
ଆବଶ୍ୟକ ଜଟିଳ ପ୍ରଶ୍ନର ସ୍ୱତଃ ପ୍ରସ୍ତୁତି
Embibe କହିଲେ ଶିକ୍ଷାର ବ୍ୟକ୍ତିଗତକରଣକୁ ବୁଝାଏ ଏବଂ ଆମର ଟେକ୍ନୋଲୋଜି ସଠିକ୍ କଣ୍ଟେଣ୍ଟ୍, ସଠିକ୍ ବିଦ୍ୟାର୍ଥୀ, ସଠିକ୍ ସମୟରେ ସେବା କରିବାରେ ସକ୍ଷମ । ଏହି କାରଣରୁ ଉପଯୋଗୀ ବିଷୟବସ୍ତୁର ଏକ ବଡ଼ ଡାଟାସେଟକୁ ଉପଲବ୍ଧ କରିବା ଏବଂ ବିଶେଷକରି ପ୍ରଶ୍ନଗୁଡ଼ିକ ଆମ ପାଇଁ ଅତ୍ୟନ୍ତ ଗୁରୁତ୍ୱପୂର୍ଣ୍ଣ । ଡାଟା ଏଣ୍ଟ୍ରି ଅପରେଟରମାନଙ୍କ ଦ୍ୱାରା ପ୍ରଶ୍ନଗୁଡିକର ଡାଟାବେସ୍ ପ୍ରସ୍ତୁତ କରାଯାଇଥିଲା । ସେମାନେ ଇଣ୍ଟରନେଟ୍ ରେ ନିଃଶୁଳ୍କରେ ଉପଲବ୍ଧ ପ୍ରଶ୍ନ ସେଟରୁ କିମ୍ବା ଆମର ସହଭାଗୀ ଅନୁଷ୍ଠାନଗୁଡ଼ିକ ସହିତ ଟାଇ-ଅପ୍ ମାଧ୍ୟମରେ ପ୍ରଶ୍ନ ଉତ୍ସରୁ ପ୍ରଶ୍ନ ସଂଗ୍ରହ କରିଥାନ୍ତି ।
ପ୍ରଶ୍ନର ଅଟୋ-ଜେନେରେସନ୍ର ମୂଳ ପ୍ରେରଣା ହେଉଛି ଶିକ୍ଷକ/ପରାମର୍ଶଦାତାଙ୍କ ଉପରେ ବିଦ୍ୟାର୍ଥୀମାନଙ୍କ ନିର୍ଭରଶୀଳତାକୁ କମାଇବା । ଲକ୍ଷ ଲକ୍ଷ ବିଦ୍ୟାର୍ଥୀଙ୍କ ପାଇଁ ପ୍ରକୃତ ଅର୍ଥରେ ଶିକ୍ଷାକୁ ପହଂଚାଇବାକୁ ହେଲେ ସେମାନେ କୌଣସି ବାହ୍ୟ ସାହାଯ୍ୟ ବିନା ନିଜେ ନିଜେ କନସେପ୍ଟ/ଟପିକ୍ ପ୍ରାକ୍ଟିସ୍ କରିବାକୁ ସମର୍ଥ ହେବା ଉଚିତ୍ । ଅସୀମିତ ପ୍ରଶ୍ନଗୁଡିକର ଉପଲବ୍ଧତା ବୁଦ୍ଧିମାନ ମୂଲ୍ୟାୟନ ପ୍ରସ୍ତୁତି [3], ବିଦ୍ୟାର୍ଥୀମାନଙ୍କର ପାଇଁ ସମାଧାନ[4] କିମ୍ବା ଲର୍ଣ୍ଣିଂ ଆଉଟକମ୍ ପ୍ରଦାନ କରିବାକୁ ବ୍ୟକ୍ତିଗତ ବିଷୟବସ୍ତୁ ଦେବା ଲାଗି ସକ୍ଷମ କରିଥାଏ [5][6] । ପ୍ରଶ୍ନଗୁଡିକର ଅଟୋ-ଜେନେରେସନ୍ ଏବଂ ବିଦ୍ୟାର୍ଥୀମାନଙ୍କୁ ପ୍ରାକ୍ଟିସ୍ ଓ ସେମାନଙ୍କର ଅଗ୍ରଗତିର ମୂଲ୍ୟାଙ୍କନ କରିବାକୁ ଅନୁମତି ଦେବା ସେହି ଦିଗରେ ଏକ ପଦକ୍ଷେପ ।
