାଲାୟାଲମ୍ ଅନ୍ତର୍ଭୁକ୍ତ । ଏକାଡେମିକ୍ ଡୋମେନ୍ ନିର୍ଦ୍ଦିଷ୍ଟତା ହେତୁ ଆମର ସ୍ୱତନ୍ତ୍ର ଭାବରେ ବିକଶିତ ମଡେଲଗୁଡିକ ଗୁଗୁଲ୍ ଟ୍ରାନ୍ସଲେଟ୍ ପରି ତୃତୀୟ ପକ୍ଷ API ଗୁଡ଼ିକଠାରୁ ଭଲ ପ୍ରଦର୍ଶନ କରେ ।
ସାରଣୀ 1 ରେ ଆମେ କିଛି ଉଦାହରଣ ଦେଖିପାରିବା ଯେଉଁଠାରେ ଗୁଗୁଲ୍ ଅନୁବାଦ ଅପେକ୍ଷା ଆମର ଅନୁବାଦ ଭଲ:
| ଇଂରାଜୀ | ଗୁଗୁଲ୍ ଟ୍ରାନ୍ସଲେସନ୍ | ନଲେଜ୍ ବଡି ଟ୍ରାନ୍ସଲେସନ୍ |
|---|---|---|
| which of the following law was given by Einstein: | ଆଇନ୍ଷ୍ଟାଇନ୍ ଦ୍ୱାରା ନିମ୍ନଲିଖିତ ନିୟମ ମଧ୍ୟରୁ କେଉଁଟି ଦିଆଯାଇଥିଲା: | ନିମ୍ନଲିଖିତ ମଧ୍ୟରୁ କେଉଁ ନିୟମ ଆଇନଷ୍ଟାଇନ୍ ବାହାର କରିଥିଲେ: |
| which one of the following is not alkaline earth metal? | ନିମ୍ନଲିଖିତ ମଧ୍ୟରୁ କେଉଁଟି କ୍ଷାରୀୟ ପୃଥିବୀ ଧାତୁ ନୁହେଁ? | ନିମ୍ନଲିଖିତ ମଧ୍ୟରୁ କେଉଁଟି ଆଲକାଲାଇନ୍ ଆର୍ଥ ମେଟାଲ୍ ନୁହେଁ? |
| Endogenous antigens are produced by intra-cellular bacteria within a host cell. | ଏଣ୍ଡୋଜେନସ୍ ଆଣ୍ଟିଜେନ୍ସ ଏକ ହୋଷ୍ଟ ସେଲ୍ ମଧ୍ୟରେ ଇଣ୍ଟ୍ରା-ସେଲୁଲାର୍ ବ୍ୟାକ୍ଟେରିଆ ଦ୍ produced ାରା ଉତ୍ପନ୍ନ ହୁଏ | | ପୋଷକ ସେଲ୍ ମଧ୍ୟରେ ଆନ୍ତଃକୋଶୀୟ ସେଲୁଲାର୍ ଜୀବାଣୁ ଦ୍ୱାରା ଅନ୍ତର୍ଜାତ ପ୍ରତିଜନକ ସୃଷ୍ଟି ହୋଇଥାଏ । |
ସଂକ୍ଷେପରେ, କଥୋପକଥନ AI ଚାଟ୍ ବଟ୍ ନଲେଜ୍ ବଡି ଲର୍ଣ୍ଣିଂ ଆଉଟକମ୍ ପ୍ରଦାନ କରିବାରେ ସାହାଯ୍ୟ କରି ଶିକ୍ଷାର୍ଥୀଙ୍କ ଶିକ୍ଷଣ ଯାତ୍ରାକୁ ପ୍ରଭାବିତ କରିପାରେ । ଏହା ପ୍ରତ୍ୟେକ ଶିକ୍ଷଣ ଅଧିବେଶନ ପରେ ଶିକ୍ଷାର୍ଥୀମାନଙ୍କୁ ସାହାଯ୍ୟ କରିପାରିବ, ଯେଉଁଠାରେ ଶିକ୍ଷାର୍ଥୀମାନେ ନିଜ ନିଜ ମାତୃଭାଷାରେ ପ୍ରଶ୍ନ ପଚାରିପାରିବେ, ସେମାନଙ୍କର ଡାଉଟ୍ ର ସମାଧାନ କରିପାରିବେ । ନଲେଜ୍ ବଡି ଆମର NLU ପ୍ଲାଟଫର୍ମ ମେଧାସ୍ ଦ୍ୱାରା ପରିଚାଳିତ, ଯାହା ଡୋମେନ୍ ଜ୍ଞାନର ଇନଫ୍ୟୁଜନ୍, ବ୍ୟାଖ୍ୟାତ୍ମକତା ଏବଂ ବ୍ୟାଖ୍ୟାକୁ ମୂଳ ଅନ୍ତର୍ନିହିତ ନୀତି ଭାବରେ ଦର୍ଶାଇଥାଏ [3][4][6][7][8] ।
ସନ୍ଦର୍ଭ:
[1] Raffel, Colin, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. “Exploring the limits of transfer learning with a unified text-to-text transformer.” arXiv preprint arXiv:1910.10683 (2019).
[2] Dong, Li, Nan Yang, Wenhui Wang, Furu Wei, Xiaodong Liu, Yu Wang, Jianfeng Gao, Ming Zhou, and Hsiao-Wuen Hon. “Unified language model pre-training for natural language understanding and generation.” arXiv preprint arXiv:1905.03197 (2019).
[3] Faldu, Keyur, Amit Sheth, Prashant Kikani, and Hemang Akabari. “KI-BERT: Infusing Knowledge Context for Better Language and Domain Understanding.” arXiv preprint arXiv:2104.08145 (2021).
[4] Gaur, Manas, Keyur Faldu, and Amit Sheth. “Semantics of the Black-Box: Can knowledge graphs help make deep learning systems more interpretable and explainable?.” IEEE Internet Computing 25, no. 1 (2021): 51-59.
[5] Zhu, Fengbin, Wenqiang Lei, Chao Wang, Jianming Zheng, Soujanya Poria, and Tat-Seng Chua. “Retrieving and reading: A comprehensive survey on open-domain question answering.” arXiv preprint arXiv:2101.00774 (2021).
[6] Gaur, Manas, Ankit Desai, Keyur Faldu, and Amit Sheth. “Explainable AI Using Knowledge Graphs.” In ACM CoDS-COMAD Conference. 2020.
[7] Sheth, Amit, Manas Gaur, Kaushik Roy, and Keyur Faldu. “Knowledge-intensive Language Understanding for Explainable AI.” IEEE Internet Computing 25, no. 5 (2021): 19-24.
[8] “[Tutorial] Explainable AI using Knowledge Graphs”, YouTube, ACM SIGKDD India Chapter, Jan 2021, https://www.youtube.com/watch?v=f1sahXYDjRI
[9] “#RAISE2020 – Embibe – AI-Powered learning outcomes platform for personalized education”, MyGov India, Oct 2020, https://www.youtube.com/watch?v=kuwFtHgN3qU
← AI ହୋମ୍କୁ ଫେରନ୍ତୁ


















