

Saas ମାଧ୍ୟମରେ AIକୁ ଅନଲକ୍ କରିବା
ମେଧାସ୍
ମେଧାସ୍, ଏକ ସଂସ୍କୃତ ଶବ୍ଦ, ଯାହାର ଅର୍ଥ ହେଉଛି ଜ୍ଞାନ, ବୁଝାମଣା ଏବଂ ବୁଦ୍ଧିମତା । EdTech AI ପ୍ଲାଟଫର୍ମ ପ୍ରସ୍ତୁତି ପାଇଁ ପ୍ରାକୃତିକ ଭାଷା ବୁଝାମଣା (NLU) ପ୍ଲାଟଫର୍ମ ଅତ୍ୟନ୍ତ ଗୁରୁତ୍ୱପୂର୍ଣ୍ଣ । NLU ସାମର୍ଥ୍ୟଗୁଡିକ ହାଇପର ଟ୍ୟାଗଡ୍ ଶିକ୍ଷଣ ଓ ମୂଲ୍ୟାଙ୍କନ ବିଷୟବସ୍ତୁ, ବିଷୟବସ୍ତୁ ନଲେଜ୍ ଗ୍ରାଫ୍, ବ୍ୟାଖ୍ୟାତ୍ମକ ଏବଂ ବର୍ଣ୍ଣନାଯୋଗ୍ୟ ପୂର୍ବାନୁମାନ ଆଦି ଶିକ୍ଷାର୍ଥୀମାନଙ୍କୁ ଶିକ୍ଷଣ ଫଳାଫଳ ହାସଲ କରିବା ପାଇଁ ବିଷୟବସ୍ତୁକୁ ସମୃଦ୍ଧ, ସୁପାରିଶ କିମ୍ବା ସୃଷ୍ଟି କରିବାକୁ ସକ୍ଷମ କରିଥାଏ । Embibe ରେ, ପ୍ରଶ୍ନ ପ୍ରସ୍ତୁତି, ପ୍ରଶ୍ନର ଉତ୍ତର, ଡାଉଟ୍ ରିଜୋଲ୍ୟୁସନ୍, ଇନଷ୍ଟା-ସଲଭର ଇତ୍ୟାଦି ଭଳି ବିଷୟବସ୍ତୁରେ ଏହା ଅତ୍ୟାଧୁନିକ ପ୍ରଦର୍ଶନ କରିବାରେ ସହାୟକ ହୋଇଥାଏ ।
ଆର୍ଟିଫିସିଆଲ୍ ଇଣ୍ଟେଲିଜେନ୍ସ ଏକ ଦୀର୍ଘ ପଥ ଅତିକ୍ରମ କରିଛି, ଗଭୀର ଶିକ୍ଷଣ କୌଶଳ ସହିତ ବିଭିନ୍ନ ବିଷୟ ପ୍ରୟୋଗର ବ୍ୟାପକ ପରିସରରେ ଏହାର ସମ୍ଭାବନାକୁ ସୁଦୃଢ କରିଛି । ତେବେ, ଆର୍ଟିଫିସିଆଲ୍ ଇଣ୍ଟେଲିଜେନ୍ସର ବର୍ତ୍ତମାନର ସ୍ଥିତି ବ୍ଲାକ୍-ବକ୍ସ ମଡେଲଗୁଡିକ ଦ୍ୱାରା ପ୍ରାଧାନ୍ୟ ବିସ୍ତାର କରିଛି । ଏହି ମଡେଲ୍ ଗୁଡିକ ଟ୍ରେନିଂ ଡାଟାରେ ପରିସଂଖ୍ୟାନ ଅନୁଯାୟୀ ମିଳିଥିବା ପ୍ରଚ୍ଛନ୍ନ ଢାଞ୍ଚାଗୁଡ଼ିକୁ ଶିକ୍ଷା କରି ଦକ୍ଷତା ହାସଲ କରିଥାଏ । ଏହି ମଡେଲଗୁଡିକ କେବଳ ଅବୋଧ୍ୟ ନୁହେଁ ବରଂ ସ୍ପଷ୍ଟ ଭାବରେ ପରିଭାଷିତ ବିଷୟ ପ୍ରସଙ୍ଗ ପାଇଁ ମଧ୍ୟ ଦୋଷପୂର୍ଣ୍ଣ ଅଟେ ।
