
1PL ଆଇଟମ୍ ରେସପନ୍ସ ଥିଓରୀ ଦ୍ୱାରା ମାନକୀକୃତ ଟେଷ୍ଟରେ ବିଦ୍ୟାର୍ଥୀଙ୍କ ସ୍କୋର୍ର ପୂର୍ବାନୁମାନ
Embibeରେ, ଆମେ ବିଦ୍ୟାର୍ଥୀମାନଙ୍କୁ ଶିକ୍ଷଣ ତତ୍ତ୍ୱ, ଶିକ୍ଷା ଗବେଷଣାରୁ ପ୍ରସ୍ତୁତ ମଡେଲ୍ ଓ ସେମାନଙ୍କର ଅନ୍ତର୍ନିହିତ ଗୁଣକୁ ନେଇ ମାନକ ପରୀକ୍ଷାରେ ସେମାନଙ୍କର ସ୍କୋର୍କୁ ବଢାଇବାରେ ସାହାଯ୍ୟ କରୁ ।
ଆଇଟମ୍ ରେସପନ୍ସ ଥିଓରୀ[1, 2] ନାମକ ଏକ ବହୁଳ ବ୍ୟବହୃତ ମଡେଲ୍ ବିଦ୍ୟାର୍ଥୀମାନଙ୍କ ଦକ୍ଷତା କିମ୍ବା ଦକ୍ଷତା ସ୍ତର ତଥା ଉତ୍ତର ଦେବାକୁ ପ୍ରୟାସ କରାଯାଉଥିବା ପ୍ରଶ୍ନର କଠିନତା ସ୍ତର ଆକଳନ କରି ପ୍ରଶ୍ନର ସଠିକ୍ ଉତ୍ତର ଦେବାର ସମ୍ଭାବନାକୁ ପୂର୍ବାନୁମାନ କରେ । ଏହା ପ୍ରଥମେ 1960 ଦଶକରେ ପ୍ରସ୍ତାବ ଦିଆଯାଇଥିଲା ଏବଂ ଏହାର ଅନେକ ସ୍ୱରୂପ ରହିଛି, ଯେପରିକି 1PL ମଡେଲ୍[2, 3] ଏବଂ 2PL ମଡେଲ୍[2] ।
ଆଇଟମ୍ ରେସପନ୍ସ ଥିଓରୀର 1PL ମଡେଲ୍
ରାସ୍ ମଡେଲ[3] ଭାବରେ ଜଣାଶୁଣା 1PL ବା 1 ପାରାମିଟର ଆଇଟମ୍ ରେସପନ୍ସ ଥିଓରୀ ମଡେଲ୍ ନିମ୍ନରେ ଦିଆଯାଇଛି ।
ମନେକର i ହେଉଛନ୍ତି ଜଣେ ଶିକ୍ଷାର୍ଥୀ କିମ୍ବା ଛାତ୍ର, ଆଉ j ହେଉଛି ଏକ ପ୍ରଶ୍ନ । ମନେକର θi ହେଉଛି ଶିକ୍ଷାର୍ଥୀଙ୍କର ଦକ୍ଷତା ଏବଂ βj ହେଉଛି ପ୍ରଶ୍ନର କଠିନତା ସ୍ତର । ତେବେ 1PL ମଡେଲ ଅନୁଯାୟୀ, i ତମ ବ୍ୟବହାରକାରୀ jତମ ପ୍ରଶ୍ନର ସଠିକ୍ ଉତ୍ତର ଦେବାର ସମ୍ଭାବ୍ୟତା Pij ହେଉଛି logit(Pij) = i – j, ଯେଉଁଠାରେ logit ଫଳନ ହେଉଛି logit(x) =(1+(-x))-1 ।
