
ନଲେଜ୍ ଗ୍ରାଫ୍ ନୋଡ୍ର ସ୍ୱୟଂଚାଳିତ ଅନ୍ୱେଷଣ
ଉପକ୍ରମ:
Embibe ନଲେଜ୍ ଗ୍ରାଫ୍ ହେଉଛି ଏକ ପାଠ୍ୟକ୍ରମ-ଆଗ୍ନୋଷ୍ଟିକ୍ ବହୁ-ଆୟାମୀ ଗ୍ରାଫ୍, ଯାହା 75,000+ ନୋଡ୍କୁ ନେଇ ଗଠିତ, ପ୍ରତ୍ୟେକଟି ବିଷୟଗତ ଜ୍ଞାନର ଏକ ପୃଥକ ଏକକକୁ ଦର୍ଶାଇଥାଏ, ଏହାକୁ ଧାରଣା ବା କନସେପ୍ଟ ମଧ୍ୟ କୁହାଯାଇଥାଏ । ସେମାନଙ୍କ ମଧ୍ୟରେ ଲକ୍ଷାଧିକ ସଂଯୋଗ ମଧ୍ୟ ଦର୍ଶାଏ ଯେ କନସେପ୍ଟ କିପରି ସ୍ୱତନ୍ତ୍ର ନୁହେଁ ବରଂ ଏହା ଅନ୍ୟାନ୍ୟ କନସେପ୍ଟ ସହିତ ସମ୍ପର୍କିତ ।
ଯେହେତୁ Embibe ଏହାର ବିଷୟବସ୍ତୁକୁ ନିରନ୍ତର ବୃଦ୍ଧି କରିଥାଏ, ନଲେଜ୍ ଗ୍ରାଫ୍ ମଧ୍ୟ କ୍ରମାଗତ ଭାବରେ ବିକଶିତ ହୁଏ । ଗ୍ରାଫ୍ର କିଛି ଅଂଶକୁ ସ୍ମାର୍ଟ ଅଟୋମେସନ୍ ଓ ବିଶେଷଜ୍ଞଙ୍କ ଜ୍ଞାନ ବ୍ୟବହାର କରି ପ୍ରସ୍ତୁତ କରାଯାଇଛି । ତେବେ, ସ୍ୱୟଂଚାଳିତ ଭାବରେ ଗ୍ରାଫ୍ର ନୂତନ ନୋଡ୍ ଅନ୍ୱେଷଣ କରିବା ଏବଂ ବିଷୟଗତ ଜ୍ଞାନ ପରିସରର ଅଧିକ ଭାଗ ଅନ୍ତର୍ଭୁକ୍ତ କରିବା ପାଇଁ ଗ୍ରାଫ୍କୁ ବିସ୍ତାର କରିବା ଲକ୍ଷ୍ୟରେ Embibe ଗବେଷଣା ଜାରି ରଖିଛି । ବିଷୟଗତ ଭିନ୍ନତା ଫ୍ରେଜ୍ ଏକ୍ସଟ୍ରାକଟର୍ ଆମକୁ ଏକ ଲେବଲ୍ ଡାଟା ସେଟ୍ ଏବଂ BERT ଆଧାରିତ ମଡେଲ୍ ବ୍ୟବହାର କରି ନଲେଜ୍ ଗ୍ରାଫ୍ରେ ନୂଆ ନୋଡ୍ ଅନ୍ୱେଷଣ କରିବାକୁ ସକ୍ଷମ କରିଥାଏ ଏବଂ ସେହି ବାକ୍ୟାଂଶ ଓ ସେଗୁଡ଼ିକର ପ୍ରାସଙ୍ଗିକତା ସ୍ତର ପ୍ରଦାନ କରିଥାଏ ।
ଏକାଡେମିକ୍ ଡିଫରେନ୍ସିଏଟେଡ୍ ଫ୍ରେଜ୍ ଏକ୍ସାଟ୍ରାକଟର୍:
ଏକାଡେମିକ୍ ଡିଫରେନ୍ସିଏଟେଡ୍ ଫ୍ରେଜ୍ ଏକ୍ସଟ୍ରାକ୍ଟର (ADPE) ବିଷୟଗତ ପୁସ୍ତକର ଗୁରୁତ୍ୱପୂର୍ଣ୍ଣ ପାଠଗୁଡିକୁ ସ୍ୱୟଂଚାଳିତ ଭାବେ ଅଣ୍ଡରଲାଇନ୍ କରିଦିଏ । ଯେପରି ଜଣେ ବିଦ୍ୟାର୍ଥୀ ପୁସ୍ତକ ପଢିବାବେଳେ ଗୁରୁତ୍ୱପୂର୍ଣ୍ଣ କନସେପ୍ଟଗୁଡ଼ିକୁ ଅଣ୍ଡରଲାଇନ୍ କରେ, ସେହିଭଳି ଏହା କାର୍ଯ୍ୟ କରିଥାଏ । ଏହାର ମୂଳ ଉଦ୍ଦେଶ୍ୟ ହେଉଛି ଅଣସଂଗଠିତ ପାଠ୍ୟରୁ କନସେପ୍ଟଗୁଡିକୁ ବାହାର କରିବା । ଅଧିକାଂଶ କନସେପ୍ଟକୁ ପୁସ୍ତକ ପାଠ୍ୟର ସବସ୍ପାନ୍ ଭାବରେ ଚିହ୍ନଟ କରାଯାଇପାରେ, ଏହି ପରିକଳ୍ପନାରୁ ଆଧାର କରି ଫ୍ରେଜ୍ ଏକ୍ସଟ୍ରାକ୍ଟର ପରିଚାଳିତା ହୋଇଥାଏ ।
ପାଠ୍ୟସାମଗ୍ରୀରୁ ଗୁରୁତ୍ୱପୂର୍ଣ୍ଣ ପଦଗୁଡ଼ିକୁ ବାଛିବା ଏବଂ ଏକକ ଭାବରେ ଚିହ୍ନଟ କରିବା ଏକ ବ୍ୟାପକ ପ୍ରକ୍ରିୟା । ତେବେ ବିଷୟ ପୁସ୍ତକରୁ କନସେପ୍ଟ ବାହାର କରିବା ଏକ ଚ୍ୟାଲେଞ୍ଜିଂ କାର୍ଯ୍ୟ ଏବଂ ଏହା ସୀମିତ ପରିସରରେ କରାଯାଏ । ସଂଜ୍ଞା ଅନୁଯାୟୀ କନସେପ୍ଟ ବାହାର କରିବା ହେଉଛି ଏକ ପରିପୂର୍ଣ୍ଣ ପ୍ରକ୍ରିୟା, ଅର୍ଥାତ୍ ସେହି ସମସ୍ତ କନସେପ୍ଟ ବାହାର କରାଯିବା ଆବଶ୍ୟକ, ଯେଉଁଗୁଡିକ ଅଧ୍ୟାୟର ପ୍ରାସଙ୍ଗିକତାକୁ ଦେଖି ସେଗୁଡିକର ସହ-ସଂଯୋଗ ଓ ପ୍ରାସଙ୍ଗିକତାକୁ ବର୍ଣ୍ଣନା କରୁଥିବା ଅଧ୍ୟାୟ କନସେପ୍ଟ କ୍ରମର ଅଂଶବିଶେଷ ହୋଇଥିବେ । ଏହା ମୁଖ୍ୟ-ବାକ୍ୟାଂଶ ବାହାର କରିବା ଠାରୁ ଭିନ୍ନ ଅଟେ । କାରଣ ଏହା ବିଷୟ ବର୍ଣ୍ଣନା କରୁଥିବା ଟପ୍- n ମୁଖ୍ୟପଦ ଉପରେ ଗୁରୁତ୍ୱ ଦେଇଥାଏ, ପ୍ରାସଙ୍ଗିକତା କୌଣସି ଅର୍ଥପୂର୍ଣ୍ଣ କ୍ରମରେ ରହିବା ନିହାତି ଜରୁରୀ ନୁହେଁ । ଅଧିକନ୍ତୁ, ଏହା ନାମିତ ଏଣ୍ଟିଟି ବାହାର କରିବାଠାରୁ ମଧ୍ୟ ଭିନ୍ନ ଅଟେ, କାରଣ ଏହା ପୂର୍ବ-ନିର୍ଦ୍ଦିଷ୍ଟ ଶ୍ରେଣୀର (ଯଥା: ଅବସ୍ଥାନ, ବ୍ୟକ୍ତି, ORG) ଅଧିନରେ ଥିବା ସାଧାରଣତଃ ବାକ୍ୟଗୁଡିକ ଭଳି କ୍ଷୁଦ୍ର ପାଠ୍ୟରୁ ଏକକ ଉଦାହରଣ ବାହାର କରିବା ଉପରେ ଗୁରୁତ୍ୱ ଦିଏ । ତେବେ ଏହା ଅର୍ଥଗତ କ୍ରମ ଗଠନ କରିବା ନିହାତି ଜରୁରୀ ନୁହେଁ । ଯାହା ଆମର ଅନନ୍ୟ, ସମ୍ବନ୍ଧୀୟ କନସେପ୍ଟ ବାହାର କରିବାର ଲକ୍ଷ୍ୟର ପରିପନ୍ଥୀ । ଆମେ ଉତ୍ତମ ମେସିନ୍ ଲର୍ଣ୍ଣିଂ ଓ ଗଭୀର-ଶିକ୍ଷଣ ଆଧାରଯୁକ୍ତ ପର୍ଯ୍ୟବ୍ୟକ୍ଷିତ/ଅଣପର୍ଯ୍ୟବ୍ୟକ୍ଷିତ ଟେକନିକ୍ ବ୍ୟବହାର କରି ଏଭଳି କାର୍ଯ୍ୟ ପ୍ରସ୍ତୁତି ଦ୍ୱାରା ପ୍ରେରିତ ହୋଇ ସିଦ୍ଧାନ୍ତ ଆଧାରିତ କନସେପ୍ଟ ବାହାର କରିବାର ଆଭିମୁଖ୍ୟ ଉପସ୍ଥାପନ କରୁଛୁ ।
ଅନୁସନ୍ଧାନ ଦୃଷ୍ଟିକୋଣ:
ଆମର ପରୀକ୍ଷଣଗୁଡିକ ADPE ଡାଟାସେଟରେ କାର୍ଯ୍ୟଦକ୍ଷତାକୁ ଉନ୍ନତ କରିବା ପାଇଁ ଅତ୍ୟାଧୁନିକ ଗଭୀର ଶିକ୍ଷଣ କୌଶଳକୁ ଉପଯୋଗ କରିଥାଏ, ଯେପରିକି ଦୁଇ ପ୍ରାଥମିକ ବର୍ଗୀକରଣ ଫର୍ମୁଲେସନ୍ ରେ BERT (ବାଇଡିରେକ୍ସନାଲ୍ ଏନକକୋଡ୍ର ରିପ୍ରେଜେଣ୍ଟେସନସ୍ ଫ୍ରମ୍ ଟ୍ରାନସଫର୍ମର୍ସ), LSTM (ଲଙ୍ଗ ସର୍ଟ-ଟର୍ମ ମେମୋରି), CNN (କନଭୋଲ୍ୟୁସନ୍ ନ୍ୟୁରାଲ୍ ନେଟୱାର୍କ) । ପ୍ରଥମଟି ହେଉଛି ନାମିତ ଏଣ୍ଟିଟି ଚିହ୍ନଟ ପାଇଁ କ୍ରମ ଟ୍ୟାଗିଂ ଏବଂ ଦ୍ୱିତୀୟଟି ହେଉଛି n- ଗ୍ରାମ ଶ୍ରେଣୀକରଣ । ଏହା ପରିସଂଖ୍ୟାନ, ଅର୍ଥଗତ, ପ୍ରାକୃତିକ ଭାଷା ପ୍ରକ୍ରିୟାକରଣ, ପାଠ୍ୟ ବୈଶିଷ୍ଟ୍ୟ ଯୁକ୍ତ ପ୍ରାର୍ଥୀଙ୍କ n- ଗ୍ରାମ ପ୍ରସ୍ତୁତ କରିବା ଏବଂ ଡିପ୍-ନ୍ୟୁରାଲ୍ ନେଟଓ୍ୱାର୍କ ବ୍ୟବହାର କରି ବର୍ଗୀକରଣ କରିବା ପାଇଁ ହୋଇଥାଏ ।