ପ୍ଲାଟଫର୍ମ ମେଧାସ୍ର ଲକ୍ଷ୍ୟ ହେଉଛି:
- ଗଭୀର ଶିକ୍ଷଣ ମଡେଲଗୁଡ଼ିକୁ ବୋଧଗମ୍ୟ ଏବଂ ବ୍ୟାଖ୍ୟାଯୋଗ୍ୟ କରିବା
- ନଲେଜ୍ ଗ୍ରାଫରେ ସ୍ପଷ୍ଟ ଭାବରେ ବ୍ୟାଖ୍ୟା ହୋଇଥିବା ବିଷୟ ଜ୍ଞାନକୁ ଗଭୀର ଶିକ୍ଷଣ ମଡେଲଗୁଡିକରେ ଅନ୍ତର୍ଭୁକ୍ତ କରିବା
- ଗଭୀର ଶିକ୍ଷଣ ମଡେଲଗୁଡ଼ିକୁ ଏଜ୍ ଡିଭାଇସ୍ ଏବଂ ସଂସାଧନ-ସୀମିତ ଯୋଜନାରେ ଉପଲବ୍ଧ କରାଇବା
- ଅନ୍ୟ ଶବ୍ଦରେ, ସ୍ଥାନୀୟ ଅନ୍-ଡିଭାଇସ୍ ଇନଫେରେନ୍ସ କରିବାକୁ ମଡେଲ୍ ଅପ୍ଟିମାଇଜେସନ୍
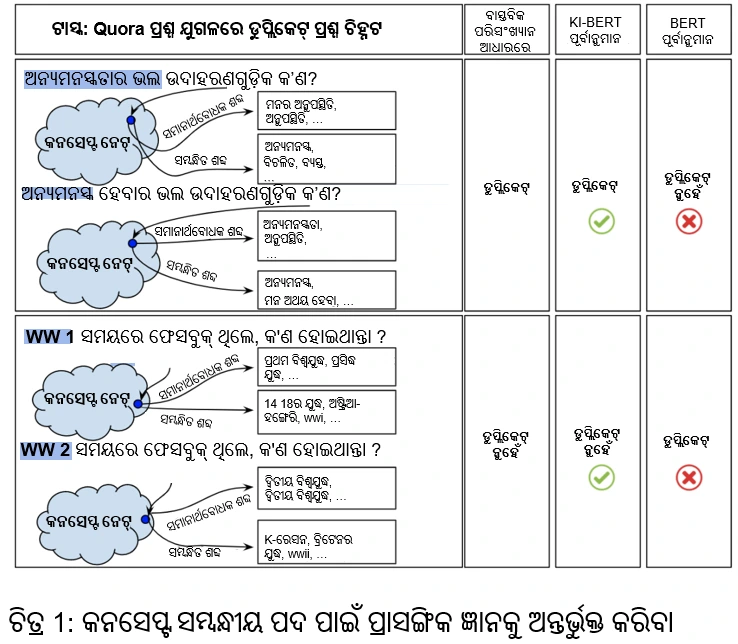
ନଲେଜ୍ ଗ୍ରାଫରୁ ଆମେ ସ୍ୱୟଂ-ଧ୍ୟାନ ବା ନିଜ ଧ୍ୟାନ ଭିତ୍ତିକ ମଡେଲରେ ଜ୍ଞାନ ଏମ୍ବେଡିଂ କରିଥାଉ । ଉଦାହରଣ ସ୍ୱରୂପ, ଆମେ ConceptNetରୁ “ଅନୁପସ୍ଥିତ ପ୍ରବୃତ୍ତି” ବା ଆବସେଣ୍ଟ ମାଇଣ୍ଡନେସ୍ ପରି ଧାରଣାଗତ ଉପାଦାନଗୁଡ଼ିକର ଏମ୍ବେଡିଂ ନେଇ ଏହାକୁ BERT ରେ ଟୋକେନ୍ ଏମ୍ବେଡିଂ ସହିତ ଇନଫ୍ୟୁଜ୍ କରିଥାଉ । “ଅନୁପସ୍ଥିତ ପ୍ରବୃତ୍ତି” ପାଇଁ ନଲେଜ୍ ଏମ୍ବେଡିଂରେ ସମାନ ପ୍ରକ୍ରିୟା ହୋଇଥାଏ । ତେଣୁ, ପରବର୍ତ୍ତୀ ସ୍ୱୟଂ- ଧ୍ୟାନ ସ୍ତର ମିଳିତ ଜ୍ଞାନ ଓ “ଅନୁପସ୍ଥିତ ପ୍ରବୃତ୍ତି” ଏବଂ “ମନର ଅନୁପସ୍ଥିତ” ଉପାଦାନଗୁଡ଼ିକର ଟୋକେନ୍ ଏମ୍ବେଡିଂ ପ୍ରତି ଧ୍ୟାନ ଦେବ ।
ଯେହେତୁ “ଅନୁପସ୍ଥିତ ପ୍ରବୃତ୍ତି ” ଏବଂ “ମନର ଅନୁପସ୍ଥିତି” ର ଜ୍ଞାନ ଏମ୍ବେଡିଂ ପ୍ରାୟତଃ ସମାନ ହେବ, ଏହି ଦୁଇଟି ସମାନ ଉପଦାନ ବୋଲି ମଡେଲ୍ ଧରିନେବ ।
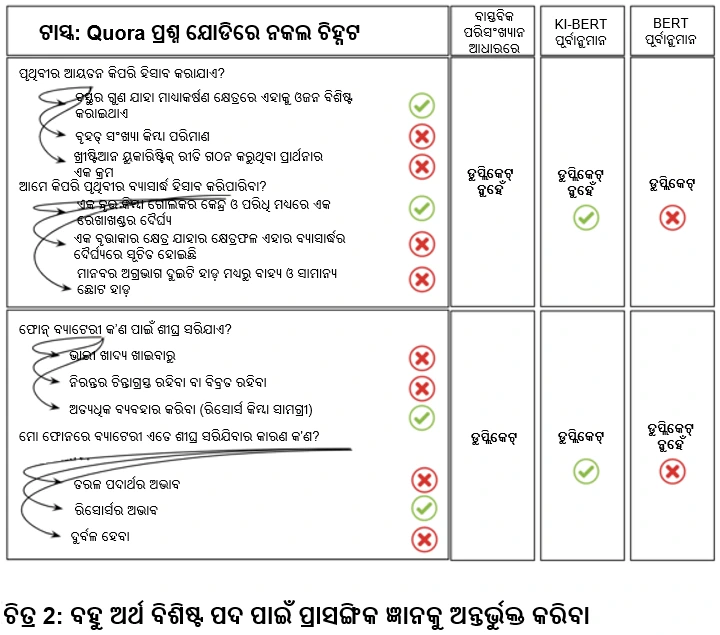
ଉପରୋକ୍ତ ଉଦାହରଣରେ, ଆମେ WordNetରୁ “ବସ୍ତୁତ୍ୱ” ଓ “ବ୍ୟାସାର୍ଦ୍ଧ” ପରି ଅସ୍ପଷ୍ଟ ଉପାଦାନଗୁଡ଼ିକର ଜ୍ଞାନ ଏମ୍ବେଡିଂ କରିଥାଉ ଏବଂ ଏହାକୁ BERT ର ସ୍ୱୟଂ ଧ୍ୟାନ ସ୍ତରରେ ସମାନ ଟୋକେନ୍ ଏମ୍ବେଡିଂ ସହିତ ଇନଫ୍ୟୁଜ୍ କରିଥାଉ ।
ତେଣୁ, ପରବର୍ତ୍ତୀ ସ୍ୱୟଂ-ଧ୍ୟାନ ସ୍ତର ଅସ୍ପଷ୍ଟ ଉପାଦାନଗୁଡ଼ିକର ମିଳିତ ଜ୍ଞାନ ଏମ୍ବେଡିଂ ଓ ଟୋକେନ୍ ଏମ୍ବେଡିଂ ପ୍ରତି ଧ୍ୟାନ ଦେବ ଏବଂ ଏହା ଇନପୁଟ୍ ବାକ୍ୟକୁ ଭଲ ଭାବରେ ବୁଝିବାରେ ସାହାଯ୍ୟ କରିବ ।
ଇନଫ୍ୟୁଜିଂ ନଲେଜ୍ କିପରି ଅଧିକ ବ୍ୟାଖ୍ୟାତ୍ମକ ଆତ୍ମବିଶ୍ୱାସ ପ୍ରଦାନ କରେ :
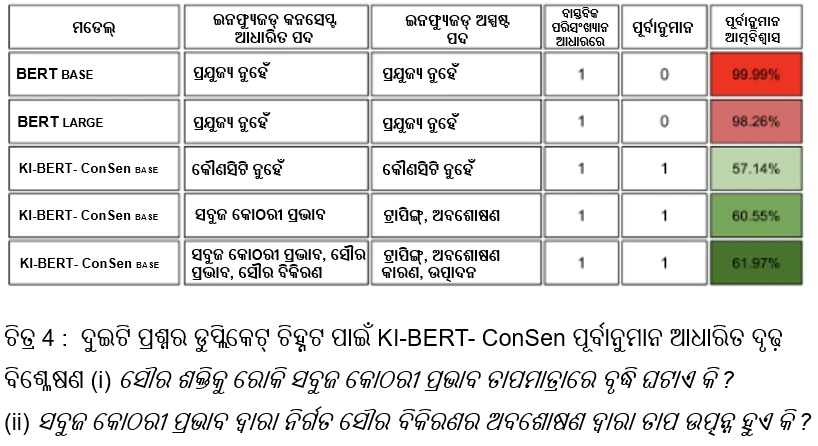
ଆମେ ଉପରୋକ୍ତ ଉଦାହରଣରେ (ଦ୍ୱିତୀୟ ଶେଷ ଧାଡି) ଦେଖିପାରୁ ଯେ, “ଗ୍ରୀନ୍ ହାଉସ୍ ଇଫେକ୍ଟ” ପରି ଧାରଣାଗତ ଉପାଦାନ ଏବଂ “ଟ୍ରାପିଙ୍ଗ୍” ଏବଂ “ଅବଶୋଷଣ” ପରି ଦ୍ୱନ୍ଦ୍ୱାତ୍ମକ ଉପାଦାନଗୁଡ଼ିକୁ ଯୋଡିବା ପରେ ଏହା କେବଳ ସଠିକ୍ ପୂର୍ବାନୁମାନ କଲାନାହିଁ, ବରଂ ଆମେ ଯେତେ ଉପାଦାନ ବଢାଇ ଚାଲିଲେ ପୂର୍ବାନୁମାନ କରିବାର ଆତ୍ମବିଶ୍ୱାସ 60.55% କୁ ବୃଦ୍ଧି ପାଇଲା ।
