
ନଲେଜ୍ ଗ୍ରାଫ୍ ନୋଡ୍ ମଧ୍ୟରେ ଥିବା ସମ୍ପର୍କର ସ୍ୱୟଂ-ବର୍ଗୀକରଣ
ଉପକ୍ରମ:
Embibe ନଲେଜ୍ ଗ୍ରାଫ୍ (KG) ହେଉଛି ଏକ ପାଠ୍ୟକ୍ରମ-ଆଗ୍ନୋଷ୍ଟିକ୍ ବହୁ-ଆୟାମୀ ଗ୍ରାଫ୍, ଯାହା 75,000+ ରୁ ଅଧିକ ନୋଡ୍କୁ ନେଇ ଗଠିତ, ପ୍ରତ୍ୟେକଟି ବିଷୟଗତ ଜ୍ଞାନର ଏକ ପୃଥକ ଏକକକୁ ଦର୍ଶାଇଥାଏ, ଏହାକୁ ଧାରଣା ବା କନସେପ୍ଟ ମଧ୍ୟ କୁହାଯାଇଥାଏ । ସେମାନଙ୍କ ମଧ୍ୟରେ ଲକ୍ଷାଧିକ ସଂଯୋଗ(ସମ୍ପର୍କ) ମଧ୍ୟ ଦର୍ଶାଏ ଯେ କନସେପ୍ଟ କିପରି ସ୍ୱତନ୍ତ୍ର ନୁହେଁ ବରଂ ଏହା ଅନ୍ୟାନ୍ୟ କନସେପ୍ଟ ସହିତ ସମ୍ପର୍କିତ ।
ନୋଡ୍ର ଆନ୍ତଃ-ସଂଯୋଗଗୁଡ଼ିକୁ ସେମାନଙ୍କ ମଧ୍ୟରେ ଥିବା ସମ୍ପର୍କ ଆଧାରରେ ଶ୍ରେଣୀଭୁକ୍ତ କରାଯାଇଥାଏ । ଗବେଷକମାନଙ୍କ ପାଇଁ ଅସମ୍ପୂର୍ଣ୍ଣ ନଲେଜ୍ ଗ୍ରାଫ୍ ଓ ମିଳୁନଥିବା ସମ୍ପର୍କଗୁଡିକ ହେଉଛି ସାଧାରଣ ସମସ୍ୟା । ତେବେ, ଯେହେତୁ Embibe ଏହାର ବିଷୟବସ୍ତୁକୁ ନିରନ୍ତର ବିସ୍ତାର କରିଥାଏ, ତେଣୁ ପ୍ରକ୍ରିୟାକୁ ସ୍ୱୟଂଚାଳିତ କରିବାର ଜରୁରୀ ଆବଶ୍ୟକତା ରହିଛି । ଗତ 8 ବର୍ଷ ମଧ୍ୟରେ ଲକ୍ଷ ଲକ୍ଷ ବିଦ୍ୟାର୍ଥୀଙ୍କ ପାଇଁ KG କନସେପ୍ଟ ଉପରେ ପାରସ୍ପରିକ ତଥ୍ୟର ଉପଲବ୍ଧତାକୁ ଦୃଷ୍ଟିରେ ରଖି ଏବଂ ଗ୍ରାଫ୍ ସିଦ୍ଧାନ୍ତ ଓ ପ୍ରାକୃତିକ ଭାଷା ବୋଧ ଟେକନିକ୍ ବ୍ୟବହାର କରି ସମ୍ପର୍କଗୁଡ଼ିକୁ N ଶ୍ରେଣୀରେ ସ୍ୱୟଂ – ଶ୍ରେଣୀଭୁକ୍ତ କରିବା ସମ୍ଭବ ଅଟେ ।
ସମ୍ପର୍କର ପ୍ରକାର:
Embibeର KGରେ, ଧାରଣା ବା କନସେପ୍ଟ ମଧ୍ୟରେ 16 ଟି ଭିନ୍ନ ଭିନ୍ନ ସମ୍ପର୍କ ରହିଛି । ଏହି ସମ୍ପର୍କଗୁଡିକ ମଧ୍ୟରୁ ଗୋଟିଏ ହେଉଛି ପୂର୍ବ-ଆବଶ୍ୟକତା । ଏକ ନିର୍ଦ୍ଦିଷ୍ଟ କନସେପ୍ଟ ଶିଖିବା ପୂର୍ବରୁ ସମସ୍ତ ପୂର୍ବ-ଆବଶ୍ୟକତା ସମ୍ପର୍କ ଆମ KGରେ ଦିଆଯାଇଛି । ସାଧାରଣତଃ, କୌଣସି କନସେପ୍ଟ ଶିଖିବା ପୂର୍ବରୁ ଜଣେ ବିଦ୍ୟାର୍ଥୀ ପ୍ରଥମେ ପୂର୍ବ-ଆବଶ୍ୟକତା ଶିଖେ । କନସେପ୍ଟକୁ ଭଲ ଭାବରେ ବୁଝିବା ପାଇଁ ଏହା ସେମାନଙ୍କୁ ସାହାଯ୍ୟ କରେ । କନସେପ୍ଟ କୌଶଳ ଓ ଶିକ୍ଷଣ ମାର୍ଗ ପାଇବା ପାଇଁ ଆମେ କୋଟି କୋଟି ପ୍ରାକ୍ଟିସ୍ ଏବଂ ଲକ୍ଷ ଲକ୍ଷ ବିଦ୍ୟାର୍ଥୀଙ୍କ ଟେଷ୍ଟ ପ୍ରୟାସକୁ ବିଶ୍ଳେଷଣ କରିଛୁ । କନସେପ୍ଟ ମଧ୍ୟରେ ପରୀକ୍ଷାମୂଳକ କାରଣ ପ୍ରତିଷ୍ଠା ପାଇଁ ଏହି ଢାଞ୍ଚାଗୁଡ଼ିକ ବ୍ୟବହୃତ ହୁଏ । ତଥ୍ୟର ଏହି ଲୁକ୍କାୟିତ ଗୁଣ ଲକ୍ଷ୍ୟ ହାସଲ ପାଇଁ ବିଦ୍ୟାର୍ଥୀମାନେ ଅନୁସରଣ କରୁଥିବା ସାଧାରଣ ଶିକ୍ଷଣ ମାର୍ଗ ନିରୂପଣ କରିବାରେ ସାହାଯ୍ୟ କରୁଛି । ସ୍କୋରିଂ ପଦ୍ଧତି ଆଧାରରେ ପୂର୍ବ-ଆବଶ୍ୟକତା ନିରୂପଣ କରିବା ପାଇଁ ଆମେ ଏହି ସାଧାରଣ ଶିକ୍ଷଣ ମାର୍ଗଗୁଡିକ ବ୍ୟବହାର କରିଛୁ ।
ଗବେଷଣା ପଦ୍ଧତି:
ବିଦ୍ୟାର୍ଥୀମାନଙ୍କ ପାଇଁ କନସେପ୍ଟ ମାଷ୍ଟରୀର ପୂର୍ବାନୁମାନ କରିବା ପାଇଁ ଆମେ ନଲେଜ୍ ଗ୍ରାଫ୍ ରୁ ନଲେଜ୍ ଇନଫ୍ୟୁଜନ୍ ସହିତ ଗଭୀର ଜ୍ଞାନ ଅନୁସନ୍ଧାନର ଅତ୍ୟାଧୁନିକ କୌଶଳକୁ ବିସ୍ତାର କରିଛୁ । ପୂର୍ବ ଅଭିଜ୍ଞତା ଆଧାରରେ କୋଲ୍ଡ ଷ୍ଟାର୍ଟ ପ୍ରୋବ୍ଲେମ୍ ର ସମାଧାନ ପାଇଁ କଣ୍ଡିସନାଲ୍ କନସେପ୍ଟ ମାଷ୍ଟରୀର ଉପଯୋଗ କରିଥାଉ । ବିଦ୍ୟାର୍ଥୀମାନଙ୍କର ଆଚରଣ ଅନୁଧ୍ୟାନ କରିବା ଏବଂ ନଲେଜ୍ ଗ୍ରାଫ୍ କନସେପ୍ଟରେ ଏହାକୁ ପ୍ରତିଫଳନ କରିବାର ବୈଶିଷ୍ଟ୍ୟ ଯୋଗୁଁ Embibe ଏକ ଅଦ୍ୱିତୀୟ ପ୍ଲାଟଫର୍ମ ହୋଇପାରିଛି । କନସେପ୍ଟଗୁଡ଼ିକର ସମ୍ପର୍କକୁ ଶ୍ରେଣୀଭୁକ୍ତ କରିବାରେ ସେଗୁଡ଼ିକର ଏସବୁ ଆଚରଣଗତ ବୈଶିଷ୍ଟ୍ୟଗୁଡ଼ିକ ମଧ୍ୟ ବ୍ୟବହାର କରାଯାଇଥାଏ ।
ନଲେଜ୍ ଗ୍ରାଫ୍ର ବିସ୍ତାର :
କନସେପ୍ଟ ମଧ୍ୟରେ ଅନେକ ସମ୍ପର୍କ ଥିବା ଆମେ ଜାଣିଛେ । ଯେତେବେଳେ କୌଣସି ନୂତନ କନସେପ୍ଟ ଏକ ଗ୍ରାଫ୍ ରେ ଉପସ୍ଥାପିତ ହୁଏ, ଆମେ ଅନ୍ୟ ସମ୍ପର୍କ ସହିତ ଏହାର ସମ୍ପର୍କକୁ ବ୍ୟାଖ୍ୟା କରିବା ଆବଶ୍ୟକ । କାର୍ଯ୍ୟର ଜଟିଳତା ହେତୁ ଏହା ଏକ ଗୁରୁତ୍ୱପୂର୍ଣ୍ଣ ଅଭ୍ୟାସ ହୋଇଯାଏ । ଯେକୌଣସି ଭୁଲ୍ ସମ୍ପର୍କ ଟ୍ୟାଗିଂ ୟୁଜର୍ଙ୍କୁ ଭୁଲ୍ ଦିଗକୁ ନିର୍ଦ୍ଦେଶିତ କରିପାରେ ।
Embibeରେ, ଆମେ ଆମର ଉତ୍ପାଦକୁ ବିଭିନ୍ନ ଭାଷାରେ ଏବଂ ବିଭିନ୍ନ ପାଠ୍ୟକ୍ରମ ପାଇଁ ଲଞ୍ଚ କରିବାକୁ ଚାହୁଁ । ଏହି ନୂତନ କନସେପ୍ଟ ପାଇଁ ଆମକୁ KG କୁ ବିସ୍ତାର କରିବାକୁ ପଡିବ । ଆଜି ପର୍ଯ୍ୟନ୍ତ ଆମେ ନୂତନ କନସେପ୍ଟ ଅନ୍ୱେଷଣ, ଅନ୍ୟାନ୍ୟ କନସେପ୍ଟ ଓ ପୂର୍ବରୁ ଥିବା ସମ୍ପର୍କ ଭାଲିଡେସନ୍ ଆଦି ସହ ସେଗୁଡିକର ସମ୍ପର୍କ ନିରୂପଣ କରିବା ପାଇଁ ଅଧ୍ୟାପକମାନଙ୍କ ଉପରେ ସମ୍ପୂର୍ଣ୍ଣ ନିର୍ଭରଶୀଳ । ଏହି କାର୍ଯ୍ୟଗୁଡ଼ିକ ଅତ୍ୟନ୍ତ ଧୀର ଓ କଠିନ ବ୍ୟାପାର ଥିଲା । ଯେହେତୁ ତଥ୍ୟର ପରିମାଣ ଦ୍ରୁତ ଗତିରେ ବୃଦ୍ଧି ପାଉଛି, ଏହା ଆମ ପାଇଁ ଅତ୍ୟନ୍ତ ଚ୍ୟାଲେଞ୍ଜିଙ୍ଗ୍ । ସମଗ୍ର ତଥ୍ୟ ପ୍ରସ୍ତୁତି ପ୍ରକ୍ରିୟାରେ ପକ୍ଷପାତିତା ହେବାର ଆଶଙ୍କା ମଧ୍ୟ ରହିଛି ।