1PL ଆଇଟମ୍ ରେସପନ୍ସ ଥିଓରୀ ମଡେଲ୍ ବ୍ୟବହାର କରି, ଶିକ୍ଷାର୍ଥୀଙ୍କର ଦକ୍ଷତା ସ୍ତର θi ପୂର୍ବାନୁମାନ କରିପାରିବା । ଉତ୍ତର ଦେବାକୁ ପ୍ରୟାସ କରୁଥିବା ପ୍ରତ୍ୟେକ ପ୍ରଶ୍ନରେ ଶିକ୍ଷାର୍ଥୀଙ୍କର ପ୍ରତିକ୍ରିୟା ବିଷୟରେ ତଥ୍ୟ ପ୍ରଦାନ ହୋଇଥିବ ।
1PL ଆଇଟମ୍ ରେସପନ୍ସ ଥିଓରୀ ପାଇଁ ଡିପ୍ ଲର୍ଣ୍ଣିଂ ଆର୍କିଟେକଚର୍
ଆମେ ଦେଖିପାରୁ ଯେ 1PL ମଡେଲ୍ ବାସ୍ତବରେ ଏକ ଡୋମେନ୍-ନିର୍ଦ୍ଦିଷ୍ଟ ପାରାମିଟରାଇଜେସନ୍ ସହିତ ଲଜିଷ୍ଟିକ୍ ରିଗ୍ରେସନ୍ ଅଟେ । ଫଳସ୍ୱରୂପ, ଆମେ ଯେକୌଣସି ଗଭୀର ଶିକ୍ଷଣ ଢାଂଞ୍ଚା ବ୍ୟବହାର କରି ଏହିପରି ଏକ ମଡେଲ୍ ହୃଦୟଙ୍ଗମ କରିପାରିବା । 1PL ମଡେଲ୍ ପାଇଁ ଗଭୀର ଶିକ୍ଷଣ ଆର୍କିଟେକଚର୍ ଚିତ୍ର 1 ରେ ଦର୍ଶାଯାଇଛି ।
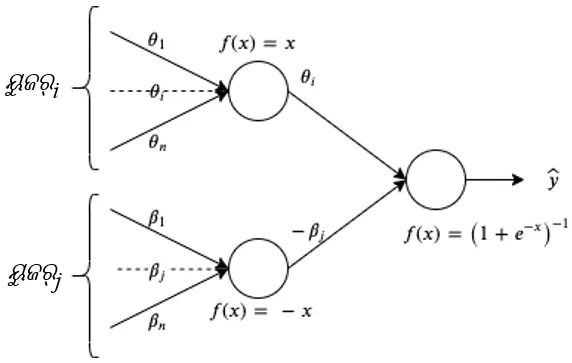
ଆମର ମଡେଲ୍ କେରାସ୍[4] ରେ ଏକ ଡିପ୍ ନ୍ୟୁରାଲ୍ ନେଟୱାର୍କ ଭାବରେ କାର୍ଯ୍ୟକାରୀ ହୋଇଛି । ଏକ ନ୍ୟୁରାଲ୍ ନେଟୱାର୍କ ଭାବରେ ସମସ୍ୟାକୁ ମଡେଲିଂ କରିବାର ସୁବିଧାଗୁଡ଼ିକ ହେଉଛି:
- ଇନପୁଟ୍ରେ ନଥିବା ମୂଲ୍ୟଗୁଡିକ ପରିଚାଳନା କରିବାର କ୍ଷମତା – ପ୍ରତ୍ୟେକ ୟୁଜର୍ ପ୍ରତ୍ୟେକ ପ୍ରଶ୍ନର ଉତ୍ତର ଦେବାପାଇଁ ପ୍ରୟାସ କରିବା ଆବଶ୍ୟକ ପଡେ ନାହିଁ ।
- ବହୁ ସଂଖ୍ୟକ ୟୁଜର୍ ଏବଂ ଆଇଟମ୍କୁ ସ୍କେଲ୍ କରିବାର କ୍ଷମତା
- ଅଧିକ ପାରାମିଟର ସହିତ ଢାଂଞ୍ଚାକୁ 2PL, 3PL ଏବଂ ଅନ୍ୟାନ୍ୟ ଆଇଟମ୍ ରେସପନ୍ସ ଥିଓରୀ ମଡେଲ୍ଗୁଡ଼ିକୁ ବିସ୍ତାର କରିବାର କ୍ଷମତା
