
ପର୍ସନାଲାଇଜଡ୍ ସର୍ଚ୍ଚ ପାଇଁ ଲର୍ଣ୍ଣିଂ-ଟୁ-ରାଙ୍କ୍
Embibe ଶିକ୍ଷାର୍ଥୀମାନଙ୍କୁ ସେମାନଙ୍କର ଲର୍ଣ୍ଣିଂ ଆଉଟକମ୍କୁ ଉନ୍ନତ କରିବାରେ ସାହାଯ୍ୟ କରେ ଏବଂ ମେନୁ ଚାଳିତ ନାଭିଗେସନ୍ ସିଷ୍ଟମ୍ ପରିବର୍ତ୍ତେ Embibeର ବ୍ୟକ୍ତିଗତ ସର୍ଚ୍ଚ ଇଞ୍ଜିନ୍ ବ୍ୟବହାର କରି ସେମାନେ ଆବଶ୍ୟକ କରୁଥିବା ବିଷୟବସ୍ତୁ ଖୋଜିବାର ଏହା ହେଉଛି ମୁଖ୍ୟ ମାଧ୍ୟମ । ୱେବ୍ ସର୍ଚ୍ଚର ବିକାଶ ଯୋଗୁଁ ବ୍ୟବହାରକାରୀମାନେ ଆଜି ଖୋଜୁଥିବା ଫଳାଫଳର ସଠିକ୍ ପୃଷ୍ଠା ପାଇବାକୁ ଆଶା ରଖିଥାନ୍ତି ।
Embibeରେ ଥିବା ବିଷୟବସ୍ତୁର ପରିମାଣ ଏକ ବିରାଟ ଭଣ୍ଡାର ଏବଂ ଏଥିରେ ଅଧ୍ୟୟନ ସାମଗ୍ରୀ, ଭିଡିଓ, ପ୍ରାକ୍ଟିସ୍ ପ୍ରଶ୍ନ, ଟେଷ୍ଟ, ଆର୍ଟିକିଲ୍ ଏବଂ ସମ୍ବାଦ ଆଇଟମ୍, ପରୀକ୍ଷା, ବିଷୟ, ୟୁନିଟ୍, ଅଧ୍ୟାୟ, କନସେପ୍ଟ ଆଦି ଅନ୍ତର୍ଭୁକ୍ତ । ୟୁଜର୍ମାନଙ୍କୁ ଯଥାସମ୍ଭବ କାର୍ଯ୍ୟକ୍ଷମ ବିଷୟବସ୍ତୁକୁ ଦର୍ଶାଇବାକୁ ସର୍ଚ୍ଚ ଫଳାଫଳଗୁଡିକ ୱିଜେଟ୍ ସେଟ୍ ଆକାରରେ ଉପସ୍ଥାପିତ ହୁଏ । ପ୍ରତ୍ୟେକ ୱିଜେଟ୍ ସର୍ଚ୍ଚ ଫଳାଫଳରୁ ପ୍ରାପ୍ତ ଫଳାଫଳଗୁଡିକର ସମ୍ପୃକ୍ତ କ୍ରିୟାଶୀଳ ଲିଙ୍କ୍ ଏବଂ ସମ୍ପୃକ୍ତ ନଲେଜ୍ ଗ୍ରାଫ୍ ନୋଡ୍ ଦ୍ୱାରା ଏକତ୍ରିତ ହୋଇଥିବା ଏକ ସଂଗ୍ରହକୁ ଦର୍ଶାଇଥାଏ । Embibe ରେ ଥିବା ସମସ୍ତ ବିଷୟବସ୍ତୁ ସହ ଜଡିତ ବିଭିନ୍ନ ୱିଜେଟ୍ ପ୍ରକାର ଅଛି ଏବଂ ଏହା ସହିତ ରହିଛି କୋହୋର୍ଟ୍-ଲେଭଲ୍ ୟୁଜର୍ ବୈଶିଷ୍ଟ୍ୟ । ଏହା ଆମ ସର୍ଚ୍ଚ ସ୍ପେସ୍କୁ ~120 ମିଲିୟନ୍ ଡକ୍ୟୁମେଣ୍ଟର ମିଶ୍ରଣ ପ୍ରଦାନ କରିଥାଏ, ୟୁଜର୍ ପାଖକୁ ଯିବା ପୂର୍ବରୁ ଏଥିରୁ ଚୟନ ହୋଇ ରାଙ୍କ୍ ହୋଇଥାଏ । Embibe ରେ ସର୍ଚ୍ଚ ଫଳାଫଳର ୟୁଜରମାନଙ୍କ ପୂର୍ବ ପାରସ୍ପରିକ କାର୍ଯ୍ୟର ଟ୍ରେଣ୍ଡ ବିଶ୍ଳେଷଣ ଦର୍ଶାଏ ଯେ ୟୁଜର୍ମାନେ ପ୍ରଥମ ପୃଷ୍ଠାର ଟପ୍ ୱିଜେଟ୍ ସ୍ଥାନରେ ହିଁ ସର୍ବାଧିକ ପ୍ରାସଙ୍ଗିକ ସୂଚନା ଆଶା କରନ୍ତି । ତେଣୁ, ଆମର ୟୁଜର୍ମାନଙ୍କ ପାଇଁ ସର୍ଚ୍ଚ ବ୍ୟବସ୍ଥାକୁ ଅଧିକ ଆକର୍ଷିତ କରିବାରେ ଏବଂ ଆମର ସନ୍ଧାନ ଫଳାଫଳର ମାନରେ ଉନ୍ନତି ଆଣିବାରେ ଫଳାଫଳ ୱିଜେଟ୍ ଗୁଡ଼ିକର କ୍ରମ ଏକ ଗୁରୁତ୍ୱପୂର୍ଣ୍ଣ ଭୂମିକା ଗ୍ରହଣ କରିଥାଏ ।
ଲର୍ଣ୍ଣିଂ-ଟୁ-ରାଙ୍କ୍ [1] ହେଉଛି ଏକ ତଦାରଖକାରୀ ମେସିନ୍ ଲର୍ଣ୍ଣିଂ ସମସ୍ୟା ଯାହା ସର୍ଚ୍ଚ ଫଳାଫଳ ପାଇଁ ସ୍ୱୟଂଚାଳିତ ଭାବରେ ଏକ ରାଙ୍କିଙ୍ଗ୍ ମଡେଲ୍ ଗଠନରେ ବ୍ୟବହୃତ ହୋଇପାରିବ । ପ୍ରତ୍ୟେକ ପ୍ରଶ୍ନ ପାଇଁ, ସମସ୍ତ ସଂପୃକ୍ତ ଡକ୍ୟୁମେଣ୍ଟଗୁଡ଼ିକ ସଂଗୃହିତ । ଏହି ଡକ୍ୟୁମେଣ୍ଟଗୁଡିକର ପ୍ରାସଙ୍ଗିକତା ସାଧାରଣତଃ ମାନବ ମୂଲ୍ୟାୟନ କିମ୍ବା ବିଚାର ଆକାରରେ ଟ୍ରେନିଂ ଡାଟା ଭାବରେ ପ୍ରଦାନ କରାଯାଇଥାଏ । ତା’ପରେ ଏହି ଡକ୍ୟୁମେଣ୍ଟ ପ୍ରାସଙ୍ଗିକତା ସମସ୍ତ ପ୍ରଶ୍ନ ଉପରେ ହାରାହାରି ରାଙ୍କିଙ୍ଗ୍ ଫଳାଫଳ ଏବଂ ପ୍ରାସଙ୍ଗିକତା ବିଚାର ମଧ୍ୟରେ ପାର୍ଥକ୍ୟକୁ କମ୍ କରିବାର ଏକ ଅପ୍ଟିମାଇଜେସନ୍ ଲକ୍ଷ୍ୟ ସହିତ ଲର୍ଣ୍ଣିଂ-ଟୁ-ରାଙ୍କ୍ ମଡେଲକୁ ଦକ୍ଷ କରିବା ପାଇଁ ବ୍ୟବହୃତ ହୁଏ ।
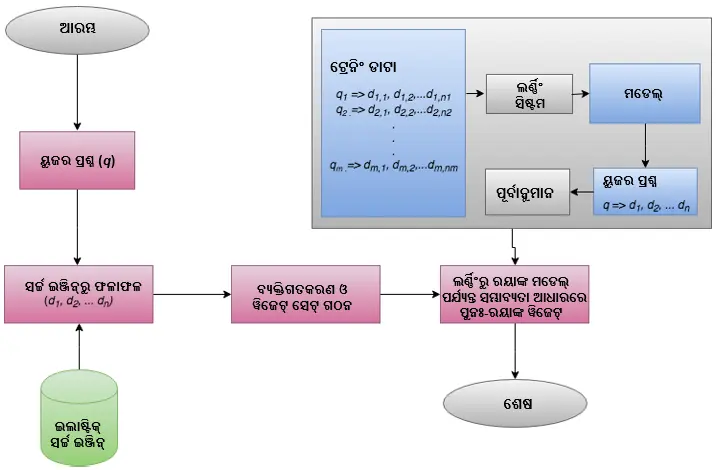
ଯେହେତୁ Embibeରେ ଫଳାଫଳଗୁଡିକ ୱିଜେଟରେ ଗ୍ରୁପ୍ ହୋଇଛି, ଯାହା ପ୍ରଥମ କ୍ରମାଙ୍କ ଫଳାଫଳରୁ ପ୍ରଶ୍ନ ପର୍ଯ୍ୟନ୍ତ ବିସ୍ତାରିତ ହୋଇଛି, ୱିଜେଟରେ ରାକିଙ୍ଗ୍ ଫଙ୍କସନ୍ ପ୍ରୟୋଗ ହେବା ଆବଶ୍ୟକ । ତେଣୁ, ଆମର ବ୍ୟବହାର କ୍ଷେତ୍ରରେ, ପୂର୍ବରୁ ଥିବା ଯେକୌଣସି ସର୍ଚ୍ଚ ଇଞ୍ଜିନ୍ ଯେଉଁଥିରେ ବିଲ୍ଟ-ଇନ୍ ଲର୍ଣ୍ଣିଂ-ଟୁ-ରାଙ୍କ୍ କାର୍ଯ୍ୟକାରିତା ସୁବିଧା ଥାଏ, ଯେପରି ଇଲେଷ୍ଟିକ୍ ସର୍ଚ୍ଚ v6.0 ଅପଓ୍ୱାର୍ଡ, ତାହା ସମାଧାନ ପ୍ରଦାନ କରିବାରେ ସମର୍ଥ ହେବ ନାହିଁ । ଆମର ବ୍ୟକ୍ତିଗତ ସର୍ଚ୍ଚ ଇଞ୍ଜିନ୍ ଯାହା ୟୁଜର୍ ପ୍ରଶ୍ନ ଆଧାରରେ ବିଷୟବସ୍ତୁ ପ୍ରଦାନ କରିଥାଏ, ୟୁଜର୍ କୋହୋର୍ଟ୍ ଆସାଇନମେଣ୍ଟ୍, ପୂର୍ବ ସର୍ଚ୍ଚ ଟ୍ରେଣ୍ଡ, ବିଷୟବସ୍ତୁ ବ୍ୟବହାର ଢାଞ୍ଚା, ପରୀକ୍ଷଣ ଭିତ୍ତିକ ବିଷୟବସ୍ତୁର ଗୁରୁତ୍ୱ ଏବଂ ୟୁଜରମାନଙ୍କ ଅତୀତ ପାରସ୍ପରିକ କାର୍ଯ୍ୟକଳାପ ଆଧାରରେ ପ୍ରଥମ କ୍ରମାଙ୍କ ଫଳାଫଳକୁ ସ୍ଥାନିତ କରେ ।
ସର୍ଚ୍ଚ ଫଳାଫଳ ଉପରେ ୟୁଜରମାନଙ୍କ ପୂର୍ବ କ୍ଲିକ୍ ତଥ୍ୟ ଉପରେ ଆଧାର କରି ଏହି ବ୍ୟବସ୍ଥା ଠିକ୍ ଭାବରେ କାର୍ଯ୍ୟ କରେ, ଏହା ପ୍ରଶ୍ନ-ଆଧାରିତ ୟୁଜର୍ ପାରସ୍ପରିକ କାର୍ଯ୍ୟକଳାପ କିମ୍ବା ପ୍ରଶ୍ନ-ଡକ୍ୟୁମେଣ୍ଟକୁ ଦର୍ଶାଉଥିବା କିମ୍ବା ନିର୍ଦ୍ଦିଷ୍ଟ ଭାବରେ ୟୁଜ୍-କେସ୍ ରେ, ପ୍ରଶ୍ନ-ୱିଜେଟ୍ ଯୋଡିକୁ ଉଚ୍ଚ ଡାଇମେନସନାଲ୍ ସ୍ପେସ୍ ଆଦିକୁ ହିସାବକୁ ନିଏ ନାହିଁ ଏବଂ ୟୁଜର୍ ପ୍ରଶ୍ନଗୁଡ଼ିକର ପ୍ରାସଙ୍ଗିକତାକୁ ଉପସ୍ଥାପନ କରିଥାଏ । ଲର୍ଣ୍ଣିଂ-ଟୁ-ରାଙ୍କ୍ ଢାଞ୍ଚା ଏହି ଅଭାବକୁ ସମାଧାନ କରିଥାଏ ଯାହାକି n-ଡାଇମେନ୍ସନାଲ୍ ସ୍ପେସ୍ ରେ ଏକ ପ୍ରଶ୍ନକୁ ନେଇ ସେଟ୍ ହୋଇଥିବା ଫଳାଫଳକୁ ଦର୍ଶାଇଥାଏ ଏବଂ ସମସ୍ୟାକୁ ଏକ ମେସିନ୍ ଲର୍ଣ୍ଣିଂ ସମସ୍ୟାରେ ପରିଣତ କରି ରେଗ୍ରେସନ୍ କିମ୍ବା ବର୍ଗୀକରଣ କିମ୍ବା ମୂଲ୍ୟାଙ୍କନ ମେଟ୍ରିକ୍ ଅପ୍ଟିମାଇଜ୍ କରି ରାଙ୍କିଂ କରିଥାଏ ।