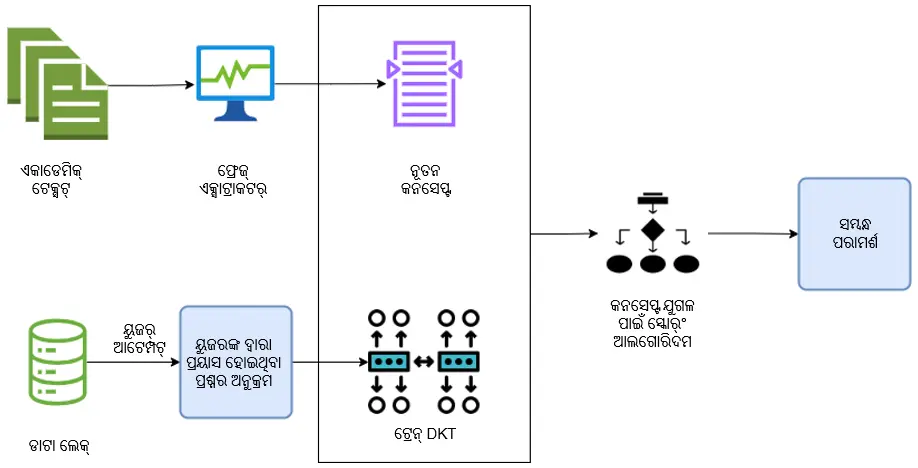
କୌଣସି କନସେପ୍ଟ ଶିଖିବା ପୂର୍ବରୁ ଆମେ ଦେଖିଛୁ ବିଦ୍ୟାର୍ଥୀମାନେ ତତ୍ସମ୍ପର୍କିତ ପୂର୍ବ-ଆବଶ୍ୟକତାଗୁଡିକୁ ଶିଖିଥାନ୍ତି । ତେଣୁ ବିଦ୍ୟାର୍ଥୀମାନଙ୍କ ପ୍ରୟାସ ଅନୁକ୍ରମ (ଉତ୍ତର ପାଇଁ ଉଦ୍ୟମ କରିଥିବା ପ୍ରଶ୍ନ ଅନୁକ୍ରମ)ରେ କନସେପ୍ଟ ପୂର୍ବରୁ ପୂର୍ବ-ଆବଶ୍ୟକତା କନସେପ୍ଟ ରହିବ । ବିଦ୍ୟାର୍ଥୀମାନଙ୍କ ସଠିକତା ବୃଦ୍ଧି ଦକ୍ଷତା ପ୍ରଭାବିତ ହେଉଥିବା ସାଧାରଣ ଗୁଣ ଜାଣିବା ପାଇଁ ଆମେ ଉଦ୍ୟମ କରିଥିବା ପ୍ରଶ୍ନ ଅନୁକ୍ରମ ନିରୂପଣ କରୁଛୁ । ଏହାର ଫଳପ୍ରଦ ସମାଧାନ କରିବା ଲାଗି, DKT (ଗଭୀର ଜ୍ଞାନ ଅନୁସନ୍ଧାନ) (LSTM) ବ୍ୟବହାର କରାଯାଇଥାଏ । ଏଥିରେ ବ୍ୟବହାରକାରୀଙ୍କ ପ୍ରୟାସ ତଥ୍ୟ ଓ ସଠିକତା ରହିଥାଏ, ଫଳରେ ଅନୁକ୍ରମ ବର୍ଗୀକରଣ ସମସ୍ୟା ଭାବେ କେଉଁ କନସେପ୍ଟ/ପ୍ରୟାସ ଶୈଳୀ ସଠିକତା ଉପରେ ଅଧିକ ପ୍ରଭାବ ପକାଇଥାଏ, ତାହା ଜଣାପଡେ । ଶେଷରେ ନୂତନ କନସେପ୍ଟ ପାଇବା ପାଇଁ ସମ୍ପର୍କ ରେଙ୍କିଙ୍ଗ୍ କରିବାକୁ ଦକ୍ଷ DKT ମଡେଲ୍ ବ୍ୟବହୃତ ହୋଇଥାଏ । ପରେ ଏହି ରେଙ୍କିଙ୍ଗ୍ ନଲେଜ୍ ଗ୍ରାଫ୍ ନୋଡ୍ ମଧ୍ୟରେ ନୂତନ ସମ୍ପର୍କ ପ୍ରସ୍ତାବ ଲାଗି ମଧ୍ୟ ବ୍ୟବହୃତ ହୋଇଥାଏ ।
ସାରାଂଶ:
ନଲେଜ୍ ଗ୍ରାଫ୍ ହେଉଛି ସମସ୍ତ Embibe ଉତ୍ପାଦଗୁଡ଼ିକର ମୂଳାଧାରା । ତେଣୁ ନଲେଜ୍ ଗ୍ରାଫ୍ ସମାପ୍ତ କରିବା ହେଉଛି ଆମର ପ୍ରାଥମିକ କାର୍ଯ୍ୟ । ଏହି କାର୍ଯ୍ୟ ଆମକୁ ନଲେଜ୍ ଗ୍ରାଫ୍ ବଜାୟ ରଖିବାରେ ସାହାଯ୍ୟ କରିଥାଏ ଏବଂ ସର୍ବନିମ୍ନ ମାନୁଆଲ୍ ହସ୍ତକ୍ଷେପ ସହିତ ଶୀଘ୍ର ବିସ୍ତାର କରିଥାଏ ।
ପରିଶେଷରେ, କନସେପ୍ଟ ମଧ୍ୟରେ ନୂଆ ଲୁକାୟିତ ସମ୍ପର୍କ ଅନୁସନ୍ଧାନ କରିବା ଆମ ପାଇଁ ଏକ ଖୋଲା ଆହ୍ୱାନ । ଆମେ ବିଭିନ୍ନ ଉତ୍ସରୁ ପ୍ରଦତ୍ତ ପାଠ୍ୟବସ୍ତୁରୁ କନସେପ୍ଟ ଖୋଜିବା ପ୍ରକ୍ରିୟାକୁ ସ୍ୱୟଂଚାଳିତ କରିଛୁ । ପରେ, ଏହି କୌଶଳ ବ୍ୟବହାର କରି ପୂର୍ବରୁ ଥିବା କନସେପ୍ଟ ସହିତ ଏହି ନୂଆ ଭାବେ ମିଳିଥିବା କନସେପ୍ଟଗୁଡ଼ିକର ସମ୍ପର୍କ ଆମେ ପାଇଥାଉ । ନଲେଜ୍ ଗ୍ରାଫ୍ ଭାଲିଡେସନ୍ ପାଇଁ ମଧ୍ୟ ଏହି ପଦ୍ଧତିକୁ ବିସ୍ତାର କରାଯାଇପାରେ ।
ସନ୍ଦର୍ଭ:
- Chris Piech, Jonathan Spencer, Jonathan Huang, Surya Ganguli, Mehran Sahami, Leonidas J. Guibas, andJascha Sohl-Dickstein. Deep knowledge tracing.CoRR, abs/1506.05908, 2015. http://arxiv.org/abs/1506.05908.
- K. Greff, R. K. Srivastava, J. Koutník, B. R. Steunebrink and J. Schmidhuber, “LSTM: A Search Space Odyssey,” in IEEE Transactions on Neural Networks and Learning Systems, vol. 28, no. 10, pp. 2222-2232, Oct. 2017, doi: 10.1109/TNNLS.2016.2582924.




