ଆମେ ଏହି ମଡେଲ୍କୁ 1PL ଡିପ୍ ଆଇଟମ୍ ରେସପନ୍ସ ଥିଓରୀ ମଡେଲ୍ କହିଥାଉ ।
ଭାଲିଡେସନ୍
ମଡେଲିଂ କୌଶଳକୁ ବେଞ୍ଚମାର୍କ ଏବଂ ଭାଲିଡେସନ୍ କରିବାକୁ, ଆମେ ନିମ୍ନଲିଖିତ ଭାବରେ ସିମୁଲେଟେଡ୍ ଡାଟା ସୃଷ୍ଟି କରୁ :
- i N (0,1): ମାଧ୍ୟମାନ 0 ଏବଂ ମାନକ ବିଚ୍ୟୁତି 1 ସହିତ ନର୍ମାଲ୍ ଡିଷ୍ଟ୍ରିବ୍ୟୁସନ୍ ବ୍ୟବହାର କରି ଶିକ୍ଷାର୍ଥୀଙ୍କ ଦକ୍ଷତା ସୃଷ୍ଟି ହୁଏ ।
- j U (-1,1): ପ୍ରଶ୍ନ କଠିନତା ମୂଲ୍ୟଗୁଡ଼ିକ -1 ରୁ 1 ମଧ୍ୟରେ ସମାନ ଭାବରେ ସୃଷ୍ଟି ହୁଏ ।
- Pij = i – j: ୟୁଜର୍ଙ୍କ ଦକ୍ଷତା ଓ ଆଇଟମ୍ କଠିନତା (1PL ଆଇଟମ୍ ରେସପନ୍ସ ଥିଓରୀ ସମୀକରଣ ବ୍ୟବହାର କରି) ବ୍ୟବହାର କରି ସଠିକ୍ ପ୍ରତିକ୍ରିୟାଗୁଡ଼ିକର ସମ୍ଭାବ୍ୟତା ହିସାବ କରାଯାଏ ।
- yijk Bern (Pij): ସଫଳତା ସମ୍ଭାବ୍ୟତା Pij ବିଶିଷ୍ଟ ବର୍ନଉଲି ଡିଷ୍ଟ୍ରିବ୍ୟୁସନ୍ରୁ ବାଇନାରୀ ପ୍ରତିକ୍ରିୟା (ସଠିକ୍, ସଠିକ୍ ନୁହେଁ) ନମୁନା ସଂଗ୍ରହ କରାଯାଇଛି, ଯେଉଁଠାରେ ପ୍ରତ୍ୟେକ ଶିକ୍ଷାର୍ଥୀ ପ୍ରତି ପ୍ରତିକ୍ରିୟା ସଂଖ୍ୟା ବିନ୍ୟାସଯୋଗ୍ୟ ଅଟେ ।
ଆମେ 100 ଟି ପ୍ରଶ୍ନ, 100 ଶିକ୍ଷାର୍ଥୀ, ଏବଂ ପ୍ରତ୍ୟେକ ଶିକ୍ଷାର୍ଥୀ, ଗୋଟିଏ ପ୍ରଶ୍ନ ପାଇଁ ଜଣେ ଶିକ୍ଷାର୍ଥୀ ଓ ଗୋଟିଏ ପ୍ରତିକ୍ରିୟା ଅନୁକରଣ କରିଛୁ ।
ଆମେ 1PL ଡିପ୍ ଆଇଟମ୍ ରେସପନ୍ସ ଥିଓରୀ ମଡେଲ୍କୁ ସିମୁଲେଟେଡ୍ ଡାଟାସେଟରେ ଫିଟ୍ କରିଥାଉ । ନ୍ୟୁରାଲ୍ ନେଟୱାର୍କରେ ଇନପୁଟ୍ ଗୁଡିକ ହେଉଛି ୟୁଜର୍ ଭେକ୍ଟର (ୱାନ୍-ହଟ୍ ଏନକୋଡେଡ୍) ଏବଂ ପ୍ରଶ୍ନ ଭେକ୍ଟର (ୱାନ୍-ହଟ୍ ଏନକୋଡେଡ୍), ଏବଂ ଆଉଟପୁଟ୍ ହେଉଛି ଆଇଟମ୍ ରେସପନ୍ସ ଥିଓରୀ ମଡେଲ୍ର ପାରାମିଟର, ଆଇଟମ୍ କଠିନତା, ଶିକ୍ଷାର୍ଥୀଙ୍କ ଦକ୍ଷତା ଏବଂ ଶିକ୍ଷାର୍ଥୀ ସଠିକ୍ ଉତ୍ତର ଦେବେ କି ନାହିଁ, ତାହାର ପୂର୍ବାନୁମାନ । ନ୍ୟୁରାଲ୍ ନେଟୱାର୍କ ସଂପୂର୍ଣ୍ଣ ସଂଯୁକ୍ତ ହୋଇଥାଏ । ଏଥିରେ ଦୁଇଟି ଇନପୁଟ୍ ସ୍ତର, କଠିନତା ଏବଂ ଦକ୍ଷତା ପାଇଁ ମଧ୍ୟବର୍ତ୍ତୀ ସ୍ତର ଏବଂ ପୂର୍ବାନୁମାନ ପାଇଁ ଗୋଟିଏ ଆଉଟପୁଟ୍ ସ୍ତର ଅଛି ।
ଆମେ ନ୍ୟୁରାଲ୍ ନେଟୱାର୍କରୁ 1PL ଡିପ୍ ଆଇଟମ୍ ରେସପନ୍ସ ଥିଓରୀ ଆଉଟପୁଟ୍ ସହିତ ସିମୁଲେଟେଡ୍ ତଥ୍ୟର ପ୍ରକୃତ ଆଉଟପୁଟ୍ ସହିତ ତୁଳନା କରୁ ।
କାର୍ଯ୍ୟକାରିତା
ମଡେଲ୍: 1PL ଆଇଟମ୍ ରେସପନ୍ସ ଥିଓରୀର ସଂରଚନାକୁ କେରାସ୍ ଫଙ୍କସନାଲ୍ API ବ୍ୟବହାର କରି NNs ର ରଚନାତ୍ମକତାକୁ କାର୍ଯ୍ୟରେ ଲଗାଇ ବ୍ୟାଖ୍ୟା କରାଯାଇଛି । ସାମଗ୍ରିକ ମଡେଲ୍ଟି ଘନ ସ୍ତରଗୁଡିକୁ ଷ୍ଟାକିଂ କରି ଗଠନ କରାଯାଇଛି – ଏଠାରେ 1PL ମଡେଲ୍ ପାଇଁ 2 ଟି ଘନ ସ୍ତର ରହିଛି, ପ୍ରତ୍ୟେକ ଏକ ୟୁଜର୍ କିମ୍ବା ଆଇଟମ୍ ପାରାମିଟରଗୁଡିକୁ ଦର୍ଶାଇଥାନ୍ତି, ଯାହା ଆଇଟମ୍ (j) ସମ୍ପର୍କିତ ୟୁଜର୍ (i)ର ଡ୍ରାଇଭିଂ ସମ୍ଭାବନା (Pij)ରେ ବେଶ୍ ଗୁରୁତ୍ୱପୂର୍ଣ୍ଣ ।
ହାଇପର ପାରାମିଟର: ପ୍ରତ୍ୟେକ ଘନ ସ୍ତରରେ ନିମ୍ନଲିଖିତ ଡିଫଲ୍ଟ ସେଟିଂ ସମୂହ ବ୍ୟବହୃତ ହୁଏ
- କର୍ନେଲ୍ ଓ ବାୟସ୍ ଇନିସିଆଲାଇଜର୍: ନର୍ମାଲ (0,1)
- l1/l2 ରେଗୁଲାରାଇଜେସନସ୍ : l_1=0, l_2=0