ସାଧାରଣତଃ, ଲର୍ଣ୍ଣିଂ-ଟୁ-ରାଙ୍କ୍ ଆଲଗୋରିଦମ୍ ଗୁଡ଼ିକ ପ୍ରଶ୍ନ-ଡକ୍ୟୁମେଣ୍ଟ ଯୋଡି କିମ୍ବା ତାଲିକାରେ କାମ କରେ । ଆମ କ୍ଷେତ୍ରରେ, ଯେହେତୁ ପ୍ରତ୍ୟେକ ପ୍ରଶ୍ନ ୱିଜେଟ୍ ପ୍ରକାରର ବିଭିନ୍ନ ସେଟ୍ ସୃଷ୍ଟି କରିବ ଏବଂ ଆମେ ୟୁଜରମାନଙ୍କ ପାଇଁ ରାଙ୍କିଂ ବ୍ୟକ୍ତିଗତ କରିବାକୁ ଚାହିଁବୁ, ତେଣୁ ଆମେ ତିନୋଟି ବର୍ଗର ବୈଶିଷ୍ଟ୍ୟକୁ ବିଚାର କରିଛୁ; ଯଥା ୟୁଜର୍, ପ୍ରଶ୍ନ ଓ ୱିଜେଟ୍ । ୟୁଜର୍ ପ୍ରୋଫାଇଲ୍, ପ୍ରଶ୍ନ ସୂଚନା ଏବଂ ଫଳାଫଳରୁ ଉଦ୍ଧାର ହୋଇଥିବା ଟପ୍ ୱିଜେଟ୍ ଗୁଡିକର ମିଶ୍ରଣରୁ ବୈଶିଷ୍ଟ୍ୟ ବ୍ୟବହାର କରି ଏକ ୟୁଜର୍ ଦ୍ୱାରା ପ୍ରସ୍ତୁତ ପ୍ରତ୍ୟେକ ପ୍ରଶ୍ନ ପାଇଁ ଆମେ ଆମର ତଥ୍ୟକୁ ଦର୍ଶାଇଥାଉ । ୱିଜେଟ୍ ପାଇଁ ବୈଶିଷ୍ଟ୍ୟଗୁଡିକ ୱିଜେଟ୍ ର ପ୍ରକାର, ୱିଜେଟ୍ ଭର୍ଟିକାଲ୍, ବ୍ରାଉଜିଂର ପୂର୍ବ ଲୋକପ୍ରିୟତା, ପ୍ରଶ୍ନ ଶବ୍ଦଗୁଡ଼ିକ ୱିଜେଟ୍ ନାମ ସହିତ ମେଳ ଖାଉଛି କି ନାହିଁ ଆଦି ଅନ୍ତର୍ଭୁକ୍ତ । ପ୍ରଶ୍ନର ବୈଶିଷ୍ଟ୍ୟଗୁଡିକ ନିର୍ଦ୍ଦିଷ୍ଟ ଉଦ୍ଦେଶ୍ୟ ଚିହ୍ନଟ ହୋଇଛି କି ନାହିଁ, ପ୍ରଶ୍ନର ଦୈର୍ଘ୍ୟ, ପ୍ରଶ୍ନର ଟର୍ମ ଫ୍ରିକ୍ୱେନ୍ସି-ଇନଭର୍ସ ଡକ୍ୟୁମେଣ୍ଟ ଫ୍ରିକ୍ୱେନ୍ସି ବୈଶିଷ୍ଟ୍ୟଗୁଡିକ ଏଥିରେ ସାମିଲ ଥାଏ । ୟୁଜର୍ ବ୍ୟକ୍ତିଗତକରଣ କରିବା ଲାଗି ଆମେ ୟୁଜର୍ ବୈଶିଷ୍ଟ୍ୟଗୁଡିକୁ ମଧ୍ୟ ନେଇଥାଉ, ଯେପରି ୟୁଜର୍ ଯୋଗଦାନ କୋହୋର୍ଟ୍, ୟୁଜର୍ କାର୍ଯ୍ୟଦକ୍ଷତା କୋହୋର୍ଟ୍, ୟୁଜର୍ ଙ୍କ ମୂଳ ଲକ୍ଷ୍ୟ ଇତ୍ୟାଦି । ଅନୁସନ୍ଧାନମୂଳକ ତଥ୍ୟ ବିଶ୍ଳେଷଣ, ସମ୍ପର୍କ ସମ୍ବନ୍ଧୀୟ ମାଟ୍ରିକ୍ସ, ପାରସ୍ପରିକ ସୂଚନା ସ୍କୋର୍ [2] ଏବଂ ଡାଇମେନ୍ସନାଲିଟି ହ୍ରାସ ବ୍ୟବହାର କରି ଅନାବଶ୍ୟକ ବୈଶିଷ୍ଟ୍ୟଗୁଡିକୁ ଅପସାରିତ କରାଯାଇଥାଏ ।