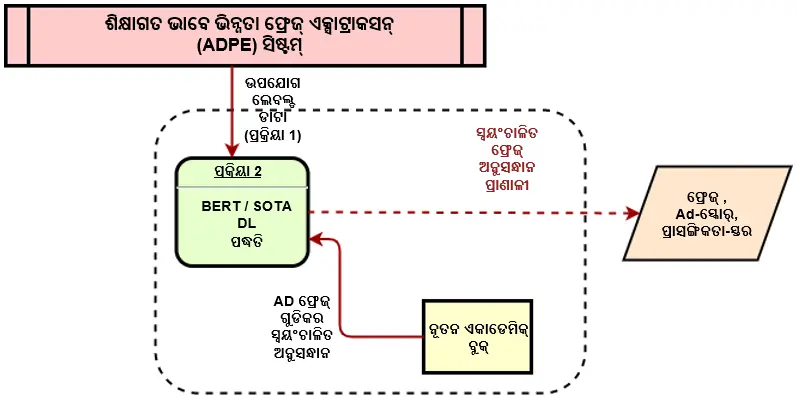
ଆମେ ବର୍ଦ୍ଧିତ ଶବ୍ଦାବଳୀ, ବୈଜ୍ଞାନିକ ପତ୍ରିକା ଓ ପୁସ୍ତକ ଅଧ୍ୟାୟ ବିଶିଷ୍ଟ BERT ଉନ୍ମୋଚିତ ମଡେଲକୁ ଉପଯୋଗ କରୁ । ଆହୁରି ମଧ୍ୟ, ଇନପୁଟ୍ ହୋଇଥିବା ପାଠ୍ୟବସ୍ତୁରୁ କନସେପ୍ଟ ଅନ୍ୱେଷଣ କରିବା ପାଇଁ ସମସ୍ତ ଏନକୋଡର୍ ସ୍ତରର ଉପସ୍ଥାପନାଗୁଡିକ ଏକ ବାଧିତ-ସ୍ଥାନାନ୍ତରଣ (BIO ଏନକୋଡିଂ) CRF (କଣ୍ଡିସନାଲ୍ ରେଣ୍ଡମ ଫିଲ୍ଡ) କ୍ରମିକ ଟ୍ୟାଗରରେ ଫିଡ୍ କରାଯାଇଥାଏ ।
CRF (କଣ୍ଡିସନାଲ୍ ରାଣ୍ଡମ୍ ଫିଲ୍ଡ) କାହିଁକି :
- CRF ଅନୁକ୍ରମର ଲଗ୍ ସମ୍ଭାବନାକୁ ସର୍ବାଧିକ କରିଥାଏ ଏବଂ ଅନୁକ୍ରମ ଟ୍ୟାଗଗୁଡ଼ିକର ସର୍ବାଧିକ ସମ୍ଭାବନା ଆକଳନ ସୃଷ୍ଟି କରେ ।
- CRF ସୀମାବଦ୍ଧତା ନିଶ୍ଚିତ କରେ ଯେ କେବଳ ବୈଧ ମଲ୍ଟିଗ୍ରାମ୍ ଅନୁକ୍ରମ ଲେବଲ୍, ଲେବଲ୍ ଏନକୋଡିଂ ଦ୍ୱାରା ନିର୍ଦ୍ଧାରିତ ଭାବରେ ସୃଷ୍ଟି ହୋଇଥାଏ – (ଉଦାହରଣ ସ୍ୱରୂପ: BIO ଏନକୋଡିଂ ଏକ ଅନୁକ୍ରମରେ ଏଣ୍ଟିଟି ସେଗମେଣ୍ଟେସନ୍ କୁ ନିଶ୍ଚତ କରେ କିନ୍ତୁ ଏହାର କିଛି ବ୍ୟାକରଣ ନିୟମ ଅଛି ଯାହା ପୂରଣ ହେବା ଆବଶ୍ୟକ)
- CRF କ୍ରମିକ ଲଗ୍ ସମ୍ଭାବନା କ୍ଷତି ଭାବରେ ବ୍ୟବହୃତ ହୁଏ ଯାହାକି ଏକ ସାଧାରଣ ରୈଖିକ ସ୍ତର ଅପେକ୍ଷା ନେଟୱାର୍କ୍ ର (ଯଦି ଫ୍ରିଜ୍ ହୋଇନଥାଏ) ଆଉଟପୁଟ୍ ଲଜିଟ୍ କୁ ଅଧିକ ଅପ୍ଟିମାଇଜ୍ କରିଥାଏ । ସାଧାରଣ ରୈଖିକ ସ୍ତରର ଫଳାଫଳକୁ CRF ଉତ୍ତମ ରୈଖିକ ସ୍ତର ସହିତ ତୁଳନା ଦ୍ୱାରା ଏହା ସୁନିଶ୍ଚିତ କରାଯାଇପାରିବ ।
ସାରାଂଶ:
ନଲେଜ୍ ଗ୍ରାଫ୍ ହେଉଛି ସମସ୍ତ Embibe ଉତ୍ପାଦଗୁଡ଼ିକର ମୂଳଧାରା । ତେଣୁ ନଲେଜ୍ ଗ୍ରାଫ୍ ସମାପ୍ତ କରିବା ହେଉଛି ଆମର ପ୍ରାଥମିକ କାର୍ଯ୍ୟ । ଏହି କାର୍ଯ୍ୟ ଆମକୁ ନଲେଜ୍ ଗ୍ରାଫ୍ ବଜାୟ ରଖିବାରେ ସାହାଯ୍ୟ କରିଥାଏ ଏବଂ ସର୍ବନିମ୍ନ ମାନୁଆଲ୍ ହସ୍ତକ୍ଷେପ ସହିତ ଶୀଘ୍ର ବିସ୍ତାର କରିଥାଏ ।
ଏହି ଅଭ୍ୟାସ ମଡେଲରେ BERT ବ୍ୟବହାର କରାଯାଇ ଏହାକୁ ଦକ୍ଷ କରାଯାଇଛି ଏବଂ ଡାଟା ପ୍ରକ୍ରିୟାକରଣ, ମଡେଲିଂ ଓ ଭାଲିଡେସନ୍ ପାଇଁ ଅନ୍ୟାନ୍ୟ କୌଶଳ ବ୍ୟବହାର କରାଯାଏ । ଅସଂପୂର୍ଣ୍ଣ ଏକାଡେମିକ୍ ପାଠ୍ୟରୁ ଗୁରୁତ୍ୱପୂର୍ଣ୍ଣ ଏକାଡେମିକ୍ ଶବ୍ଦଗୁଡ଼ିକୁ ଅଣ୍ଡରଲାଇନ୍ କରିବା ପାଇଁ ଏକାଡେମିକ୍ ଡିଫେରିଏଟେଡ୍ ଫ୍ରେଜ୍ ଏକ୍ସଟ୍ରାକ୍ଟର ବ୍ୟବହାର କରାଯାଏ । ତେଣୁ, ଆମେ ବିଭିନ୍ନ ଉତ୍ସରୁ ପ୍ରଦତ୍ତ ପାଠ୍ୟବସ୍ତୁରୁ କନସେପ୍ଟ ଖୋଜିବା ପ୍ରକ୍ରିୟାକୁ ସ୍ୱୟଂଚାଳିତ କରିଛୁ ।
ସନ୍ଦର୍ଭ:
[1] Devlin Jacob, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805 (2018).
[2] Zhiheng Huang, Wei Xu, Kai Yu. Bidirectional LSTM-CRF Models for Sequence Tagging. arXiv preprint arXiv:1508.01991 (2015)
[3] William Cavnar and John Trenkle. N-Gram-Based Text Categorization. In Proceedings of SDAIR-94, 3rd Annual Symposium on Document Analysis and Information Retrieval (Las Vegas, US, 1994), pp. 161–175.




