- ଆକ୍ଟିଭିଟି ରେଗୁଲାରାଇଜର୍ : l_1=0, l_2=0
ଏକ ଡେଭଲପର୍ ଦ୍ୱାରା ଉପରୋକ୍ତ ସେଟିଂ ସମୂହକୁ ଓଭରରାଇଡ୍ କରାଯାଇପାରେ କିମ୍ବା ଅନେକ କନଫିଗ୍ୟୁରେସନ୍ ମଧ୍ୟରୁ ଖୋଜି ଏକ ସର୍ବୋତ୍ତମ କନଫିଗ୍ୟୁରେସନ୍ ଅଣାଯାଇପାରେ । ଏହିପରି ବିବରଣୀଗୁଡିକ ନେଇ ଆଗକୁ ଏକ ବ୍ଲଗ୍ ପ୍ରସ୍ତୁତ ହେବ । ପରିଭାଷିତ ମଡେଲ୍ ଭେଦଭାବ, ଅନୁମାନ ଓ ବାରମ୍ବାର ପୁନରାବଲୋକନ ଭଳି ଦୁଇ କିମ୍ବା ତିନୋଟି ମାନଦଣ୍ଡ ପାଇଁ ଏହାର ବ୍ୟବହାରକୁ ବିସ୍ତାର କରିବାକୁ ଯଥେଷ୍ଟ ଅନୁକୂଳନୀୟ । ଏହା ହେଉଛି ଏକ ବିସ୍ତାରିତ ମଡେଲ୍ ଯାହା ନ୍ୟୁରାଲ୍ ଆର୍କିଟେକଚର୍ ସର୍ଚ୍ଚ କ୍ଷମତା ବିଶିଷ୍ଟ ଏକ କିମ୍ବା ଦୁଇ PL ମଡେଲ୍ ଭାବରେ କାର୍ଯ୍ୟ କରିବାକୁ ବାଧ୍ୟ ହୋଇପାରେ ।
ପ୍ରୟୋଗାତ୍ମକ ପରିଣାମ
ନିମ୍ନ ଚିତ୍ରଗୁଡିକ ତଳେ ଦିଆଯାଇଥିବା ସମ୍ପର୍କକୁ ସୂଚାଇଥାନ୍ତି:
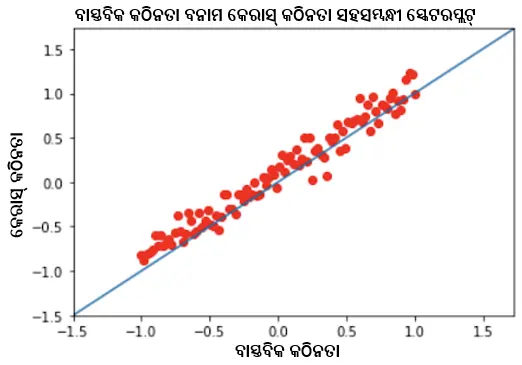
- ପିଅରସନ୍ ସହସମ୍ବନ୍ଧ ଗୁଣାଙ୍କ 0.9857 ସହିତ ପୂର୍ବାନୁମାନ କଠିନତା ବନାମ ବାସ୍ତବିକ କଠିନତା ।
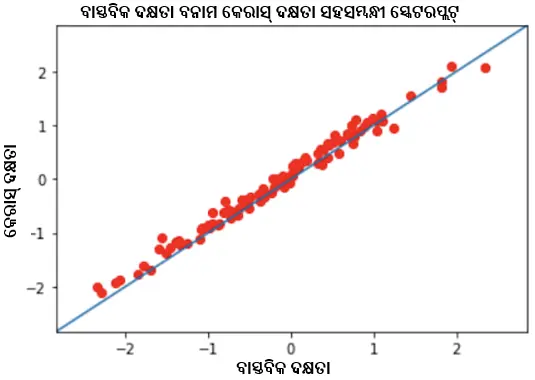
- ପିଅରସନ୍ ସହସମ୍ବନ୍ଧ ଗୁଣାଙ୍କ 0.9954 ସହିତ ପୂର୍ବାନୁମାନ ଦକ୍ଷତା ବନାମ ବାସ୍ତବିକ କ୍ଷମତା ସ୍ତର ।
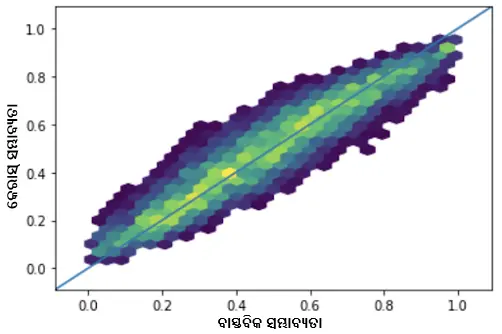
- ପିଅରସନ୍ ସହସମ୍ବନ୍ଧ ଗୁଣାଙ୍କ 0.9926 ସହିତ ସମସ୍ତ ପ୍ରଶ୍ନର ସଠିକ୍ ଉତ୍ତର ଦେବାର ପୂର୍ବାନୁମାନ ସମ୍ଭାବ୍ୟତା ବନାମ ବାସ୍ତବିକ ସମ୍ଭାବ୍ୟତା ।