ଆମେ ଲର୍ଣ୍ଣିଂ-ଟୁ-ରାଙ୍କ୍ କୁ ପୂର୍ବାନୁମାନ ସମସ୍ୟାରେ ପରିଣତ କରିଛୁ, ଯେଉଁଠାରେ ୟୁଜର୍, ପ୍ରଶ୍ନ ଏବଂ ୱିଜେଟ୍ ବୈଶିଷ୍ଟ୍ୟକୁ ଦୃଷ୍ଟିରେ ରଖି ଏକ ନିର୍ଦ୍ଦିଷ୍ଟ ୱିଜେଟ୍ ରେ ୟୁଜର୍ କ୍ଲିକ୍ ସମ୍ଭାବନାକୁ ଆମେ ପୂର୍ବାନୁମାନ କରିଥାଉ । ୟୁଜର୍ ପ୍ରଶ୍ନର ରେକର୍ଡ ଏବଂ ପରବର୍ତ୍ତୀ କ୍ଲିକ୍ ଇଣ୍ଟରାକସନ୍ ଡାଟା ବ୍ୟବହାର କରି, କ୍ଲିକ୍ ସ୍ଥାନରେ ଓ ଉପରେ ୱିଜେଟ୍ ଗୁଡିକୁ ବିଚାର କରିଥାଉ । ଏହା ଆମକୁ ଅତୀତରେ ସେଟ୍ ହୋଇଥିବା ତଥ୍ୟର ଏକ ଅପେକ୍ଷାକୃତ ସନ୍ତୁଳିତ ବଣ୍ଟନ ପ୍ରଦାନ କରିଥାଏ, ୟୁଜର୍ ମାନେ ହାୟର୍ ଅପ୍ ୱିଜେଟ୍ ଉପରେ କ୍ଲିକ୍ କରିବାକୁ ଲାଗନ୍ତି । ବର୍ଗୀକରଣ ଆଲଗୋରିଦମ୍ ବ୍ୟବହାର କରି ଆମେ ଏକ ୱିଜେଟ୍ ଉପରେ କ୍ଲିକ୍ କରିବାର ସମ୍ଭାବନାକୁ ପୂର୍ବାନୁମାନ କରିପାରିବା ଏବଂ ଏହି ଉପାୟଟି ଏକ ଭଲ ବେସ୍ ଲାଇନ୍ ପ୍ରଦାନ କରିଥାଏ, ଯେଉଁଠାରେ ଫଳାଫଳଗୁଡିକ ପୁନରାବୃତ୍ତି ପାଇଁ ସହଜରେ ବ୍ୟାଖ୍ୟା କରାଯାଇପାରେ । ତେଣୁ, ଆମେ ଏହି ଉପାୟ ପାଇଁ ଆମର ପ୍ରଥମ ପସନ୍ଦ ଭାବରେ ଲଜିଷ୍ଟିକ୍ ରିଗ୍ରେସନ୍ [3]କୁ ବାଛିଲୁ ।
ଆମ ପରୀକ୍ଷଣ ପାଇଁ କାର୍ଯ୍ୟଟି ଥିଲା ଏକ ନିର୍ଦ୍ଦିଷ୍ଟ ସ୍ଥିତିରେ ଏକ ୱିଜେଟ୍ ୟୁଜର୍ ଓ ପ୍ରଶ୍ନର କିଛି ମିଶ୍ରଣ ପାଇଁ କ୍ଲିକ୍ ହେବ କି ନାହିଁ ତାହା ପୂର୍ବାନୁମାନ କରିବା । ଆମେ କେବଳ ସାଂଖ୍ୟିକ ବୈଶିଷ୍ଟ୍ୟ ବ୍ୟବହାର କରି ଆରମ୍ଭ କରିଥିଲୁ ଯେପରିକି ଲୋକପ୍ରିୟତା ବ୍ରାଉଜ୍, ପରୀକ୍ଷା