ଯେତେବେଳେ ଆମେ ଯଥାକ୍ରମେ “ସୌର ଶକ୍ତି” ଏବଂ “କାରଣ” ପରି ଅଧିକ ଦ୍ୱନ୍ଦ୍ୱାତ୍ମକ ଏବଂ ଧାରଣାଗତ ଉପାଦାନଗୁଡ଼ିକୁ ଯୋଡିଥିଲୁ, ଆତ୍ମବିଶ୍ୱାସ ଆହୁରି 61.97% କୁ ବୃଦ୍ଧି ପାଇଲା ।
ସଂକ୍ଷେପରେ କହିବାକୁ ଗଲେ, ଯେହେତୁ ଆମେ ଅଧିକ ଅର୍ଥପୂର୍ଣ୍ଣ ଉପାଦାନ ଯୋଡିଥାଉ, ଏହା କେବଳ ସଠିକ୍ ପୂର୍ବାନୁମାନ କରିନଥିଲା (ଭାନିଲା BERT ପରି, ଯାହା ଭୁଲ୍ ପୂର୍ବାନୁମାନ କରୁଥିଲା), ବରଂ ଏହା ମଡେଲର ଆତ୍ମବିଶ୍ୱାସକୁ ମଧ୍ୟ ବୃଦ୍ଧି କରିଥିଲା ।
ପ୍ଲାଟଫର୍ମ ମେଧାସ୍ Embibe ର ଏଜୁକେସନ୍ ରିସର୍ଚ୍ଚ ଲ୍ୟାବ୍ ଦ୍ୱାରା ପ୍ରସ୍ତୁତ ହୋଇଛି । ଏଜୁକେସନ୍ ରିସର୍ଚ୍ଚ ଲ୍ୟାବ୍ ହେଉଛି ଏକ ସ୍ୱତନ୍ତ୍ର ଶୃଙ୍ଖଳିତ ପ୍ରୟାସ, ଯାହାକି ବ୍ୟାପକ ପ୍ରଭାବ ସହିତ ପ୍ରମୁଖ ସମସ୍ୟାଗୁଡ଼ିକୁ ଚିହ୍ନଟ କରିଥାଏ ଏବଂ ମୌଳିକ ମୂଲ୍ୟବାନ ପ୍ରସ୍ତାବଗୁଡିକ ଉଦ୍ଭାବନ କରି ଅତ୍ୟାଧୁନିକ ଅନୁସନ୍ଧାନରେ ଅଗ୍ରଗତି କରେ ।
ସନ୍ଦର୍ଭ:
[4] Keyur Faldu. “Rise of Modern NLP and the Need of Interpretability!” Towards Data Science, August 2020.
[5] Keyur Faldu, Dr Amit Sheth. “Discovering the Encoded Linguistic Knowledge in NLP models.” Towards Data Science, September 2020.
[6] Keyur Faldu, Dr Amit Sheth. “Linguistics Wisdom of NLP Models.” Towards Data Science, November 2020.
[8] Faldu, Keyur, Aditi Avasthi, and Achint Thomas. “Adaptive learning machine for score improvement and parts thereof.” U.S. Patent 10,854,099, issued December 1, 2020.
[9] Dhavala, Soma, Chirag Bhatia, Joy Bose, Keyur Faldu, and Aditi Avasthi. “Auto Generation of Diagnostic Assessments and Their Quality Evaluation.” International Educational Data Mining Society (2020).
[10] Faldu, Keyur, Achint Thomas, and Aditi Avasthi. “System and method for recommending personalized content using contextualized knowledge base.” U.S. Patent Application 16/586,512, filed October 1, 2020.
[11] Thomas, Achint, Keyur Faldu, and Aditi Avasthi. “System and method for personalized retrieval of academic content in a hierarchical manner.” U.S. Patent Application 16/740,223, filed October 1, 2020.
[12] “#RAISE2020 – Embibe – AI-Powered learning outcomes platform for personalized education”, MyGov India, Oct 2020, https://www.youtube.com/watch?v=kuwFtHgN3qU
← AI ହୋମ୍କୁ ଫେରନ୍ତୁ


