1PL ଡାଟା ଉପରେ ଦକ୍ଷ ଡିପ୍ ଆଇଟମ୍ ରେସପନ୍ସ ଥିଓରୀ ମଡେଲରୁ, 1PL DIRT ମଡେଲ୍ରୁ ଲଗ୍ ସମ୍ଭାବନା ହେଉଛି 0.587 ।
ତିନୋଟି କ୍ଷେତ୍ରରେ ଭଲ ସହସମ୍ବନ୍ଧ ଥିବା ଆମେ ଦେଖିଲେ । ଏହା ସୂଚାଇଥାଏ ଯେ ଆମର 1PL ଡିପ୍ ଆଇଟମ୍ ରେସପନ୍ସ ଥିଓରୀ ମଡେଲ୍ ସଠିକ୍ ଭାବେ କଠିନତା, ଦକ୍ଷତା ଓ ଟେଷ୍ଟ ସ୍କୋର୍ ପୂର୍ବାନୁମାନ କରିବାରେ ସକ୍ଷମ ହେଉଛି ।
ନିଷ୍କର୍ଷ
ଆମେ ଦେଖାଇଛୁ ଯେ, ଅନୁକରଣ ଆଧାରରେ 1PL ଆଇଟମ୍ ରେସପନ୍ସ ଥିଓରୀ ମଡେଲ୍ ଡିପ୍ ଲର୍ଣ୍ଣିଂ ମଡେଲ୍ ମାଧ୍ୟମରେ କାର୍ଯ୍ୟକାରୀ ହୋଇପାରିବ । ଆଇଟମ୍ ରେସପନ୍ସ ଥିଓରୀ ପାରାମିଟର ସହାୟତାରେ ଆମେ ଆମର 1PL ଆଇଟମ୍ ରେସପନ୍ସ ଥିଓରୀ ଆଧାରିତ ମଡେଲ୍ ବ୍ୟବହାର କରି ଶିକ୍ଷାର୍ଥୀମାନଙ୍କ ଦକ୍ଷତା ଓ ପ୍ରଶ୍ନଗୁଡ଼ିକର କଠିନତା ସ୍ତରକୁ ଭଲ ଭାବେ ଆକଳନ କରିପାରିବା । ଏହି ଆକଳନ ଆଡାପ୍ଟିଭ୍ ଟେଷ୍ଟ, ଲକ୍ଷ୍ୟ ସେଟିଂ ଓ ଅନ୍ୟାନ୍ୟ ଡାଉନଷ୍ଟ୍ରିମ୍ ସମସ୍ୟା ସୃଷ୍ଟି କରିବାରେ ବ୍ୟବହୃତ ହୋଇପାରେ ।
ସନ୍ଦର୍ଭ
- Frank B. Baker. “The basics of item response theory.” ERIC, USA, 2001
- Wikipedia. Item Response Theory https://en.wikipedia.org/wiki/Item_response_theory
- Georg Rasch. “Studies in mathematical psychology: I. Probabilistic models for some intelligence and attainment tests.” 1960.
- Keras Deep Learning framework: Keras




