ଗୁରୁତ୍ୱ, ପ୍ରଶ୍ନ ଦୈର୍ଘ୍ୟ ଇତ୍ୟାଦି ଏବଂ ଏହାକୁ ବେସ୍ ଲାଇନ୍ କାର୍ଯ୍ୟଦକ୍ଷତା ଭାବରେ ବ୍ୟବହାର କରିଥାଉ । ବର୍ଦ୍ଧିତ ବୈଶିଷ୍ଟ୍ୟ ସେଟ୍ ରେ ୱିଜେଟ୍ ପ୍ରକାର, ୟୁଜର୍ କୋହୋର୍ଟ୍, ପ୍ରଶ୍ନ ଲକ୍ଷ୍ୟ ଇତ୍ୟାଦି ପରି ବର୍ଗୀକୃତ ତଥ୍ୟ ଯୋଡିବା ଦ୍ୱାରା କ୍ଲିକ୍ ପୂର୍ବାନୁମାନ କାର୍ଯ୍ୟରେ ଉଭୟ ସଠିକତା ଓ ସଠିକତା ମଧ୍ୟରେ ~6% ଉନ୍ନତି ଘଟିଲା । ତାପରେ ଆମେ ଜିଜ୍ଞାସାଗୁଡ଼ିକରୁ ବାହାର କରାଯାଇଥିବା ଶ୍ରେଷ୍ଠ 1,500 TF-IDF ବୈଶିଷ୍ଟ୍ୟଗୁଡିକୁ ଯୋଡିଥିଲୁ ଏବଂ ଏହା ମଡେଲର ସଠିକତାକୁ ~1% ଉନ୍ନତ କରି ସୂଚାଇ ଦେଇଥାଏ ଯେ ଉନ୍ନତ କାର୍ଯ୍ୟଦକ୍ଷତା ପାଇଁ ଅନ୍ୟ ପାଠ୍ୟ ବୈଶିଷ୍ଟ୍ୟଗୁଡିକ ବାହାର କରିବାକୁ ପଡିବ । Embibeର ବ୍ୟକ୍ତିଗତ ବିଷୟବସ୍ତୁ ଡିସ୍କୋଭରି ଇଞ୍ଜିନ୍ ପାଇଁ ଲର୍ଣ୍ଣିଂ-ଟୁ-ରାଙ୍କ୍ ଉପରେ ଅଧିକ ଅନୁସନ୍ଧାନ ପୁନରାବୃତ୍ତି ପାଇଁ ଏହି ପଦ୍ଧତିର କାର୍ଯ୍ୟଦକ୍ଷତା ଏକ ଆଧାର ଭାବରେ ବ୍ୟବହୃତ ହେବ ।
ସନ୍ଦର୍ଭ:
- Liu T., “Learning to rank for information retrieval.”, Foundations and Trends® in Information Retrieval 3.3 (2009): 225-331.
- Kraskov A., Stögbauer K. and Grassberger P., “Estimating mutual information.”, Physical review E 69.6 (2004): 066138
- Cox D. R., “The regression analysis of binary sequences.”, Journal of the Royal Statistical Society. Series B (Methodological) (1958): 215-242.




