ତେବେ, ସୁନିଶ୍ଚିତ କରିବାକୁ ଯେ ଆମ ପ୍ଲାଟଫର୍ମରେ ବିଦ୍ୟାର୍ଥୀମାନେ ଯେଉଁ ବିଷୟରେ ଅଧିକ ପଢିବା ପାଇଁ ଚାହୁଁଛନ୍ତି, ସେ ସମ୍ପର୍କିତ ପ୍ରଶ୍ନ ଯେମିତି ଅଭାବ ନ ପଡେ, AI ବିକାଶ ଦିଗରେ Embibe ମନଯୋଗ ଦେଇଛି, ଯାହା ସ୍ୱୟଂଚାଳିତ ଭାବରେ ନୂତନ ପ୍ରଶ୍ନ ଏବଂ ସେମାନଙ୍କର ଉତ୍ତର ପ୍ରସ୍ତୁତ କରିପାରିବେ । ଏହି କାର୍ଯ୍ୟରେ ବିଷୟବସ୍ତୁ କ୍ଲଷ୍ଟରିଂ, ବିଷୟ ମଡେଲିଂ, ଅଗ୍ରଣୀ ପ୍ରାକୃତିକ ଭାଷା ସୃଷ୍ଟି (NLG) ଏବଂ ସଲଭର୍ ଟେକ୍ନୋଲୋଜିରୁ କନସେପ୍ଟ ଆଦି ଆଣିବା ଅନ୍ତର୍ଭୁକ୍ତ ।
ଉଦ୍ଦେଶ୍ୟ
ଆମେ, Embibeରେ, ପ୍ରଶ୍ନଗୁଡିକର ଉତ୍ତର ଦେଇ ପ୍ରାକ୍ଟିସ୍ ଏବଂ କନସେପ୍ଟ ମାଧ୍ୟମରେ ଶିକ୍ଷଣର ଏକ ଢାଂଚା ପ୍ରସ୍ତାବ ଦେଇଥାଉ ଯାହା କନସେପ୍ଟଗୁଡ଼ିକୁ ମନେ ରଖିବା ଏବଂ ବୁଝିବା ପାଇଁ ଏକ ପରୋକ୍ଷ ଉପାୟ । ସ୍ୱୟଂଚାଳିତ ପ୍ରଶ୍ନ ଜେନେରେସନ୍ ହେଉଛି ଏକ ପ୍ରକ୍ରିୟା ଯାହା ଶିକ୍ଷଣ ପାଠ୍ୟକୁ ଏକ ଇନପୁଟ୍ ଭାବରେ ନେଇଥାଏ ଏବଂ ଏଥିରୁ ପ୍ରଶ୍ନ ସୃଷ୍ଟି କରିଥାଏ ଯେଉଁଥିରେ ବିଦ୍ୟାର୍ଥୀମାନେ ପ୍ରାକ୍ଟିସ୍ ଏବଂ ଲର୍ଣ୍ଣ ପାଇଁ ସେମାନଙ୍କର ଜ୍ଞାନକୁ ପ୍ରୟୋଗ କରିପାରିବେ ।
ସ୍ୱୟଂଚାଳିତ ପ୍ରଶ୍ନ ପ୍ରସ୍ତୁତି ପ୍ରାକୃତିକ ଭାଷା ପ୍ରକ୍ରିୟାକରଣ (NLP)ର ଏକ ଅଂଶ । ଏହା ଏକ ଅନୁସନ୍ଧାନର କ୍ଷେତ୍ର ଯେଉଁଠାରେ ଅନେକ ଗବେଷକ ସେମାନଙ୍କର କାର୍ଯ୍ୟ ଉପସ୍ଥାପନ କରିଛନ୍ତି । ଏହା ଏପର୍ଯ୍ୟନ୍ତ ସର୍ବାଧିକ ସଠିକତା ହାସଲ କରିବାର ଅପେକ୍ଷାରେ ରହିଛି । ଅନେକ ଗବେଷକ NLP ମାଧ୍ୟମରେ ସ୍ୱୟଂଚାଳିତ ପ୍ରଶ୍ନ ପ୍ରସ୍ତୁତି କ୍ଷେତ୍ରରେ କାର୍ଯ୍ୟ କରିଛନ୍ତି ଏବଂ ବିଭିନ୍ନ ପ୍ରକାରର ପ୍ରଶ୍ନ ସ୍ୱୟଂଚାଳିତ ଭାବରେ ସୃଷ୍ଟି କରିବା ପାଇଁ ଅନେକ କୌଶଳ ଓ ମଡେଲ୍ ବିକଶିତ କରିଛନ୍ତି ।
ପଦ୍ଧତି
ଚିତ୍ର 1 ରେ ଦେଖାଯାଇଥିବା ଚିତ୍ର, ସ୍ଵତଃ ପ୍ରଶ୍ନ ପ୍ରସ୍ତୁତିର ଢାଂଚା ପାଇଁ ଏକ ଉଚ୍ଚସ୍ତରୀୟ ପଦ୍ଧତିକୁ ଦର୍ଶାଇଥାଏ । ସ୍ଵତଃ ପ୍ରଶ୍ନ ପ୍ରସ୍ତୁତି NLP କୌଶଳ ସହିତ ଟ୍ରାନ୍ସଫର୍ମର ମଡେଲଗୁଡିକର ଉନ୍ନତ ଭାରିଆଣ୍ଟ ବ୍ୟବହାର କରିଥାଏ । ଏହା ମଧ୍ୟ ସୃଷ୍ଟି ହୋଇଥିବା ପ୍ରଶ୍ନଗୁଡ଼ିକର ଗୁଣବତ୍ତା ଏବଂ ଜଟିଳତାକୁ ବଢାଇବା ପାଇଁ ପାଠ୍ୟର ବାକ୍ୟ ବିନ୍ୟାସଗତ ଓ ଅର୍ଥଗତ ବୋଧଗମ୍ୟତା ଉପରେ କରାଯାଉଥିବା ଅନୁସନ୍ଧାନ କାର୍ଯ୍ୟକୁ ବ୍ୟବହାର କରିଥାଏ ।
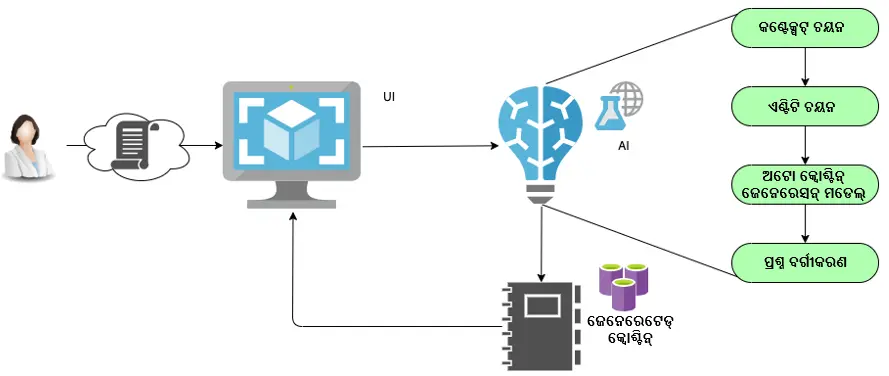
ସ୍ୱୟଂଚାଳିତ ପ୍ରଶ୍ନ ପ୍ରସ୍ତୁତିରେ ପାଠ୍ୟ ପ୍ରକ୍ରିୟାକରଣ, ବୈଶିଷ୍ଟ୍ୟ ନିଷ୍କର୍ଷ, ଇଞ୍ଜିନିୟରିଂ, ମଡେଲ୍ ବିଲଡିଂ ଓ ଟ୍ରେନିଂ, ମଡେଲ୍ ମୂଲ୍ୟାଙ୍କନ, ଟିପ୍ପଣୀ ଏବଂ କିଛି ମାନକ ML ଟେକନିକ୍ ପରି ଅନେକ ଉପାଦାନ ଅନ୍ତର୍ଭୁକ୍ତ ଥାଏ ।
ଆମର QA ମଡେଲ୍କୁ ଦକ୍ଷ କରିବା ପାଇଁ ଆମେ 20+ ବିଭିନ୍ନ ଓପନ୍-ସୋର୍ସ ଡାଟାସେଟ୍ ବ୍ୟବହାର କରିଛୁ ଯେପରିକି ARC, DROP, QASC, SciQ, SciTail, SQuAD ଏବଂ Google NQ ଏବଂ Embibeର ନିଜସ୍ୱ ଡାଟାସେଟ୍ । ଆମେ ବିଭିନ୍ନ ପ୍ରକାରର ପ୍ରଶ୍ନ ମଧ୍ୟ ବ୍ୟବହାର କରିଛୁ ଯେପରିକି ବୁଲିୟାନ୍, ସ୍ପାନ୍-ଆଧାରିତ, ଶୂନ୍ୟ ସ୍ଥାନ ପୂରଣ, ବହୁ ବିକଳ୍ପ ପ୍ରଶ୍ନ ଇତ୍ୟାଦି । ପ୍ରଶ୍ନର ଜଟିଳତା ପ୍ରଶ୍ନର ବାକ୍ୟ ବିନ୍ୟାସ ଗଠନ, ଉତ୍ତର ପାଇବା ପାଇଁ ମଲ୍ଟି-ହପ୍ ରେଜନିଂ ଏବଂ ପ୍ରମୁଖ କନସେପ୍ଟଗୁଡିକର ଜଟିଳତା ଆଧାରରେ ନିରୂପଣ କରାଯାଇଥାଏ । KI-BERT ଦ୍ୱାରା ପ୍ରେରିତ ହୋଇ QG ମଡେଲ୍ଗୁଡ଼ିକରେ ପ୍ରଯୁଜ୍ୟ ଜ୍ଞାନକୁ ସନ୍ନିହିତ କରିବା ପାଇଁ ଆମେ ନଲେଜ୍ ଗ୍ରାଫ୍ ମଧ୍ୟ ବ୍ୟବହାର କରୁଛୁ[1] । ପ୍ରଶ୍ନ ସୃଷ୍ଟିର କାର୍ଯ୍ୟଦକ୍ଷତାକୁ ଉନ୍ନତ କରିବା ପାଇଁ ଆମେ ସ୍ୱାଭାବିକ ଭାବରେ ନିର୍ମିତ ପ୍ରାକୃତିକ ଭାଷା ବୋଧ କୌଶଳ (Natural Language Understanding techniques)କୁ ଉପଯୋଗ କରୁ ।
ଟେକ୍ସଟ୍ ସୃଷ୍ଟି କରିବା ପାଇଁ ଆମେ T5 [2] ପରି ଜେନେରେଟିଭ୍ ମଡେଲ୍ ବ୍ୟବହାର କରିପାରିବା, ଯାହା ଏକ ନିର୍ଦ୍ଦିଷ୍ଟ ପ୍ରସଙ୍ଗ ଏବଂ ଉତ୍ତରରୁ ପ୍ରଶ୍ନ ପ୍ରସ୍ତୁତ କରିପାରିବ । ଏହି ପ୍ରକ୍ରିୟା କିପରି ହେବ, ତାହା ଏଠାରେ ଦିଆଯାଇଛି ।
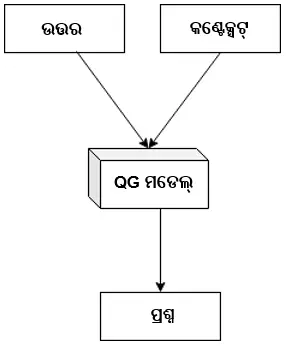
ଫଳାଫଳ
ପାଠ୍ୟପୁସ୍ତକରୁ ବିଦ୍ୟାର୍ଥୀମାନଙ୍କ ପାଇଁ ଯଥାସମ୍ଭବ ପ୍ରଶ୍ନ ସୃଷ୍ଟି କରିବା ପାଇଁ Embibe AI ପ୍ଲାଟଫର୍ମ ଏହି କାର୍ଯ୍ୟକୁ ବ୍ୟବହାର କରିଥାଏ । ସମସ୍ତ ଗ୍ରେଡ୍, ଲକ୍ଷ୍ୟ, ପରୀକ୍ଷା, ରାଜ୍ୟ ବୋର୍ଡକୁ ବିଚାରକୁ ନେଇ, ବର୍ତ୍ତମାନ ପର୍ଯ୍ୟନ୍ତ ଆମେ 6 ରୁ 12 ଗ୍ରେଡ୍ ର NCERT ବହିରୁ ~125k ପ୍ରଶ୍ନ ସୃଷ୍ଟି କରିଛୁ ।
ବାସ୍ତବ ଜଗତ ପରିସ୍ଥିତିରେ ଜୀବନ ଓ ଲର୍ଣ୍ଣିଂ ଆଉଟକମ୍ ହାସଲ କରିବାକୁ ଏହି ସିଷ୍ଟମକୁ ଯେ କୌଣସି ଡୋମେନରେ ବ୍ୟବହାର କରାଯାଇପାରିବ । ଉନ୍ନତ NLP କ୍ଷେତ୍ରରେ ମଡେଲ୍ ଓ ସିଷ୍ଟମକୁ ଅଧିକ ଅତ୍ୟାଧୁନିକ କରିବା ଏବଂ ଏହାକୁ ଡୋମେନ୍ ନିର୍ଦ୍ଦିଷ୍ଟ କରିବା ପାଇଁ ଆମେ ପ୍ରୟାସରତ ।
ଏଠାରେ, ଆମେ ଦିଆଯାଇଥିବା ଡୋମେନ୍ ନିର୍ଦ୍ଦିଷ୍ଟ ଇନପୁଟ୍ ଏବଂ ପ୍ରସ୍ତୁତ ପ୍ରଶ୍ନଗୁଡ଼ିକର ସେଟ୍ ର କିଛି ଉଦାହରଣ ପ୍ରଦାନ କରିଛୁ ।
ଏକାଡେମିକ୍ ଟେକ୍ସଟ୍:

ପ୍ରସ୍ତୁତ ପ୍ରଶ୍ନ:
ସନ୍ଦର୍ଭ




















